入门大数据---Spark累加器与广播变量
一、简介
在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable):
- 累加器:用来对信息进行聚合,主要用于累计计数等场景;
- 广播变量:主要用于在节点间高效分发大对象。
二、累加器
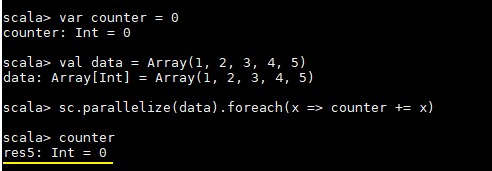
这里先看一个具体的场景,对于正常的累计求和,如果在集群模式中使用下面的代码进行计算,会发现执行结果并非预期:
var counter = 0
val data = Array(1, 2, 3, 4, 5)
sc.parallelize(data).foreach(x => counter += x)
println(counter)
counter 最后的结果是 0,导致这个问题的主要原因是闭包。
2.1 理解闭包
1. Scala 中闭包的概念
这里先介绍一下 Scala 中关于闭包的概念:
var more = 10
val addMore = (x: Int) => x + more
如上函数 addMore 中有两个变量 x 和 more:
- x : 是一个绑定变量 (bound variable),因为其是该函数的入参,在函数的上下文中有明确的定义;
- more : 是一个自由变量 (free variable),因为函数字面量本生并没有给 more 赋予任何含义。
按照定义:在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。
2. Spark 中的闭包
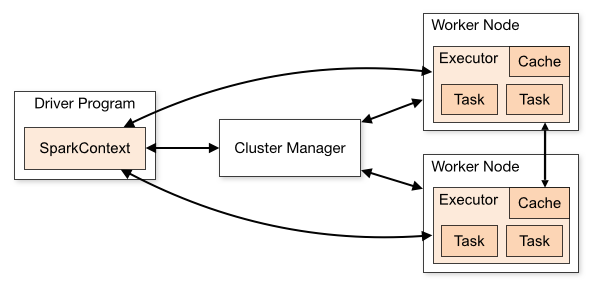
在实际计算时,Spark 会将对 RDD 操作分解为 Task,Task 运行在 Worker Node 上。在执行之前,Spark 会对任务进行闭包,如果闭包内涉及到自由变量,则程序会进行拷贝,并将副本变量放在闭包中,之后闭包被序列化并发送给每个执行者。因此,当在 foreach 函数中引用 counter 时,它将不再是 Driver 节点上的 counter,而是闭包中的副本 counter,默认情况下,副本 counter 更新后的值不会回传到 Driver,所以 counter 的最终值仍然为零。
需要注意的是:在 Local 模式下,有可能执行 foreach 的 Worker Node 与 Diver 处在相同的 JVM,并引用相同的原始 counter,这时候更新可能是正确的,但是在集群模式下一定不正确。所以在遇到此类问题时应优先使用累加器。
累加器的原理实际上很简单:就是将每个副本变量的最终值传回 Driver,由 Driver 聚合后得到最终值,并更新原始变量。
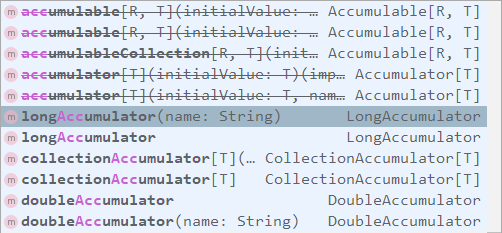
2.2 使用累加器
SparkContext 中定义了所有创建累加器的方法,需要注意的是:被中横线划掉的累加器方法在 Spark 2.0.0 之后被标识为废弃。
使用示例和执行结果分别如下:
val data = Array(1, 2, 3, 4, 5)
// 定义累加器
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(data).foreach(x => accum.add(x))
// 获取累加器的值
accum.value

三、广播变量
在上面介绍中闭包的过程中我们说道每个 Task 任务的闭包都会持有自由变量的副本,如果变量很大且 Task 任务很多的情况下,这必然会对网络 IO 造成压力,为了解决这个情况,Spark 提供了广播变量。
广播变量的做法很简单:就是不把副本变量分发到每个 Task 中,而是将其分发到每个 Executor,Executor 中的所有 Task 共享一个副本变量。
// 把一个数组定义为一个广播变量
val broadcastVar = sc.broadcast(Array(1, 2, 3, 4, 5))
// 之后用到该数组时应优先使用广播变量,而不是原值
sc.parallelize(broadcastVar.value).map(_ * 10).collect()
参考资料
入门大数据---Spark累加器与广播变量的更多相关文章
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- 入门大数据---Spark简介
一.简介 Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目.相对于 MapRedu ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 入门大数据---Spark部署模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- 入门大数据---Spark车辆监控项目
一.项目简介 这是一个车辆监控项目.主要实现了三个功能: 1.计算每一个区域车流量最多的前3条道路. 2.计算道路转换率 3.实时统计道路拥堵情况(当前时间,卡口编号,车辆总数,速度总数,平均速度) ...
