论文阅读笔记(十一)【ICCV2017】:Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
Introduction
(1)Motivation:
当前采用CNN-RNN模型解决行人重识别问题仅仅提取单一视频序列的特征表示,而没有把视频序列匹配间的影响考虑在内,即在比较不同人的时候,根据不同的行人关注不同的部位,如下图:

(2)Contribution:
将注意力模型考虑进行人重识别中,提出了时空联合注意力池化网络(jointly Attentive Spatial-Temporal Pooling Networks,ASTPN).
The Proposed Model Architecture
(1)简述:
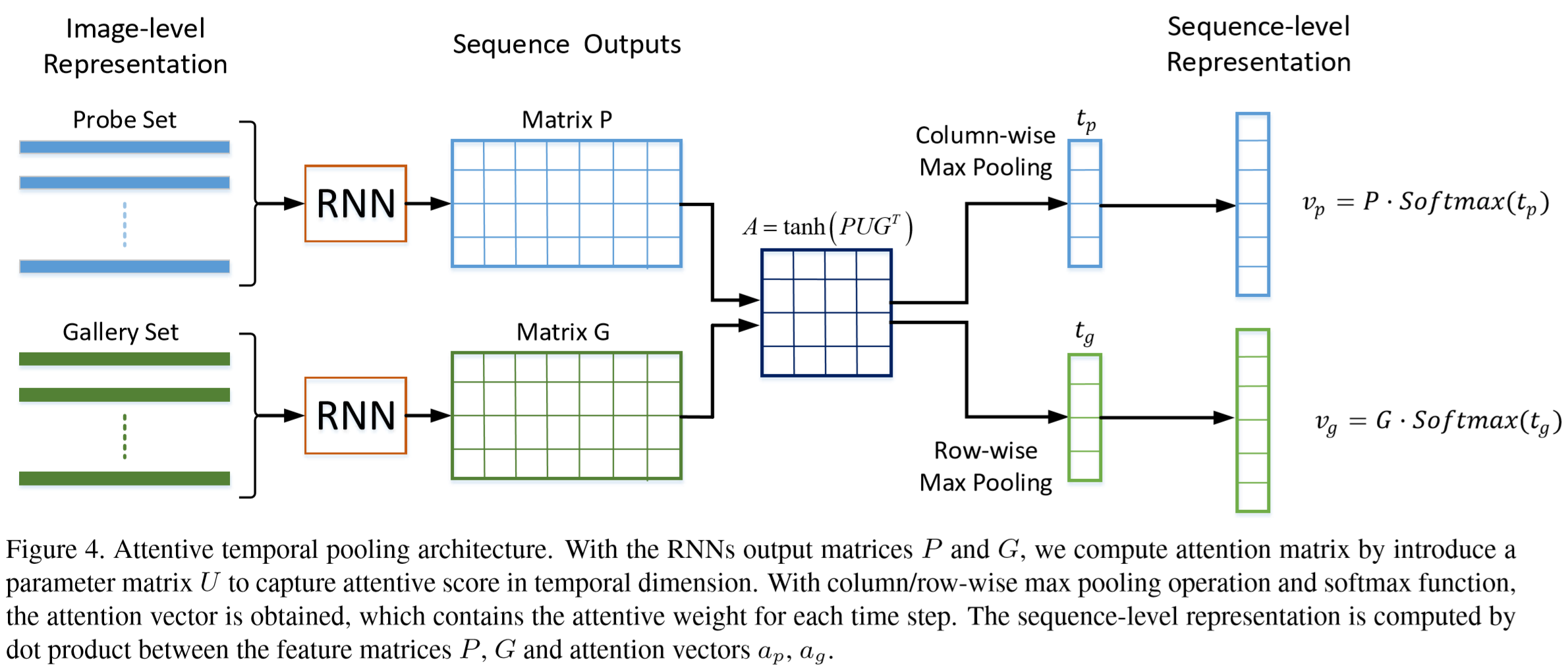
建立了时空注意力网络(a recurrent-convolutional network with jointly attentive spatial-temporal pooling,ASTPN),其工作原理是:将一对视频序列传入孪生神经网络,获得两者的特征表示,并生成它们的欧几里德距离。如图所示,每个输入(包含光流的视频帧)通过CNN网络,并从最后一个卷积层中提取出特征映射。然后将这些特征映射输入到空间池层中,每一个时间步获得一个图像表示。然后,我们把时间信息考虑在内,利用循环神经网络生成视频序列的特征集。最后,由循环神经网络产生的所有时间步被注意力时间池结合起来,形成序列特征表示。
