Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码。
Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat。
Hadoop 自身提供的几种小文件合并机制
Hadoop HAR
将众多小文件打包成一个大文件进行存储,并且打包后原来的文件仍然可以通过Map-reduce进行操作,打包后的文件由索引和存储两大部分组成
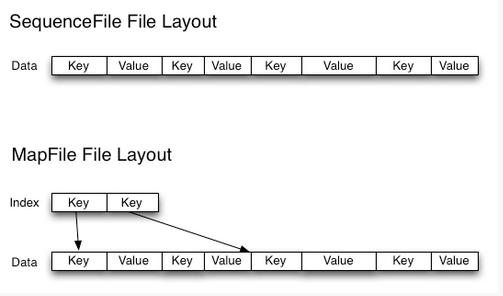
SequeuesFile
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split作为输入,而不是通常使用一个文件作为输入。另外,它会考虑数据的存储位置。

目前很多公司采用的方法就是在数据进入 Hadoop 的 HDFS 系统之前进行合并(也是本博文这方法),一般效果较上述三种方法明显。



代码
package zhouls.bigdata.myMapReduce.MergeSmallFiles;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
import org.apache.hadoop.io.IOUtils;
/**
* function 合并小文件至 HDFS
*
*
*/
public class MergeSmallFilesToHDFS {
private static FileSystem fs = null;
private static FileSystem local = null;
/**
* @function main
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws IOException,
URISyntaxException {
list();
}
/**
*
* @throws IOException
* @throws URISyntaxException
*/
public static void list() throws IOException, URISyntaxException {
// 读取hadoop文件系统的配置
Configuration conf = new Configuration();
//文件系统访问接口
URI uri = new URI("hdfs://HadoopMaster:9000");
//创建FileSystem对象aa
fs = FileSystem.get(uri, conf);
// 获得本地文件系统
local = FileSystem.getLocal(conf);
//过滤目录下的 svn 文件
FileStatus[] dirstatus = local.globStatus(new Path("./data/mergeSmallFiles/*"),new RegexExcludePathFilter("^.*svn$"));
//获取73目录下的所有文件路径
Path[] dirs = FileUtil.stat2Paths(dirstatus);
FSDataOutputStream out = null;
FSDataInputStream in = null;
for (Path dir : dirs) {
String fileName = dir.getName().replace("-", "");//文件名称
//只接受日期目录下的.txt文件a
FileStatus[] localStatus = local.globStatus(new Path(dir+"/*"),new RegexAcceptPathFilter("^.*txt$"));
// 获得日期目录下的所有文件
Path[] listedPaths = FileUtil.stat2Paths(localStatus);
//输出路径
Path block = new Path("hdfs://HadoopMaster:9000/tv/"+ fileName + ".txt");
// 打开输出流
out = fs.create(block);
for (Path p : listedPaths) {
in = local.open(p);// 打开输入流
IOUtils.copyBytes(in, out, 4096, false); // 复制数据
// 关闭输入流
in.close();
}
if (out != null) {
// 关闭输出流a
out.close();
}
}
}
/**
*
* @function 过滤 regex 格式的文件
*
*/
public static class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
@Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return !flag;
}
}
/**
*
* @function 接受 regex 格式的文件
*
*/
public static class RegexAcceptPathFilter implements PathFilter {
private final String regex;
public RegexAcceptPathFilter(String regex) {
this.regex = regex;
}
@Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return flag;
}
}
}
Hadoop MapReduce编程 API入门系列之小文件合并(二十九)的更多相关文章
- Hadoop MapReduce编程 API入门系列之分区和合并(十四)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.Star; import java.io.IOException; import org.apache ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
随机推荐
- laravel_5《数据库迁移》
Laravel鼓励敏捷.迭代的开发方式,我们没指望在第一次就获得所有正确的.相反,我们编写代码.测试和与我们的最终用户进行交互,并完善我们的理解. 对于工作,我们需要一个配套的实践集.我们使用像sub ...
- HDU 2276
http://acm.hdu.edu.cn/showproblem.php?pid=2276 矩阵乘法可以解决的一类灯泡开关问题 /* 转移关系为 now left now* 1 0 1 1 1 0 ...
- AHS日志收集的三种方法
硬件环境:(描述实验机器初始环境) 型号 DL380 G8 序列号 配置扩展 备注 软件环境: □ 操作系统:无 连接方式: □ 无 实验步骤: 1在ILO里点information点 ...
- OC基础—多态(超级简单)
前言: oc中的指针类型变量有两个:一个是编译时类型,一个是运行时类型,编译时类型由声明该变量是使用的类型决定,运行时类型由实际赋给该变量的对象决定.如果编译时类型和运行时类型不一致,就有可能出现多态 ...
- Python Mysql 篇
Python 操作 Mysql 模块的安装 linux: yum install MySQL-python window: http://files.cnblogs.com/files/wupeiqi ...
- 关于android存储
今天在测试android拍照功能时遇到一个困惑:照片拍成功了,程序能都能读取到,但是在手机储存中怎么也找不到拍的照片.先将学习过程中经过的曲折过程记录如下: 一:拍照并保持 通过调用android 的 ...
- python学习-day16:函数作用域、匿名函数、函数式编程、map、filter、reduce函数、内置函数r
一.作用域 作用域在定义函数时就已经固定住了,不会随着调用位置的改变而改变 二.匿名函数 lambda:正常和其他函数进行配合使用.正常无需把匿名函数赋值给一个变量. f=lambda x:x*x p ...
- Mysql对用户操作加审计功能——初级版
在某些应用里,需要知道谁对表进行了操作,进行了什么操作,所为责任的追朔.在MYSQL里,可以使用触发器实现. 1:创建测试表 mysql> create table A(a int);Query ...
- c# Wndproc的使用方法
protected override void WndProc(ref Message m) { const int WM_SYSCOMMAND = 0x0112; const int SC_CLOS ...
- java io流(字符流) 文件打开、读取文件、关闭文件
java io流(字符流) 文件打开 读取文件 关闭文件 //打开文件 //读取文件内容 //关闭文件 import java.io.*; public class Index{ public sta ...