drf框架的解析模块-异常处理模块-响应模块-序列化模块
解析模块
为什么要配置解析模块
(1)、drf给我们通过了多种解析数据包方式的解析类。
(2)、我们可以通过配置来控制前台提交的那些格式的数据台解析,那些数据不解析。
(3)、全局配置就是针对一个视图类,局部配置就是针对指定的视图来,让我们可以按照选择性的解析数据。
源码入口
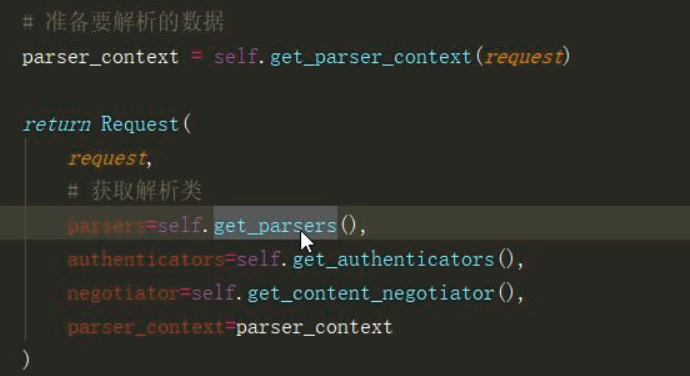
# APIView 类的disp方法中
request = self.initialize_request(request,*args,**kwargs) #点进去 # 获取解析类 parsers=self..get_parsers() #点进去 # 去类属性(局部配置)或配置文件(全局配置)拿 parser_classes return [parser() for parser in self.parser_classes]
全局配置:项目settings.py文件
REST_FRAMEWORK = {
# 全局解析类配置
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser', # json数据包
'rest_framework.parsers.FormParser', # urlencoding数据包
'rest_framework.parsers.MultiPartParser' # form-date数据包
],
}
局部配置:应用views.py的具体视图类
from rest_framwork.parsers import JSONParser class Book(APIView):
# 局部解析类配置,只要json;类型的数据包才能被解析
parser_classes = [JASONParser]
pass
从源码中解析获取的全局配置

from rest_framework.views import APIView
from rest_framework.response import Response from rest_framework.parsers import JSONParser from . import models, serializers
class Book(APIView):
# 局部解析类配置
parser_classes = [JSONParser]
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
book_obj = models.Book.objects.get(pk=pk)
return Response({
'status': 0,
'msg': 'ok',
'results': {
'title': book_obj.title,
'price': book_obj.price
}
})
return Response('get ok') def post(self, request, *args, **kwargs):
# url拼接参数:只有一种传参方式就是拼接参数
print(request.query_params)
# 数据包参数:有三种传承方式,form-data、urlencoding、json
print(request.data)
return Response('post ok')
异常模块
为什么要自定义异常模块
(1)、所有经过drf的APIView视图类产生的异常,都可以提供异常处理方案
(2)、drf 默认提供了异常处理方案(ref_framework.views.exception_handler),但是处理范围有限
(3)、drf提供的处理方案有两种,处理了返回异常现象,没处理返回None(后续就是服务器抛异常给前台)
(4)、自定义异常的目的就是解决drf没有处理的异常,让前台得到合理的异常信息返回,后台记录异常具体信息
源码分析
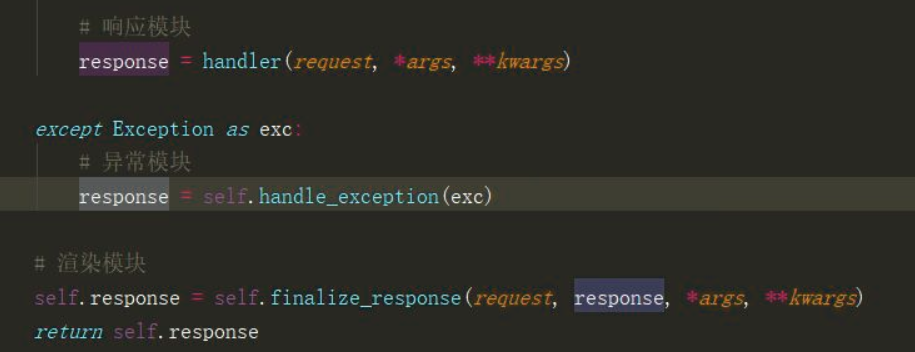
# 异常模块:APIView类的dispatch方法中
response = self.handle_exception(exc) # 点进去 # 获取处理异常的句柄(方法)
# 一层层看源码,走的是配置文件,拿到的是rest_framework.views的exception_handler
# 自定义:直接写exception_handler函数,在自己的配置文件配置EXCEPTION_HANDLER指向自己的
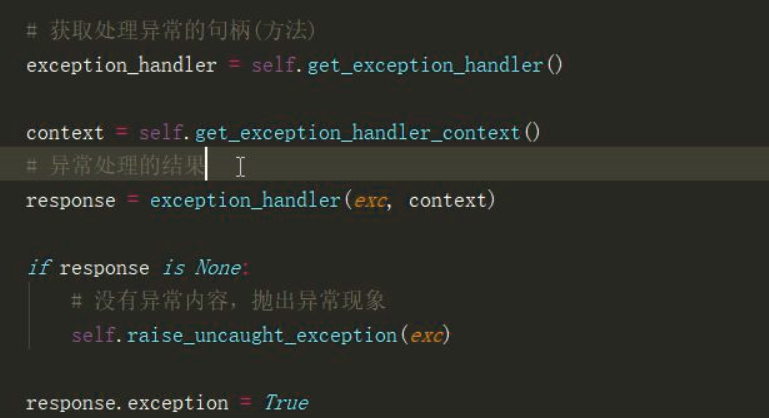
exception_handler = self.get_exception_handler() # 异常处理的结果