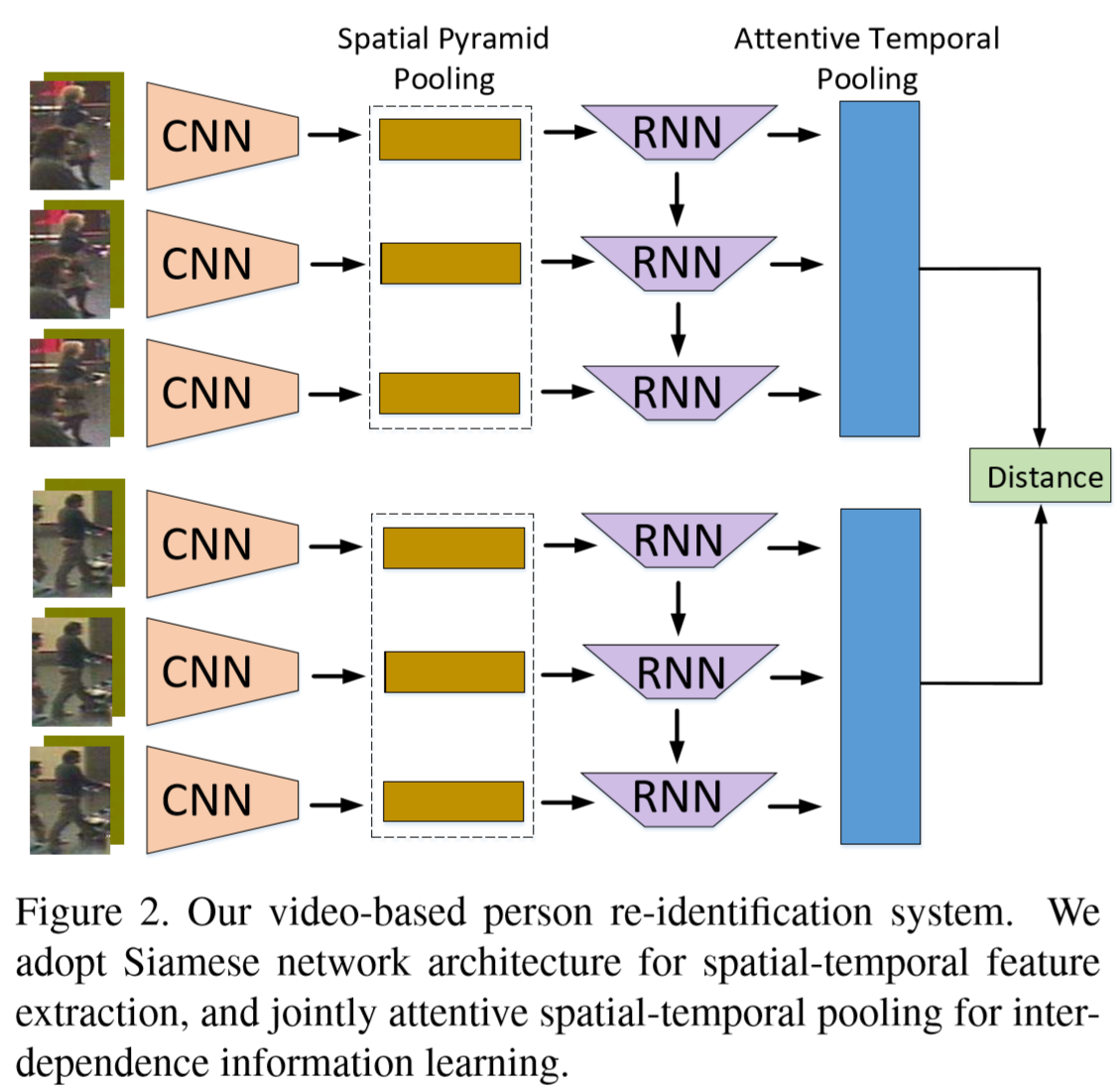
(2)卷积层:
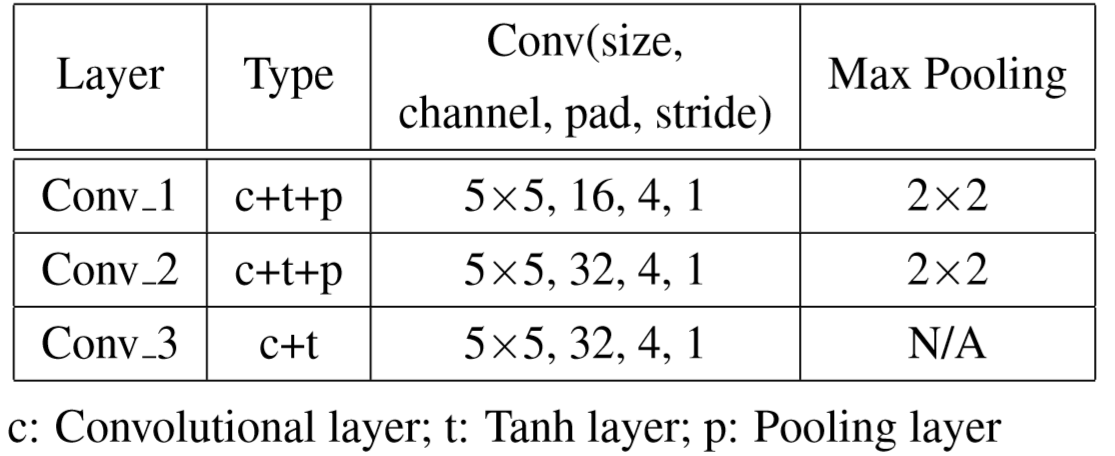
输入:网络的输入由三个彩色通道和两个光流组成。颜色通道提供服装和背景等空间信息,而光流通道提供时间运动信息。给定输入序列 v = {v1, …, vT},我们利用下表所示的卷积网络获得特征映射集 C = {C1,…,CT}。然后将每个 Ci∈Rc×w×h 输入空间池化层,得到图像级表示 ri。
(3)空间池化层(Spatial Pooling Layer):
使用空间金字塔池化(SPP)层来组成空间注意力池,具体如下:
假设池化核大小集为{(mwj, mhj)| j = 1, …, n},则确定第 j 个池化核窗口大小:
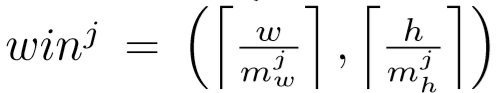
第 j 个池化步长为:
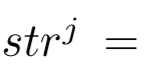

然后通过公式得到结果向量 ri:
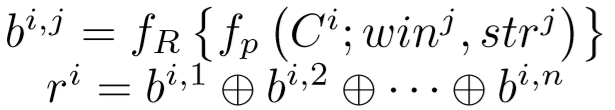
其中 fp 表示采用窗口大小 win 和步长 str 的最大池化函数。fR 表示重构函数,将矩阵重构成一个向量。除此之外,⊕ 表示向量连接操作。
