Spark学习笔记(二)—— Local模式
Spark 的运行模式有 Local(也称单节点模式),Standalone(集群模式),Spark on Yarn(运行在Yarn上),Mesos以及K8s等常用模式,本文介绍第一种模式。
1、Local模式
Local模式就是运行在一台计算机上的模式, 也称单节点模式 。Local 模式是最简单的一种Spark运行方式,它采用单节点多线程(CPU)方式运行, 通常就是用于在本机学习或者测试使用的,对新手比较友好。它可以通过以下的方式设置Master:
local:所有的计算都运行在一个线程中,没有任何的并行计算。通常我们在学习和测试的时候都是使用这种模式;
local[K]:这种方式可以指定用几个线程来计算,比如local[4],就是指定4个Worker线程。通常我们的CPU有几个Core,就指定介个线程,最大化的利用CPU的计算能力;
local[*]:这种模式直接帮你按照CPU最多Core来设置线程数量了。
2、安装使用
说了那么多,还没见真章。那么接下来开始安装使用一下~~
1)上传并且解压Spark安装包
我使用的是spark-2.1.1-bin-hadoop2.7.tgz
[simon@hadoop102 sorfware]$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
[simon@hadoop102 module]$ mv spark-2.1.1-bin-hadoop2.7 spark
解压完成之后看到目录还是非常清晰的:

2)蒙特卡罗法求PI
这是一个官方小案例,看代码
[simon@hadoop102 spark]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
解析一下上边的语法:
- --master:指定Master的地址,默认为Local
- --class: 你的应用的启动类 (如
org.apache.spark.examples.SparkPi) - --deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client)*
- --conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引号“key=value”
- application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar
- application-arguments: 传给main()方法的参数
- --executor-memory 1G :指定每个executor可用内存为1G
- --total-executor-cores 2 :指定每个executor使用的cup核数为2个
这就是迭代100次的运算结果,运行速度还是非常快的:
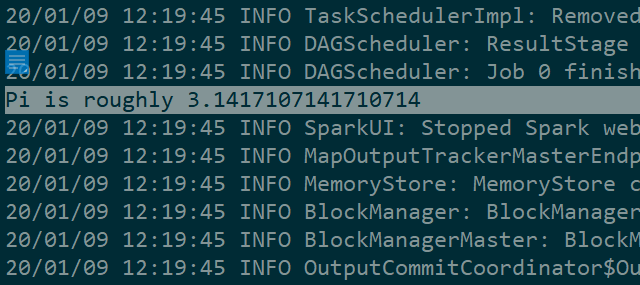
再来一个小的WordCount的小案例演示,同样也是很简单的。
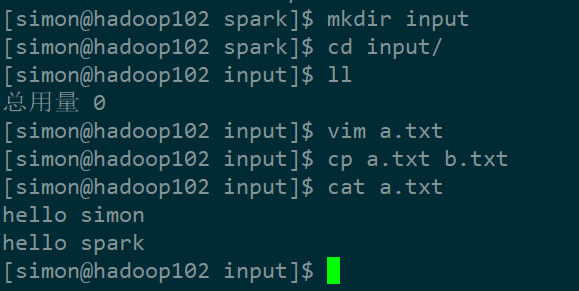
1)创建待输入的文件
[simon@hadoop102 spark]$ mkdir input
#创建a.txt和b.txt,填写如下内容:
hello simon
hello spark
我创建的过程和编写的文件内容如下:
2)启动spark-shell
[simon@hadoop102 spark]$ bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
....