# 自定义异常就是提供exception_handler异常处理函数,处理的目的就是让response一定有值
response = exception_handler(exc, context)
如何使用:自定义exception_handler函数如何书写实现体
# 修改自己的配置文件setting.py
REST_FRAMEWORK = {
# 全局配置异常模块
'EXCEPTION_HANDLER': 'api.exception.exception_handler',
}
新建一个excep.py文件,用来处理异常判断
# 1)先将异常处理交给rest_framework.views的exception_handler去处理
# 2)判断处理的结果(返回值)response,有值代表drf已经处理了,None代表需要自己处理 # 自定义异常处理文件exception,在文件中书写exception_handler函数
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework.views import Response
from rest_framework import status
def exception_handler(exc, context):
# drf的exception_handler做基础处理
response = drf_exception_handler(exc, context)
# 为空,自定义二次处理
if response is None:
# print(exc)
# print(context)
print('%s - %s - %s' % (context['view'], context['request'].method, exc))
return Response({
'detail': '服务器错误'
}, status=status.HTTP_500_INTERNAL_SERVER_ERROR, exception=True)
return response
响应模块
响应类构造器:ref_framework.response.Response
def __init__(self, data=None, status=None,
template_name=None, headers=None,
exception=False, content_type=None):
"""
:param data: 响应数据
:param status: http响应状态码
:param template_name: drf也可以渲染页面,渲染的页面模板地址(不用了解)
:param headers: 响应头
:param exception: 是否异常了
:param content_type: 响应的数据格式(一般不用处理,响应头中带了,且默认是json)
""" pass
使用:常规实例化响应对象
# status就是解释一堆 数字 网络状态码的模块 from rest_framework import status就是解释一堆 数字 网络状态码的模块
# 一般情况下只需要返回数据,status和headers都有默认值
return Response(data={数据}, status=status.HTTP_200_OK, headers={设置的响应头})
序列化组件
知识点:Seralizer(偏底层)、ModelSerialier(重点)、ListModelSerializer(辅助群改)
Seralizer
序列化准备:
.模型层:models.py
class User(models.Model):
SEX_CHOICES = [
[0, '男'],
[1, '女'],
]
name = models.CharField(max_length=64)
pwd = models.CharField(max_length=32)
phone = models.CharField(max_length=11, null=True, default=None)
sex = models.IntegerField(choices=SEX_CHOICES, default=0)
icon = models.ImageField(upload_to='icon', default='icon/default.jpg') class Meta:
db_table = 'old_boy_user'
verbose_name = '用户'
verbose_name_plural = verbose_name def __str__(self):
return '%s' % self.name
.后台管理层:admin.py
from django.contrib import admin
from . import models admin.site.register(models.User)