令一个序列表示为r = {ri∈RL | i = 1, …, T},其中: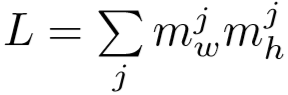 。
。

(4)注意力时间池化层(Attentive Temporal Pooling Layer)
将上一层得到的 r 输入到循环神经网络提取时间步信息,循环层可以计算表示为:
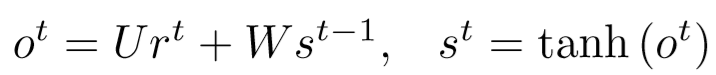
其中 st-1∈RN 是包含上一时间步信息的隐藏层结点,ot 是时间t的输出。全连接权重 U∈RL*N 将循环层输入 rt 从 RL 映射到 RN,全连接权重 W∈RN*N 将隐藏层结点 st-1 从 RN 映射到 RN 。注意到循环层通过矩阵U将特征向量嵌入到低维特征中。在第一个时间步中,隐藏层结点被初始化为0,隐藏层通过tanh函数激活传递。
定义矩阵 P∈RT*N 和 G∈RT*N,其第 i 行分别表示检测数据和对照数据在循环网络的第 i 个时间步的输出,我们计算注意力矩阵 A∈RT*T:
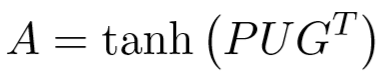
其中 U∈RN*N 是网络学习的信息分享感知矩阵。
