Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码。
Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat。
Hadoop 自身提供的几种小文件合并机制
Hadoop HAR
将众多小文件打包成一个大文件进行存储,并且打包后原来的文件仍然可以通过Map-reduce进行操作,打包后的文件由索引和存储两大部分组成
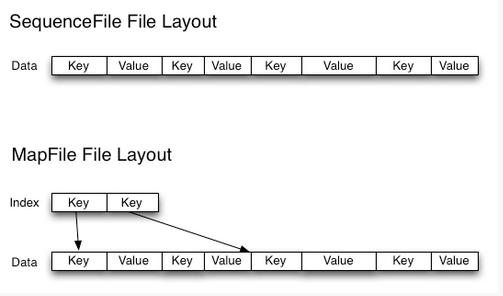
SequeuesFile
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split作为输入,而不是通常使用一个文件作为输入。另外,它会考虑数据的存储位置。

目前很多公司采用的方法就是在数据进入 Hadoop 的 HDFS 系统之前进行合并(也是本博文这方法),一般效果较上述三种方法明显。



代码
package zhouls.bigdata.myMapReduce.MergeSmallFiles;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
import org.apache.hadoop.io.IOUtils;
/**
* function 合并小文件至 HDFS
*
*
*/
public class MergeSmallFilesToHDFS {
private static FileSystem fs = null;
private static FileSystem local = null;
/**
* @function main
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws IOException,
URISyntaxException {
list();
}
/**
*
* @throws IOException
* @throws URISyntaxException
*/
public static void list() throws IOException, URISyntaxException {
// 读取hadoop文件系统的配置
Configuration conf = new Configuration();
//文件系统访问接口
URI uri = new URI("hdfs://HadoopMaster:9000");
//创建FileSystem对象aa
fs = FileSystem.get(uri, conf);
// 获得本地文件系统
local = FileSystem.getLocal(conf);
//过滤目录下的 svn 文件
FileStatus[] dirstatus = local.globStatus(new Path("./data/mergeSmallFiles/*"),new RegexExcludePathFilter("^.*svn$"));
//获取73目录下的所有文件路径
Path[] dirs = FileUtil.stat2Paths(dirstatus);
FSDataOutputStream out = null;
FSDataInputStream in = null;
for (Path dir : dirs) {
String fileName = dir.getName().replace("-", "");//文件名称
//只接受日期目录下的.txt文件a
FileStatus[] localStatus = local.globStatus(new Path(dir+"/*"),new RegexAcceptPathFilter("^.*txt$"));
// 获得日期目录下的所有文件
Path[] listedPaths = FileUtil.stat2Paths(localStatus);
//输出路径
Path block = new Path("hdfs://HadoopMaster:9000/tv/"+ fileName + ".txt");
// 打开输出流
out = fs.create(block);
for (Path p : listedPaths) {
in = local.open(p);// 打开输入流
IOUtils.copyBytes(in, out, 4096, false); // 复制数据
// 关闭输入流
in.close();
}
if (out != null) {
// 关闭输出流a
out.close();
}
}
}
/**
*
* @function 过滤 regex 格式的文件
*
*/
public static class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
@Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return !flag;
}
}
/**
*
* @function 接受 regex 格式的文件
*
*/
public static class RegexAcceptPathFilter implements PathFilter {
private final String regex;
public RegexAcceptPathFilter(String regex) {
this.regex = regex;
}
@Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return flag;
}
}
}
Hadoop MapReduce编程 API入门系列之小文件合并(二十九)的更多相关文章
- Hadoop MapReduce编程 API入门系列之分区和合并(十四)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.Star; import java.io.IOException; import org.apache ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
随机推荐
- Activity 和 生命周期: 创建
了解了整体的android创建流程之后,就分析一下到底这个过程中做了什么? activity创建中开始时由activityStack中的realstartActivityLocked函数中调用了act ...
- pod install报错问题解决
pod installwarning: Insecure world writable dir /usr/local/bin in PATH, mode 040777报错后就不进行了.查stackov ...
- StatisticalOutlierRemoval源码
源代码 * * Software License Agreement (BSD License) * * Point Cloud Library (PCL) - www.pointclouds.org ...
- jsp打印页面 js代码
function doPrint() { bdhtml=window.document.body.innerHTML; sprnstr=""; //开始打印标识字符串有17个字符 ...
- mysql事务,START TRANSACTION, COMMIT和ROLLBACK,SET AUTOCOMMIT语法
http://yulei568.blog.163.com/blog/static/135886720071012444422/ MyISAM不支持 START TRANSACTION | BEGIN ...
- 030. asp.net中DataList数据绑定跳转(两种方式)的完整示例
前台代码: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.as ...
- android学习笔记52——手势Gesture,增加手势、识别手势
手势Gesture,增加手势 android除了提供了手势检测之外,还允许应用程序把用户手势(多个持续的触摸事件在屏幕上形成特定的形状)添加到指定文件中,以备以后使用 如果程序需要,当用户下次再次画出 ...
- HBase体系结构(转)
HBase的服务器体系结构遵循简单的主从服务器架构,它由HRegion服务器(HRegion Server)群和HBase Master服务器(HBase Master Server)构成.HBase ...
- SSH登陆 Write failed: Broken pipe解决办法
新装的一台linux 6.4主机在所有参数调优以后,运行起来要跑的程序后.再通过su - www时,提示如下: su: cannot set user id: Resource temporarily ...
- python模块介绍- SocketServer 网络服务框架
来源:https://my.oschina.net/u/1433482/blog/190612 摘要: SocketServer简化了网络服务器的编写.它有4个类:TCPServer,UDPServe ...