大数据学习(18)—— Flume介绍
老规矩,学习新东西先上官网瞅瞅Apache Flume
Flume是什么
Flume是一个分布式、可靠的大规模高效日志收集、汇聚和传输的这么一个服务。它的架构基于流式数据,配置简单灵活。它具备可调节的可靠性机制和很多失败恢复机制,这让它具有健壮性和容错性。它采用简单可扩展的数据模型为在线分析应用提供支持。
Flume架构
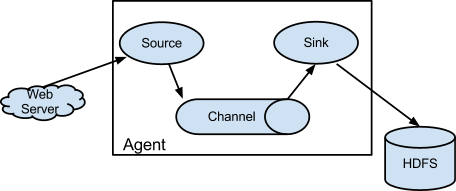
没见过这么简单的架构图,这说明了flume用起来并不复杂。它通过Source从数据源把日志拿过来放到Channel里面存一下,再通过sink写入到持久化存储里。
咋一看,这玩意跟消息队列的生产者消费者差不多,中间是个队列。网上确实也有不少拿Flume跟Kafka对比的文章,它们还是有区别的。Kafka可以参与到Flume的每一个组件里,Flume+Kafka是一个流行的组合。
玩大数据的这些技术,内存要尽量大一点,Channel用内存存储比较常见。
Flume从数据源取数写入Channel是一个事务,从Channel取数通过Sink写到目的存储又是一个事务。来个详细一点的图吧,拿来主义,从网上找的。
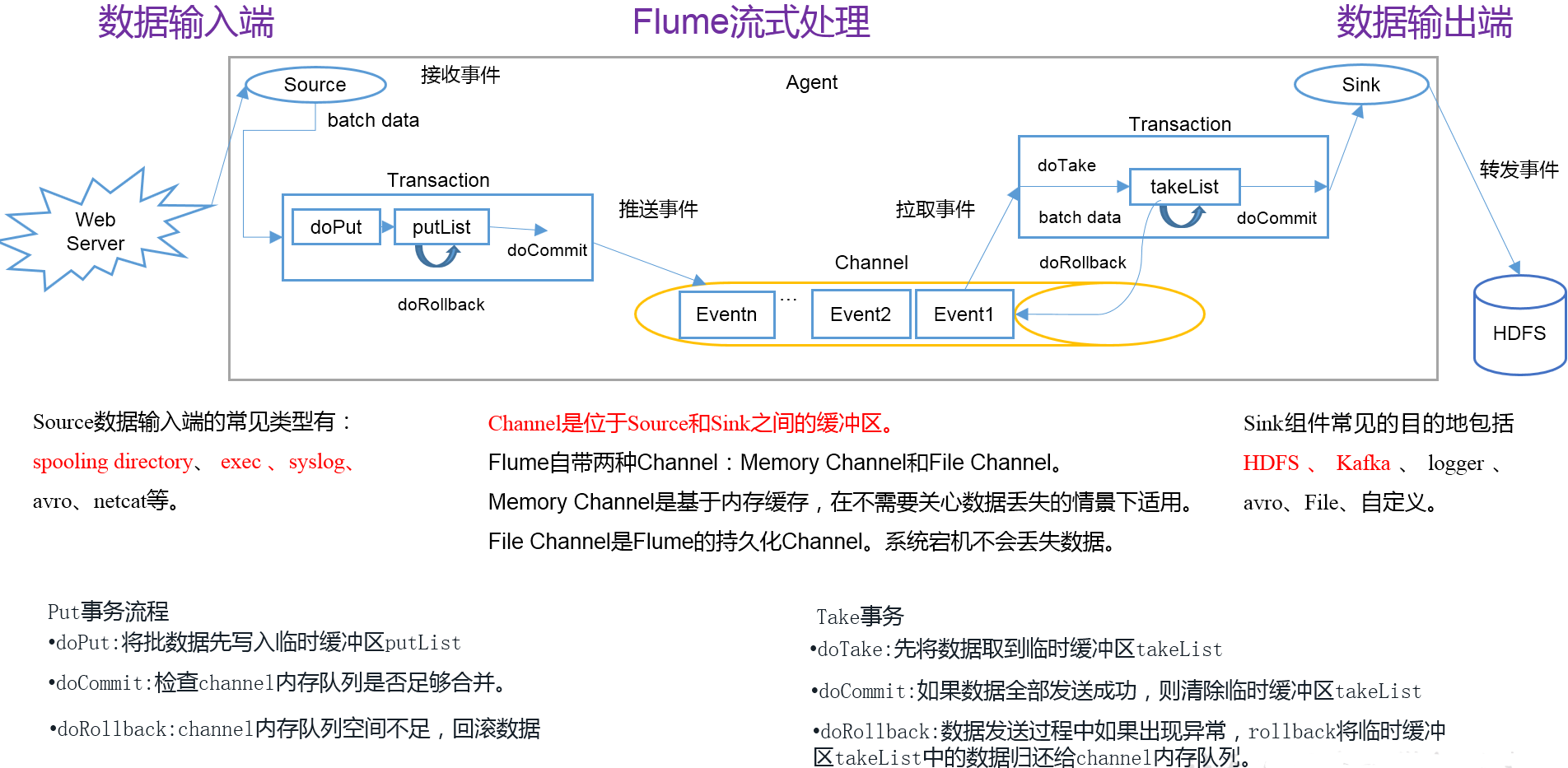
Agent
服务起来后,它是一个JVM进程,包含了Source、Channel和Sink,是Flume传输数据的基本单元。
Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理非常多的数据源。看官网目录。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘,因此在程序关闭或机器宕机的情况下不会丢失数据,但是效率很低。
Channel种类要少一点。

Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink的种类也比较少。
Event
官网原话A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes.它是一个数据流,包含有效荷载和可选字符串属性。
它是最小传输单元,以事件的形式将数据从源头送至目的地。 Event由可选的header和载有数据的一个byte array 构成。Header是容纳了key-value字符串对的HashMap。

Flume用在哪儿

这是Flume的一个典型应用场景。从数据源抽取数据,原封不动地存储到HDFS,经过ETL处理后存入HBase,用Hive做完分析后,通过Sqoop导入关系型数据库来展示。
大数据学习(18)—— Flume介绍的更多相关文章
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
随机推荐
- 详解详解Java中static关键字和final关键字的功能
摘要:static关键字和final关键字是Java语言的核心,深入理解他们的功能非常重要. 本文分享自华为云社区<Java: static关键字与final关键字>,原文作者:唐里 . ...
- Linux网络基础TCP/IP
1.osi:七层 上三层,主要是用户层面;下四层是实际进行数据传输物理层: 设备之间比特流的传输,物理接口,电气特性等 端口号的作用 通过IP找到服务器,通过端口号找到具体哪个服务.网页服务的端口号是 ...
- Java的一些细节语法(不定时更新。。。)
可信考试Java相关题目 目录 可信考试Java相关题目 ConcurrentHashMap不允许key为null,但是HashMap是可以的.TreeMap key不支持null. 以下代码里面,请 ...
- [Linux网络、命名空间、veth设备对、docker的host模式、container模式、none模式、brideg模式、网桥的增删查,容器与网桥的连接断开]
[Linux网络.命名空间.veth设备对.docker的host模式.container模式.none模式.brideg模式.网桥的增删查,容器与网桥的连接断开] 网络名称空间 为了支持网络协议栈的 ...
- 在vue项目中使用echarts
1.安装echarts依赖npm install echarts --save 2.在要使用的页面引入import echarts from 'echarts'v5之后使用 import * echa ...
- 16 自动发布PHP项目
#!/bin/bash export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin PHP_NAME=$1 DATE ...
- kali安装angr
最近打算重新学习一波angr,先把环境搭好 1. 先安装virtualenv,这玩意是可以创建一个纯净的python环境,我陷入了沉思,pyenv好像也可以 这里利用豆瓣的源下载,非常快而且很舒服 p ...
- WPF教程十:如何使用Style和Behavior在WPF中规范视觉样式
在使用WPF编写客户端代码时,我们会在VM下解耦业务逻辑,而剩下与功能无关的内容比如动画.视觉效果,布局切换等等在数量和复杂性上都超过了业务代码.而如何更好的简化这些编码,WPF设计人员使用了Styl ...
- 从零开始给女朋友讲计算机 1 - 从比特、字节、补码到 ASCII、GB2312、Unicode
起因 在代码 review 的过程中,总是发现有人在数据类型转换(reinterpret_cast).大小端的问题(什么情况下需要考虑大小端,什么情况下不需要考虑)上犯错误,究其原因是没有彻彻底底地搞 ...
- 性能基准DevOps之如何提升脚本执行效率
1.宝路说 宝路最近一直在自我思考:性能基准DevOps工作已经开展一段时间了,目前我们确实已经取得了一些成果,显然这还远远不够.趁闲暇之余跟组员进行了简单的头脑风暴!于是这就有了今天的主题,当然这仅 ...