之后,对 A 分别应用列最大池化和行最大池化来获得时间权重向量 tp∈RT 和 tg∈RT。tp 的第 i 个元素表示探测序列中第 i 帧的重要得分,tg 同理。再对时间权重向量 tp 和 tg 应用softmax函数,来生成注意力向量 ap∈RT 和 ag∈RT。ag 的第 i 个元素可以计算为:
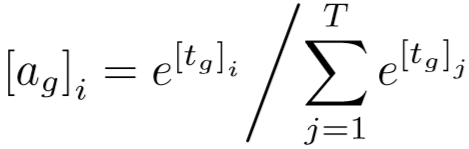
最后,应用 P、G 和 ap、ag 之间的点乘来获得序列级表示 vp∈RN 和 vg∈RN,分别计算为:
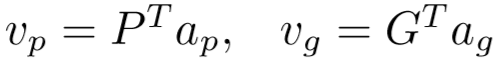
(5)损失函数:思想与上篇论文类似【传送门】
孪生神经网络的铰链损失:
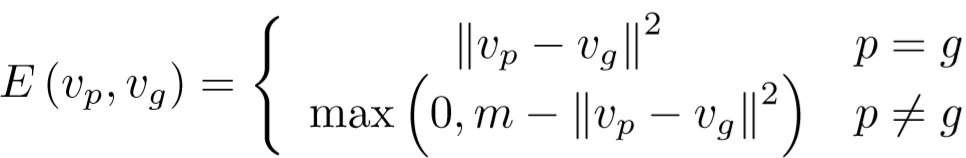
将识别身份的损失考虑在内,训练目标为:
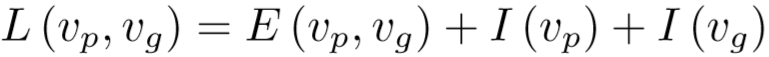
Experimental Results
(1)实验设置:
① 数据集:iLIDS-VID、PRID-2011、MARS
② 参数设置:截取的帧数 k = 18,孪生代价函数的边距 m = 3,特征空间维数为128,初始学习率0.001,批量设置为1.
③ 对比方法:RNN-CNN、RFA、VR、AFDA
(2)预处理:
① 裁剪、镜像来增强数据,裁剪后的子图像的宽度和长度都比原图像小8个像素,在整个序列随机使用镜像操作,概率 p=0.5。
