Python操作rabbitmq系列(一)
从本文开始,接下来的内容,我们将讨论rabbitmq的相关功能。我的这些文章,最终是要实现一个项目(具体是什么暂不透露)。前面每一篇,都是在为这个系统做准备。rabbitmq,是我们这个项目的关键部分之一。所以牛小妹,这个系列,请务必搞懂rabbitmq是怎么回事,并知道,该如何操作。
在这一篇文章里,我们知道rabbitmq简单逻辑即可。
生产消息:
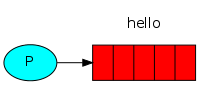
消费消息:
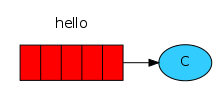
就跟QQ一样,我在这边发,并不是直接发给你,而是发给了中间的服务器,你接收也不直接从我这里接,从服务器去取。
上图红色部分,就是队列,队列就是用来缓冲消息的。这样,我们双边不断发消息,就不会让自己受阻。
在开始编码实践之前。我们需要安装rabbitmq server和python client。
安装rabbitmq server参考文章
安装python client:使用pip install pika
安装完后,我们就可以尝试官方文档的demo:
发送端:
import pika
#连接队列服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
#创建队列。有就不管,没有就自动创建
channel.queue_declare(queue='hello')
#使用默认的交换机发送消息。exchange为空就使用默认的
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
服务器收到的消息效果如图:
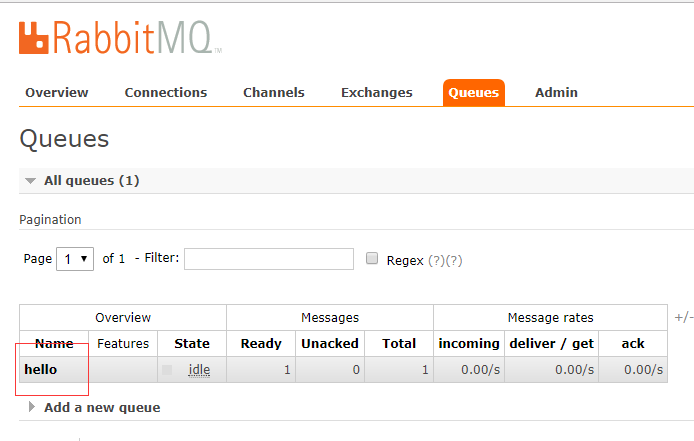
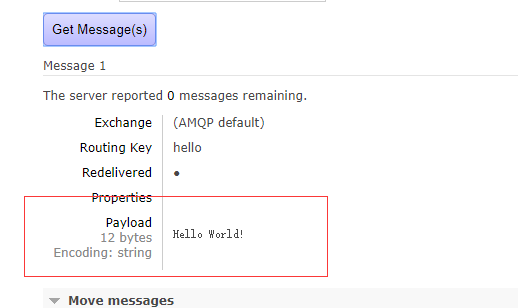
客户端消费消息:
import pika
# 连接服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# rabbitmq消费端仍然使用此方法创建队列。这样做的意思是:若是没有就创建。和发送端道理道理。目的是为了保证队列一定会有
channel.queue_declare(queue='hello')
# 收到消息后的回调
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback, queue='hello', no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
收到的消息:
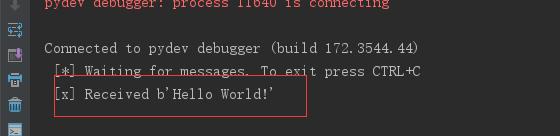
然后回头看服务器管理台:
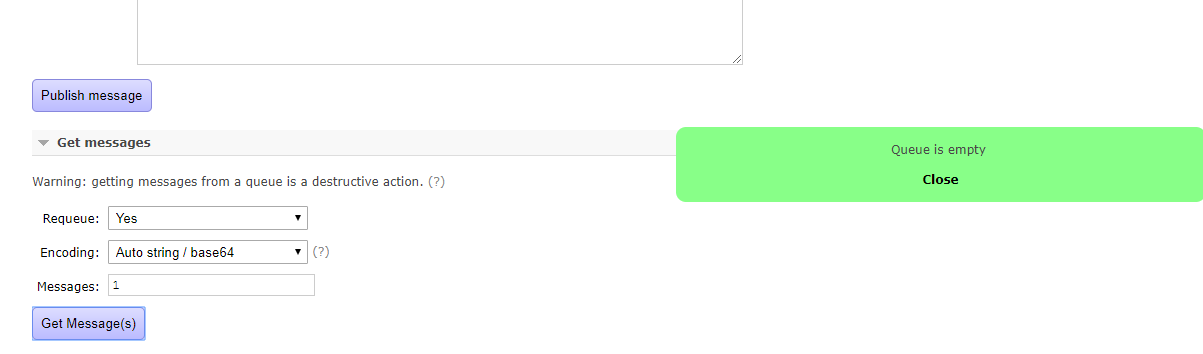
消息被消费后,队列就相应的移除。
今天,我们就对rabbitmq入门以下即可。在下一章,我们将讨论用于在多个工作人员之间分配耗时的任务。这个在并发比较高的web应用中尤为有用。
备注:代码来源于官方文档。因为是英文,专业性较强,有些同学看起吃力,这里就我司的实际运用后的理解,重新阐述一遍,希望它更容易学习。
Python操作rabbitmq系列(一)的更多相关文章
- Python操作rabbitmq系列(六):进行RPC调用
此刻,我们已经进入第6章,是官方的最后一个环节,但是,并非本系列的最后一个环节.因为在实战中还有一些经验教训,并没体现出来.由于马上要给同事没培训celery了.我也来不及写太多.等后面,我们再慢慢补 ...