配置层:settings.py
# 注册rest_framework
INSTALLED_APPS = [
# ...
'rest_framework',
] # 配置数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'day70',
'USER': 'root',
'PASSWORD': ''
}
} # media资源
MEDIA_URL = '/media/' # 后期高级序列化类与视图类,会使用该配置
MEDIA_ROOT = os.path.join(BASE_DIR, 'media') # media资源路径
国际化配置,中文显示

.主路由:项目下urls.py
urlpatterns = [
# ...
url(r'^api/', include('api.urls')), url(r'^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}),
]
子路由:应用下urls.py
urlpatterns = [
url(r'^users/$', views.User.as_view()),
url(r'^users/(?P<pk>.*)/$', views.User.as_view()),
]
源码部分重要的截图
模块源码分析
异常处理源码部分
序列化的使用
序列化层:api/serializers.py
(1)、设置需要返回给前台,那些models类有对应的 字段,不需要返回的就不用设置了。
(2)、设置的方法字段,字段名可以随意,字段值有get_字段 提供,来完成一些需要处理再返回的数据。
# 序列化组件 - 为每一个model类通过一套序列化工具类
# 序列化组件的工作方式与django froms组件非常相似
from rest_framework import serializers, exceptions
from django.conf import settings from . import models class UserSerializer(serializers.Serializer):
name = serializers.CharField()
phone = serializers.CharField()
# 序列化提供给前台的字段个数由后台决定,可以少提供,
# 但是提供的数据库对应的字段,名字一定要与数据库字段相同
# sex = serializers.IntegerField()
# icon = serializers.ImageField() # 自定义序列化属性
# 属性名随意,值由固定的命名规范方法提供:
# get_属性名(self, 参与序列化的model对象)
# 返回值就是自定义序列化属性的值 gender = serializers.SerializerMethodField()
def get_gender(self, obj):
# choice类型的解释型值 get_字段_display() 来访问
return obj.get_sex_display() icon = serializers.SerializerMethodField()
def get_icon(self, obj):
# settings.MEDIA_URL: 自己配置的 /media/,给后面高级序列化与视图类准备的
# obj.icon不能直接作为数据返回,因为内容虽然是字符串,但是类型是ImageFieldFile类型
return '%s%s%s' % (r'http://127.0.0.1:8000', settings.MEDIA_URL, str(obj.icon))
.视图层
(1)、从数据中将要序列化给前台的model对象,或是对一个model对象查询出来
user_obj = models.User.objects.get(pk=pk)或者 user_obj_list = models.User.objects.all()
(2)、 将对象交给序列化处理,产生序列化对象,如果序列化的是多个数据,要设置many=True
user_ser = serializers.UserSerializer(user_obj) 或者
user_ser = serializers.UserSerializer(user_obj_list, many=True)
(3)、序列化 对象.data 就是可以返回给前台的序列化数据
return Response({
'status':0,
'msg':0,
'results:user_ser_data'
})
views.py
class User(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
try:
# 用户对象不能直接作为数据返回给前台
user_obj = models.User.objects.get(pk=pk)
# 序列化一下用户对象
user_ser = serializers.UserSerializer(user_obj)
# print(user_ser, type(user_ser))
return Response({
'status': 0,
'msg': 0,
'results': user_ser.data
})
except:
return Response({
'status': 2,
'msg': '用户不存在',
})
else:
# 用户对象列表(queryset)不能直接作为数据返回给前台
user_obj_list = models.User.objects.all()
# 序列化一下用户对象
user_ser_data = serializers.UserSerializer(user_obj_list, many=True).data
return Response({
'status': 0,
'msg': 0,
'results': user_ser_data
})
反序列使用
.反序列化层:api/serializers.py
总结:
(1)、设置必填与选填序列化字段,设置校验规则。