② 将图像精确地转换为YUV颜色空间,并将每个颜色通道归一化为零均值和单位方差;使用Lucas-Kanade方法在每对相邻图像之间提取垂直和水平的光流,然后提取光流通道正规化为[-1, 1]
(3)实验结果:
① 与对比方法比较:

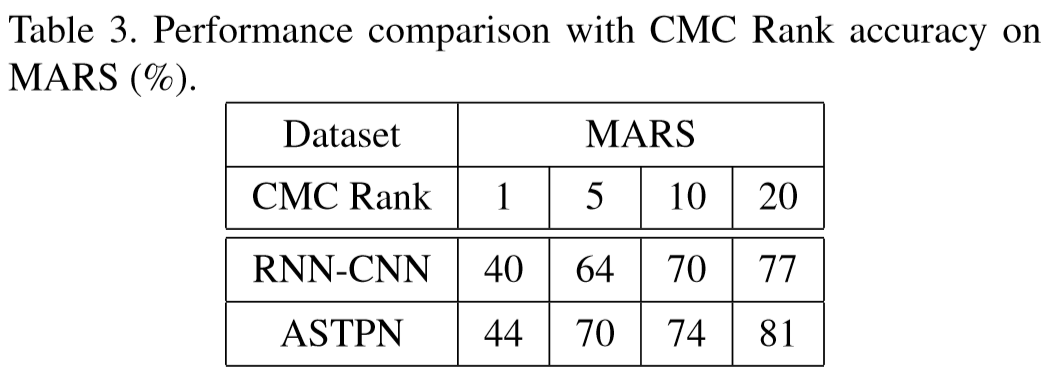
② 在MARS数据集上结果:
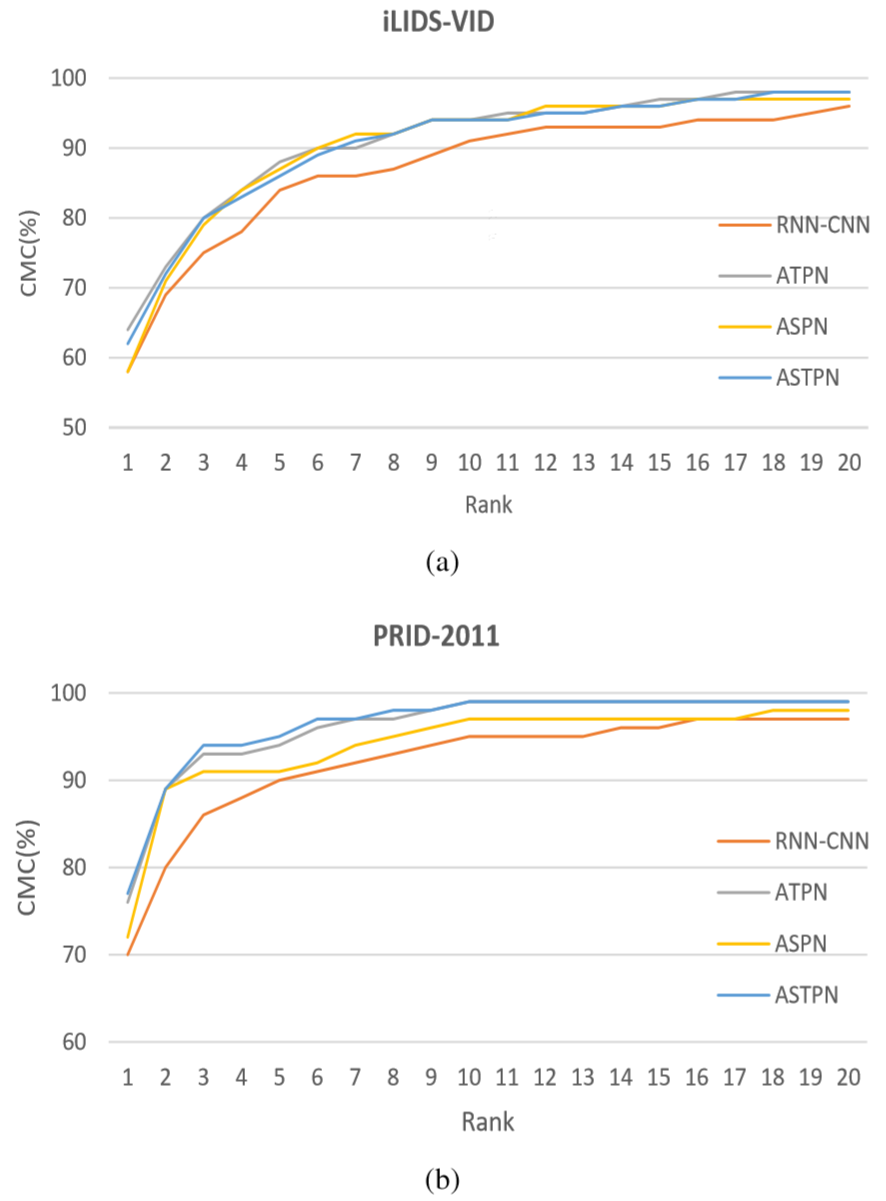
③ 不同池化策略的比较:

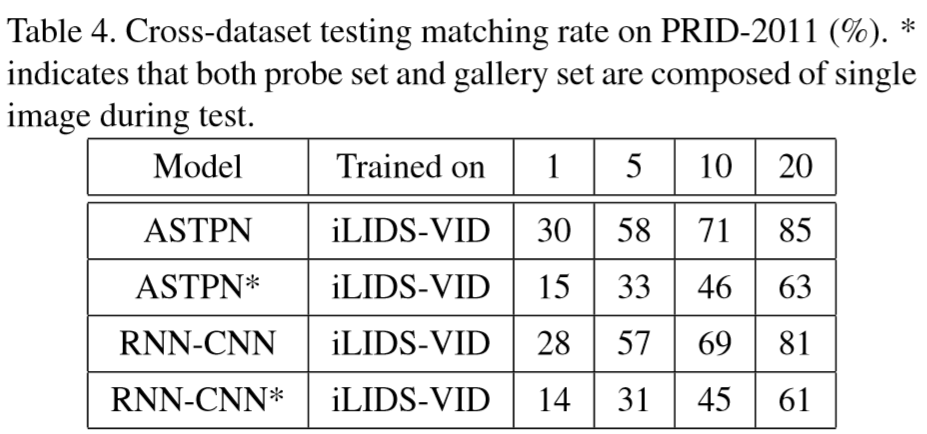
④ 交叉数据集上测试结果:
在ILIDS-VID数据集上进行训练,然后在PRID-2011数据集上进行测试。
论文阅读笔记(十一)【ICCV2017】:Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification的更多相关文章
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记十一:Rethinking Atrous Convolution for Semantic Image Segmentation(DeepLabv3)(CVPR2017)
论文链接:https://blog.csdn.net/qq_34889607/article/details/8053642 摘要 该文重新窥探空洞卷积的神秘,在语义分割领域,空洞卷积是调整卷积核感受 ...
