分布式条件下Integer大小比值的问题
起因
临下班,偶然看到阿里巴巴《JAVA开发手册》中,关于整型包装类对象之间值的比较的规约,里面提到强制使用equals,而不使用==。原因众所周知,在-128 至 127,Integer 对象是在 IntegerCache.cache 产生。
所以很多人会在代码里使用去进行-128 至 127之间的数值比较。特别是一些常量,如state,status这类的常量,值通常都在100以内进行定义。感觉上是没有问题。阿里的《JAVA开发手册》里面也提到了“**这个区间内的 Integer 值可以直接使用进行判断**”。

但是,搞大数据的同学请注意了!
大数据天然是分布式的,比如spark,每个executor执行器哪怕在同一个服务器节点上,也会申请一个单独的JVM,所以,这个时候定义一个Integer哪怕是落在-128 至 127范围以内,通过“==”能得到想要的效果吗?
都在不同的JVM了,内存地址当然不一样了,所以答案很显然是否定的。
动机
鉴于阿里巴巴的影响力,它的《JAVA开发手册》读者还有众多的。所以,觉得有必要提醒出这一点。
1.在大数据分布式情况下,对于 Integer var = ? 在-128 至 127 之间的赋值,不可以直接使用==进行判断。
2.不管是单机程序还是分布式程序,一律使用equals进行数值比较,或者使用基础数据类型。
验证
测试代码:
public class Constants {
public static final Integer STATE = 1;
}
int state = 1;
Integer state1 = 1;
Integer state2 = new Integer(1);
Integer state3 = Integer.valueOf(1);
SparkSession session = SparkSession.builder().appName("Validate").getOrCreate();
Long count = session.read().limf("/patt").select("vin").map(new MapFunction<Row, String>() {
@Override
public String call(Row value) throws Exception {
System.out.println("1 hashcode :" + System.identityHashCode(state1)+" 2:"+System.identityHashCode(state2)+" 3:"+System.identityHashCode(state3)+" constant = " + System.identityHashCode(Constants.STATE.hashCode()));
System.out.println((state == Constants.STATE) + " 1:" + (state1 == Constants.STATE) + " 2:" + (state2 == Constants.STATE) + " 3:" + (state3 == Constants.STATE));
Thread.sleep(100000);
return value.mkString();
}
}, Encoders.STRING()).count();
在不同的task打印出来的日志:

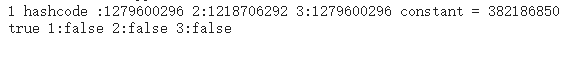
可以看到,用了Integer包装类的分布式内部比较使用“==”得不到预期值。
处理
已在github提出问题
https://github.com/alibaba/p3c/issues/863
分布式条件下Integer大小比值的问题的更多相关文章
- 【转】MySQL乐观锁在分布式场景下的实践
背景 在电商购物的场景下,当我们点击购物时,后端服务就会对相应的商品进行减库存操作.在单实例部署的情况,我们可以简单地使用JVM提供的锁机制对减库存操作进行加锁,防止多个用户同时点击购买后导致的库存不 ...
- MySQL乐观锁在分布式场景下的实践
背景 在电商购物的场景下,当我们点击购物时,后端服务就会对相应的商品进行减库存操作.在单实例部署的情况,我们可以简单地使用JVM提供的锁机制对减库存操作进行加锁,防止多个用户同时点击购买后导致的库存不 ...
- [Done]SnowFlake 分布式环境下基于ZK构WorkId
Twitter 的 Snowflake 大家应该都熟悉的,先上个图: 时间戳 序列号一般不会去改造,主要是工作机器id,大家会进行相关改造,我厂对工作机器进行了如下改造(估计大家都差不多吧,囧~~~ ...
- 虚拟机在 OpenStack 里没有共享存储条件下的在线迁移
虚拟机在 OpenStack 里没有共享存储条件下的在线迁移 本文尝试回答与 Live migration 相关的几个问题:Live migration 是什么?为什么要做 Live migratio ...
- 分布式架构下,session共享有什么方案么?