(2)、为需要额外校验的字段提供局部钩子函数,如果该字段不入库,且不参与全局钩子校验,可以将值取出校验。
(3)、为有联合关系的字段们提供全局钩子函数,如果某些字段不入库,可以将值取出校验。
(4)、重写create方法,完成校验通过的数据入库工作,得到新增的对象
class UserDeserializer(serializers.Serializer):
class UserDeserializer(serializers.Serializer):
# 1) 哪些自动必须反序列化
# 2) 字段都有哪些安全校验
# 3) 哪些字段需要额外提供校验
# 4) 哪些字段间存在联合校验
# 注:反序列化字段都是用来入库的,不会出现自定义方法属性,会出现可以设置校验规则的自定义属性(re_pwd)
name = serializers.CharField(
max_length=64,
min_length=3,
error_messages={
'max_length': '太长',
'min_length': '太短'
}
)
pwd = serializers.CharField()
phone = serializers.CharField(required=False)
sex = serializers.IntegerField(required=False) # 自定义有校验规则的反序列化字段
re_pwd = serializers.CharField(required=True) # 小结:
# name,pwd,re_pwd为必填字段
# phone,sex为选填字段
# 五个字段都必须提供完成的校验规则 # 局部钩子:validate_要校验的字段名(self, 当前要校验字段的值)
# 校验规则:校验通过返回原值,校验失败,抛出异常
def validate_name(self, value):
if 'g' in value.lower(): # 名字中不能出现g
raise exceptions.ValidationError('名字非法,是个鸡贼!')
return value # 全局钩子:validate(self, 系统与局部钩子校验通过的所有数据)
# 校验规则:校验通过返回原值,校验失败,抛出异常
def validate(self, attrs):
pwd = attrs.get('pwd')
re_pwd = attrs.pop('re_pwd')
if pwd != re_pwd:
raise exceptions.ValidationError({'pwd&re_pwd': '两次密码不一致'})
return attrs # 要完成新增,需要自己重写 create 方法
def create(self, validated_data):
# 尽量在所有校验规则完毕之后,数据可以直接入库
return models.User.objects.create(**validated_data)
视图层:views.py
(1)、book_ser = serilizers.UserDeserialzer(data=request_data) # 数据必须赋值data
(2)、book_ser.is_valid() # 结果为通过 | 不通过
(3)、不通过返回 book_ser.errors 给前台。通过book_ser.save() 得到新增的对象,在正常返回
class User(APIView):
# 只考虑单增
def post(self, request, *args, **kwargs):
# 请求数据
request_data = request.data
# 数据是否合法(增加对象需要一个字典数据)
if not isinstance(request_data, dict) or request_data == {}:
return Response({
'status': 1,
'msg': '数据有误',
})
# 数据类型合法,但数据内容不一定合法,需要校验数据,校验(参与反序列化)的数据需要赋值给data
book_ser = serializers.UserDeserializer(data=request_data) # 序列化对象调用is_valid()完成校验,校验失败的失败信息都会被存储在 序列化对象.errors
if book_ser.is_valid():
# 校验通过,完成新增
book_obj = book_ser.save()
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.UserSerializer(book_obj).data
})
else:
# 校验失败
return Response({
'status': 1,
'msg': book_ser.errors,
})
drf框架的解析模块-异常处理模块-响应模块-序列化模块的更多相关文章
- (转)python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
阅读目录 1.1.1导入模块 1.1.2__name__ 1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代 ...
- python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- 常用模块random,time,os,sys,序列化模块
一丶random模块 取随机数的模块 #导入random模块 import random #取随机小数: r = random.random() #取大于零且小于一之间的小数 print(r) #0. ...
- python之模块random,time,os,sys,序列化模块(json,pickle),collection
引入:什么是模块: 一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类型. 1.使用python编写的代码(.py ...