- 论文阅读 A Data-Driven Graph Generative Model for Temporal Interaction Networks
13 A Data-Driven Graph Generative Model for Temporal Interaction Networks link:https://scholar.googl ...
- 论文阅读笔记十七:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(CVPR2017)
论文源址:https://arxiv.org/abs/1611.06612 tensorflow代码:https://github.com/eragonruan/refinenet-image-seg ...
- 论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks
论文概况 Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks是处理比较两个句子相似度的问题, ...
- 论文阅读笔记二-ImageNet Classification with Deep Convolutional Neural Networks
分类的数据大小:1.2million 张,包括1000个类别. 网络结构:60million个参数,650,000个神经元.网络由5层卷积层,其中由最大值池化层和三个1000输出的(与图片的类别数相同 ...
- 论文阅读笔记(十)【CVPR2016】:Recurrent Convolutional Network for Video-based Person Re-Identification
Introduction 该文章首次采用深度学习方法来解决基于视频的行人重识别,创新点:提出了一个新的循环神经网络架构(recurrent DNN architecture),通过使用Siamese网 ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
随机推荐
- MySQL读写分离---Mycat
一.什么是读写分离 在数据库集群架构中,让主库负责处理事务性查询,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能.当然,主数据库另外一个功能就是负责将事务性查询导致的数据变 ...
- jQuery-Moblie在Chrome下出现的问题
第一次用jQuery然后就遇到很蛋疼的地方,打开页面一直处在菊花状态,一开始以为自己搞错什么,是不是引用错文件,看里面的错误警告 Failed to execute 'replaceState' on ...
- ExecutionContext(执行上下文)综述
>>返回<C# 并发编程> 1. 简介 2. 同步异步对比 3. 上下文的捕获和恢复 4. Flowing ExecutionContext vs Using Synchron ...
- 关系模式范式分解教程 3NF与BCNF口诀
https://blog.csdn.net/sumaliqinghua/article/details/86246762 [通俗易懂]关系模式范式分解教程 3NF与BCNF口诀!小白也能看懂原创置顶 ...
- 关于mac下redis的安装和部署
近来学习scrap分布式,需要用到redis,但以前没接触过,所以记录一下自己的安装过程. 准备:Mac,redis-5.0.4.tar.gz 1.压缩包到官网下(建议下载稳定版)网址:redis.i ...
- Android进程调度之adj算法
copy from : http://gityuan.com/2016/08/07/android-adj/ 一.概述 提到进程调度,可能大家首先想到的是Linux cpu调度算法,进程优先级之类概念 ...
- DataX的使用——大数据同步技术
准备工作: 1.视频教学http://113.31.104.47/portal/#/course/dashboard/b34d160db64624732ef152a1118af11a 2.DataX的 ...
- 深入浅出 .NET C# 反射技术
反射这个词听起来就很牛逼是吧? 嗯的确,反射是比较高级的特性,只有语言基础很扎实的Dev们才应该使用它. 搞点反射,可以提高程序的灵活性.可扩展性.耦合度. 反射这东西,是为了动态地运行时加载,相比于 ...
- 2python脚本在window编辑后linux不能执行的问题
参考简书博主天道酬勤abcd python脚本在windows编辑后,在linux下执行提示 /usr/bin/python^M: bad interpreter: No such file or d ...
- python选课系统作业
# 选课系统# 角色:学校.学员.课程.讲师# 要求:# 1. 创建北京.上海 2 所学校# 2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海 ...