#会打印一堆的启动日志信息
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
在启动日志中可以看到这么三行:

解释一下这三个东西:
- Web UI : 可以在web页面看到Spark集群的信息;
- Spark context ..sc:可以理解为
sc是Spark Core的程序入口; - Spark session ..spark:可以理解为
spark是Spark SQL程序的入口。
之后会用到,到时候再详细解释~~~
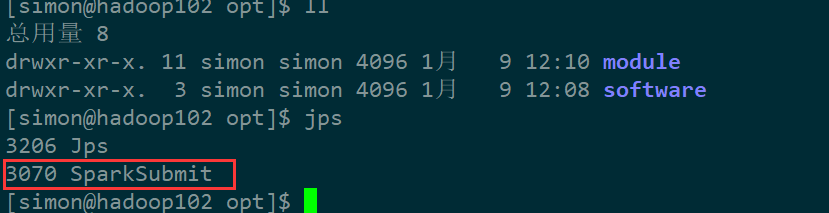
再起一个窗口,执行jps可以看到启动了SparkSubmit进程,这样就算是启动成功了~~
3)运行WordCount程序
sc.textFile("./input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
看运行结果,nice ~~

后边我们会解释这些代码的含义。
可登录hadoop102:4040查看程序运行,整个流程还是非常清晰的:
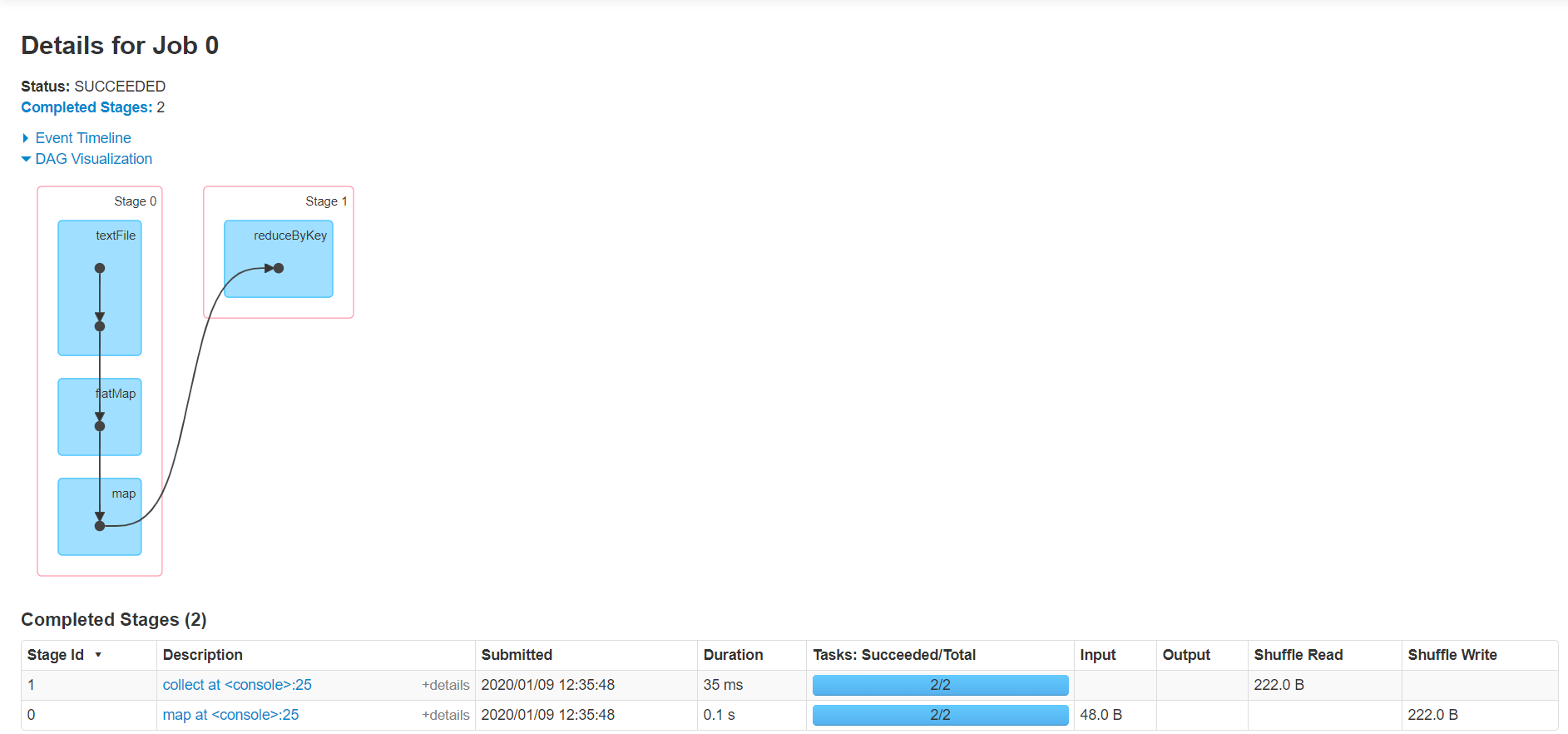
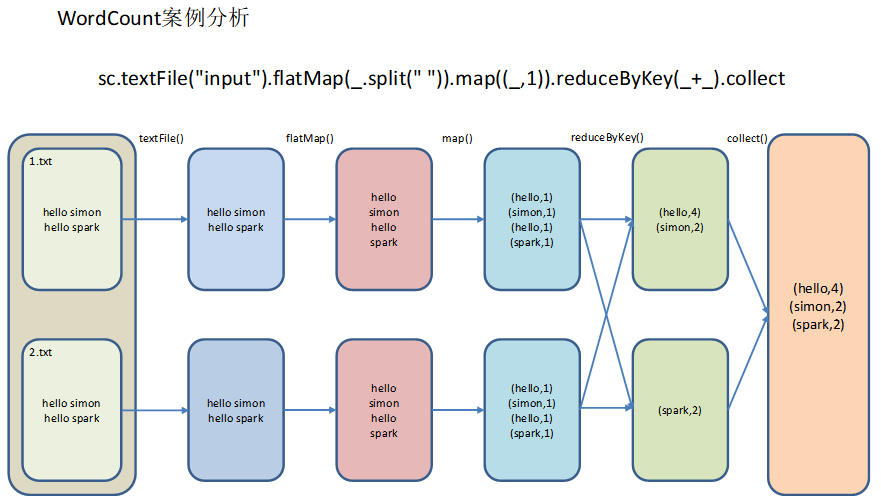
3、分析WordCount流程
直接看个图吧:

那我们回过头来解释一下代码吧,有scala语言基础的话,看起来还不是太难:
- textFile("input"):读取本地文件input文件夹数据;
- flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
- map((__,1)):对每一个元素操作,将单词映射为元组;
- reduceByKey(+):按照key将值进行聚合,相加;
- collect:将数据收集到Driver端展示。
我这样语言组织起来比较费劲,先留个坑,过段时间回过头来再补充流程分析。
文件是怎么被读出、被分割、被统计展示的呢?还是看图吧,等我组织好语言回来补充:
参考资料:
[1]李海波. 大数据技术之Spark
Spark学习笔记(二)—— Local模式的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- 学习笔记(二)--->《Java 8编程官方参考教程(第9版).pdf》:第七章到九章学习笔记
注:本文声明事项. 本博文整理者:刘军 本博文出自于: <Java8 编程官方参考教程>一书 声明:1:转载请标注出处.本文不得作为商业活动.若有违本之,则本人不负法律责任.违法者自负一切 ...