- Spark学习之路(六)—— 累加器与广播变量
一.简介 在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: 广播变量 ...
- Spark 系列(六)—— 累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- 王家林 大数据Spark超经典视频链接全集[转]
压缩过的大数据Spark蘑菇云行动前置课程视频百度云分享链接 链接:http://pan.baidu.com/s/1cFqjQu SCALA专辑 Scala深入浅出经典视频 链接:http://pan ...
随机推荐
- PAT1080 MOOC期终成绩 (25分) ——同样参考了柳婼大神的代码及思路,在自己的代码上做了修改,还是很复杂
1080 MOOC期终成绩 (25分) 对于在中国大学MOOC(http://www.icourse163.org/ )学习“数据结构”课程的学生,想要获得一张合格证书,必须首先获得不少于200分 ...
- 【Hadoop】namenode与secondarynamenode的checkpoint合并元数据
Checkpoint Node(检查点节点) NameNode persists its namespace using two files: fsimage, which is the latest ...
- Java实现 LeetCode 327 区间和的个数
327. 区间和的个数 给定一个整数数组 nums,返回区间和在 [lower, upper] 之间的个数,包含 lower 和 upper. 区间和 S(i, j) 表示在 nums 中,位置从 i ...
- java实现第六届蓝桥杯穿越雷区
穿越雷区 题目描述 X星的坦克战车很奇怪,它必须交替地穿越正能量辐射区和负能量辐射区才能保持正常运转,否则将报废. 某坦克需要从A区到B区去(A,B区本身是安全区,没有正能量或负能量特征),怎样走才能 ...
- OC 语言特点以及与其他语言的区别
OC 作为一门面向对象的语言,兼容c语言的语法,又有区别于其他面向对象语言的地方: 特点: 1.使用自动释放池,通过引用计数处理对象的内存管理. 2.拥有id这种通用对象类型. 3.分类,功能强大,不 ...
- zabbix 邮箱告警
脚本内容 #!/bin/env python #coding:utf- import smtplib from email.mime.text import MIMEText from sys imp ...
- k8s学习-集群调度
4.7.集群调度 4.7.1.说明 简介 Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上.听起来非常简单,但有很多要考虑的问题: 公平:如何保 ...
- 【 转】百度地图Canvas实现十万CAD数据秒级加载
Github上看到: https://github.com/lcosmos/map-canvas 这个实现台风轨迹,这个数据量非常庞大,当时打开时,看到这么多数据加载很快,感到有点震惊,然后自己研究了 ...
- Java实现定时任务的三种简单方法
第一种方法: /** * 先定义一个任务每天执行的时间点,再写一个死循环,不断地拿当前时间和事先定义的时间去比对,若到时间则执行任务 */ @Test public void test1() { St ...
- Codeforce Round #643 #645 #646 (Div2)
codeforce Round #643 #645 #646 div2 Round #643 problem A #include<bits/stdc++.h> using namespa ...