分布式架构下,session共享有什么方案么? 会点代码的大叔 科技领域创作者 分布式架构下的session共享,也可以称作分布式session一致性:关于这个问题,和大家说一说解决方案(如果有其他的 ...
- 分布式架构下的会话追踪实践【基于Cookie和Redis实现】
分布式架构下的会话追踪实践[基于Cookie和Redis实现] 博客分类: NoSQL/Redis/MongoDB session共享rediscookie分布式架构session 在单台Tomcat ...
- 【无网条件下】Linux系统、jdk、redis及集群、rabbitmq、nginx、weblogic和oracle安装及配置
本篇文章为原创,仅供参考使用,如果需要文章中提到的所有软件安装包和依赖包(即data),请以博客园邮箱联系获取链接. 准备资料 软件 主要软件包版本 路径 系统镜像 CentOS-6.10-x86_6 ...
- 复杂分布式架构下的计算治理之路:计算中间件 Linkis
前言 在当前的复杂分布式架构环境下,服务治理已经大行其道.但目光往下一层,从上层 APP.Service,到底层计算引擎这一层面,却还是各个引擎各自为政,Client-Server 模式紧耦合满天飞的 ...
- 分布式场景下Kafka消息顺序性的思考
如果业务中,对于kafka发送消息异步消费的场景,在业务上需要实现在消费时实现顺序消费, 利用kafka在partition内消息有序的特点,消息消费时的有序性. 1.在发送消息时,通过指定parti ...
随机推荐
- 借jQuery对象拷贝学习深拷贝与浅拷贝
jQuery.extend([deep], target, object1, [objectN]) 即用一个或多个其他对象来扩展一个对象,返回被扩展的对象. deep:如果设为true,则递归合并. ...
- 最详细STL(一)vector
vector的本质还是数组,但是可以动态的增加和减少数组的容量(当数组空间内存不足时,都会执行: 分配新空间-复制元素-释放原空间),首先先讲讲vector和数组的具体区别 一.vector和数组的区 ...
- 解决安装mysql 到start service出现未响应问题
mysql下载地址 链接: https://pan.baidu.com/s/1vYpsNkVjUHqOKPQl9Y9A9A 提取码: wngn 安装可以参考 今天下载了MySql5.5,没想到的是前面 ...
- Node.js躬行记(12)——BFF
BFF字面意思是服务于前端的后端,我的理解就是数据聚合层.我们组在维护一个后台管理系统,会频繁的与数据库交互. 过去为了增删改查会写大量的对应接口,并且还需要在Model.Service.Router ...
- tomcat unkonwhost
服务器能ping通域名,tomcat死活不行,重启tomcat解决
- Java学习路线【转】
Java学习路线[转] 第一阶段:JavaSE(Java基础部分) Java开发前奏 计算机基本原理,Java语言发展简史以及开发环境的搭建,体验Java程序的开发,环境变量的设置,程序的执行过程,相 ...
- 【UE4 C++】编程子系统 Subsystem
概述 定义 Subsystems 是一套可以定义.自动实例化和释放的类的框架.可以将其理解为 GamePlay 级别的 Component 不支持网络赋值 4.22开始引入,4.24完善.(可以移植源 ...
- 使用包图 (UML Package Diagram) 构建模型架构
包图用于以包包含层次结构的形式显示模型的组织方式.包图还可以显示包包含的模型元素以及包与其包含的模型元素之间的依赖关系. 在项目开发中,模型元素可能会很快达到大量数量,因此需要以某种方式构建它们,即使 ...
- ssh后门反向代理实现内网穿透
如图所示,内网主机ginger 无公网IP地址,防火墙只允许ginger连接blackbox.example.com主机 假如你是ginger的管理员root,你想要用tech主机连接ginger主机 ...
- 脚本:bat实现自动转换windows远程端口
问题描述:通过一个脚本可以实现windows远程端口的转换,这个是拷贝过来学习的一个脚本 @echo off color f0 echo 修改远程桌面3389端口(支持Windows 2003 200 ...