- DRF框架(二)——解析模块(parsers)、异常模块(exception_handler)、响应模块(Response)、三大序列化组件介绍、Serializer组件(序列化与反序列化使用)
解析模块 为什么要配置解析模块 1)drf给我们提供了多种解析数据包方式的解析类 form-data/urlencoded/json 2)我们可以通过配置来控制前台提交的哪些格式的数据后台在解析,哪些 ...
- 第二章、drf框架 - 请求模块 | 渲染模块 解析模块 | 异常模块 | 响应模块 (详细版)
目录 drf框架 - 请求模块 | 渲染模块 解析模块 | 异常模块 | 响应模块 Postman接口工具 drf框架 注册rest_framework drf框架风格 drf请求生命周期 请求模块 ...
- 3) drf 框架生命周期 请求模块 渲染模块 解析模块 自定义异常模块 响应模块(以及二次封装)
一.DRF框架 1.安装 pip3 install djangorestframework 2.drf框架规矩的封装风格 按功能封装,drf下按不同功能不同文件,使用不同功能导入不同文件 from r ...
- drf解析模块,异常模块,响应模块,序列化模块
复习 """ 1.接口:url+请求参数+响应参数 Postman发送接口请求的工具 method: GET url: https://api.map.baidu.com ...
- DRF框架(一)——restful接口规范、基于规范下使用原生django接口查询和增加、原生Django CBV请求生命周期源码分析、drf请求生命周期源码分析、请求模块request、渲染模块render
DRF框架 全称:django-rest framework 知识点 1.接口:什么是接口.restful接口规范 2.CBV生命周期源码 - 基于restful规范下的CBV接口 3.请求组件 ...
随机推荐
- oracle数据库常用操作语句 、创建视图
新增字段:alter table 表名 add (NAME VARCHAR(12), NAME NUMBER(10) );--如果添加单个字段可以不用括号包起来,例如 alter table cust ...
- SpringBoot 系列教程之编程式事务使用姿势介绍篇
SpringBoot 系列教程之编程式事务使用姿势介绍篇 前面介绍的几篇事务的博文,主要是利用@Transactional注解的声明式使用姿势,其好处在于使用简单,侵入性低,可辨识性高(一看就知道使用 ...
- 对python中元类的理解
1. 类也是对象 在大多数编程语言中,类就是一组用来描述如何生成一个对象的代码段.在Python中这一点仍然成立: >>> class ObjectCreator(object): ...
- python 奇淫技巧之自动登录 哔哩哔哩
前言 嘿,各位小伙伴好呀,今天要带来点什么干货呢,就从我的实际开发中来给大家带来一个案例吧,如何自动登录 哔哩哔哩 接到老大通知,让我自动写一个自动登录 哔哩哔哩 的脚本,我当然是二话不说直接开怼,咱 ...
- 进度2_家庭记账本App
今天在昨天的基础上,相继完成了三个页面的布局和显示情况: 新增加的xml文件如下: activity_add.xml: <?xml version="1.0" encodin ...
- “帮你”校园资讯平台app使用体验
该app由我的17级学长学姐编写而成,主要功能失物招领,二手市场,表白墙.该软件目前只是面向本校的各专业学生,为内测版本.该软件的注册流程简单,只需要学号确定身份后即可登陆,并且发布各种信息,或者与丢 ...
- Vue中Js动画 与Velocity.js 多组件多元素 列表过渡
Vue提供我们很多js动画钩子 写在tansition标签内部 入场动画 @before-enter="" 处理函数收到一个参数(e l) el为这个元素 @enter=" ...
- Django2.0——模板渲染(一)
在前面的介绍中我们都是用简单的 django.http.HttpResponse来把内容显示到网页上,本节将讲解如何使用渲染模板的方法来显示内容,即调用精美的HTML页面.模板的创建既可以在项目下创建 ...
- vue多选验证
vue select 多选 验证 <FormItem :prop="'formList.'+index+'.name'" label="姓名" :rule ...
- 86.QuerySet API常用的方法详解:get方法
get方法的查询条件只能有一条数据满足,如果匹配到多条数据都满足,就会报错:如果没有匹配到满足条件的数据,也会报错. 示例代码如下: from django.http import HttpRespo ...