- Python操作rabbitmq系列(五):根据主题分配消息
接着上一章,使用exchange_type='direct'进行消息传递.这样消息会完全匹配后发送到对应的接收端.现在我们想干这样一件事: C1获取消息中包含:orange内容的消息,并且消息是由3个 ...
- Python操作rabbitmq系列(二):多个接收端消费消息
今天,我们要逐步开始讨论rabbitmq稍微高级点的耍法了.了解这一步,对我们设计高并发的系统非常有用.当然,还可以使用kafka.不过还是算了,有几个硬性条件不支持,还是用rabbitmq吧. 循环 ...
- Python操作rabbitmq系列(四):根据类型订阅消息
在上一章中,所有的接收端获取的所有的消息.这一章,我们将讨论,一些消息,仍然发送给所有接收端.其中,某个接收端,只对其中某些消息感兴趣,它只想接收这一部分消息.如下图:C1,只对error感兴趣,C2 ...
- Python操作rabbitmq系列(三):多个接收端消费消息
接着上一章.这一章,我们要将同一个消息发给多个客户端.这就是发布订阅模式.直接看代码: 发送端: import pikaimport sys connection = pika.BlockingCon ...
- Python操作RabbitMQ
RabbitMQ介绍 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从“生产者”接收消息并传递消 ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- python - 操作RabbitMQ
python - 操作RabbitMQ 介绍 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议.MQ全称为Mess ...
- 文成小盆友python-num12 Redis发布与订阅补充,python操作rabbitMQ
本篇主要内容: redis发布与订阅补充 python操作rabbitMQ 一,redis 发布与订阅补充 如下一个简单的监控模型,通过这个模式所有的收听者都能收听到一份数据. 用代码来实现一个red ...
随机推荐
- Python深度学习 deep learning with Python
内容简介 本书由Keras之父.现任Google人工智能研究员的弗朗索瓦•肖莱(François Chollet)执笔,详尽介绍了用Python和Keras进行深度学习的探索实践,涉及计算机视觉.自然 ...
- 多个文件名大小写不同,是因为运行代码是大写E,用vscode运行的是小写e,解决方案:手动npm run dev #There are multiple modules with names that only differ in casing.
多个文件名大小写不同,是因为运行代码是大写E,用vscode运行的是小写e,解决方案:手动npm run dev #There are multiple modules with names that ...
- JavaScript每日学习日记(1)
8.11.2019 1. lastIndexOf() 方法从尾到头进行检索. 2. 有三种提取部分字符串的方法: 2.1 slice(start, end) 如果某个参数为负,则从字符串的结尾开始计 ...
- npm和yarn使用
npm和yarn使用 他们都属于js包管理工具,都可以安装包或者模块yarn 是由facebook.google等联合开发推出的 区别: npm 下载包的话 比如npm install,它是按照包的排 ...
- python turtle笔记
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它 ...
- Linux---使用kill杀不掉进程解决方案
今天打开Linux虚拟机,然后使用jps命令查看,莫名奇妙多了一个1889进程 然后使用kill杀掉后,再运行jps还是存在此进程.于是乎开始大量百度,最终找到了解决方案. 说的很清楚了,杀不掉的原因 ...
- JDK环境的配置,及运用
JAVA为什么可以跨平台 1.JDK配置环境变量 步骤:打开控制面板中系统和安全------系统-----找到高级系统设置点击属性------高级----环境变量------系统变量(JAVA_HOM ...
- python 清空list的几种方法
本文介绍清空list的四种方法,以及 list=[ ] 和 list.clear() 在使用中的区别(坑). 1.使用clear()方法 lists = [1, 2, 1, 1, 5] lists.c ...
- 洛谷2212Watering the Fields S 最小生成树
题目链接:https://www.luogu.com.cn/problem/P2212 几乎是Kruskal裸题,但是建n*(n-1)条边给我T了俩点,后来我发现只要C(n,2)条边就可以,因为假设( ...
- 表格的删除与添加以及id的唯一性
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http ...