- ES6学习笔记<二>arrow functions 箭头函数、template string、destructuring
接着上一篇的说. arrow functions 箭头函数 => 更便捷的函数声明 document.getElementById("click_1").onclick = ...
- muduo学习笔记(二)Reactor关键结构
目录 muduo学习笔记(二)Reactor关键结构 Reactor简述 什么是Reactor Reactor模型的优缺点 poll简述 poll使用样例 muduo Reactor关键结构 Chan ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
- python3.4学习笔记(二十三) Python调用淘宝IP库获取IP归属地返回省市运营商实例代码
python3.4学习笔记(二十三) Python调用淘宝IP库获取IP归属地返回省市运营商实例代码 淘宝IP地址库 http://ip.taobao.com/目前提供的服务包括:1. 根据用户提供的 ...
- kvm虚拟化学习笔记(二)之linux kvm虚拟机安装
KVM虚拟化学习笔记系列文章列表----------------------------------------kvm虚拟化学习笔记(一)之kvm虚拟化环境安装http://koumm.blog.51 ...
- Linux学习笔记(二) 文件管理
了解 Linux 系统基本的文件管理命令可以帮助我们更好的使用 Linux 系统,以下介绍几个常用的文件管理命令 1.pwd pwd 是 Print Working Directory 的简写,用于显 ...
- amazeui学习笔记二(进阶开发4)--JavaScript规范Rules
amazeui学习笔记二(进阶开发4)--JavaScript规范Rules 一.总结 1.注释规范总原则: As short as possible(如无必要,勿增注释):尽量提高代码本身的清晰性. ...
随机推荐
- input标签前台实现文件上传
值得注意的是:当一个表单里面包含这个上传元素的时候,表单的enctype必须指定为multipart/form-data,method必须指定为post,浏览器才会认识并正确执行.但是还有一点,浏览器 ...
- angular input框点击别处 变成不可输入状态
<input type="text" ng-model="edit" ng-disabled="!editable" focus-me ...
- 我爱自然语言处理bert ner chinese
BERT相关论文.文章和代码资源汇总 4条回复 BERT最近太火,蹭个热点,整理一下相关的资源,包括Paper, 代码和文章解读. 1.Google官方: 1) BERT: Pre-training ...
- H3C 传输层
- jq实现简单购物车增删功能
https://www.cnblogs.com/sandraryan/ jq实现购物车功能 点击+- 增减数量,计算价格: 点击删除,删除当前行(商品) 点击- ,减到0 询问是否删除商品 点击全选 ...
- 用winrar和zip命令拷贝目录结构
linux系统下使用zip命令 zip -r source.zip source -x *.php -x *.html # 压缩source目录,排除里面的php和html文件 windows系统下使 ...
- Python--day42--mysql数据库--mysql前言
- UVA 11922 Permutation Transformer —— splay伸展树
题意:根据m条指令改变排列1 2 3 4 … n ,每条指令(a, b)表示取出第a~b个元素,反转后添加到排列尾部 分析:用一个可分裂合并的序列来表示整个序列,截取一段可以用两次分裂一次合并实现,粘 ...
- python基础十一之迭代器和生成器
可迭代 内置方法中含有__iter__的数据类型都是可迭代的,只要是可迭代的就可以使用for循环,反之亦然. print(dir('')) # dir()函数可以获取当前数据类型的所有内置方法 返回值 ...
- python基础四之列表
列表详解 列表的增删改查! 增加 li = ['zxc', 'is', 'a'] # append 在列表结尾整体添加 修改列表,但是没有返回值 li.append('boy') print(li) ...