大数据系列之Flume+kafka 整合
相关文章:
关于Flume 的 一些核心概念:
| 组件名称 | 功能介绍 |
| Agent代理 | 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
| Client客户端 | 生产数据,运行在一个独立的线程。 |
| Source源 | 从Client收集数据,传递给Channel。 |
| Sink接收器 | 从Channel收集数据,进行相关操作,运行在一个独立线程。 |
| Channel通道 | 连接 sources 和 sinks ,这个有点像一个队列。 |
| Events事件 | 传输的基本数据负载。 |
文章和 大数据系列之Flume+HDFS 非常相似,不同的在于flume安装目录conf下新建了kafka.properties文件,启动时也应当用此配置文件作为参数启动。下面看具体内容:
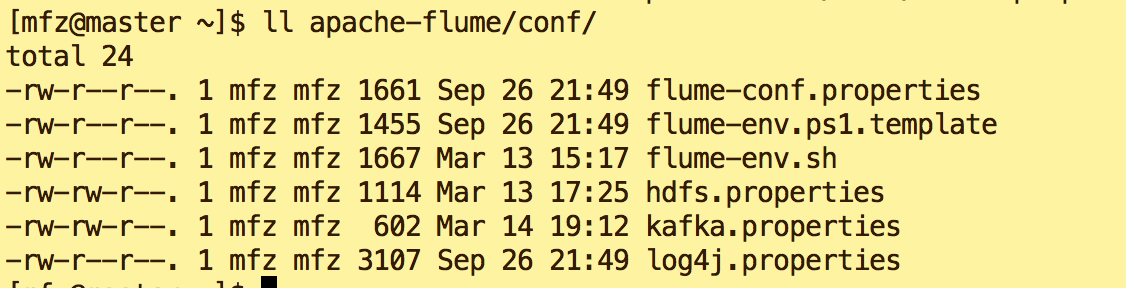
1. kafka.properties:
agent.sources = s1
agent.channels = c1
agent.sinks = k1 agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /tmp/logs/kafka.log
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100 #设置Kafka接收器
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=master:9092
#设置Kafka的Topic
agent.sinks.k1.topic=kafkatest
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder agent.sinks.k1.channel=c1
关于配置文件中注意3点:
a. agent.sources.s1.command=tail -F /tmp/logs/kafka.log
b. agent.sinks.k1.brokerList=master:9092
c . agent.sinks.k1.topic=kafkatest
2.很明显,由配置文件可以了解到:
a.我们需要在/tmp/logs下建一个kafka.log的文件,且向文件中输出内容(下面会说到);
b.flume连接到kafka的地址是 master:9092,注意不要配置出错了;
c.flume会将采集后的内容输出到Kafka topic 为kafkatest上,所以我们启动zk,kafka后需要打开一个终端消费topic kafkatest的内容。这样就可以看到flume与kafka之间玩起来了~~
3.具体操作:
a.在/tmp/logs下建立空文件kafka.log。在mfz 用户目录下新建脚本kafkaoutput.sh(一定要给予可执行权限),用来向kafka.log输入内容: kafka_test***
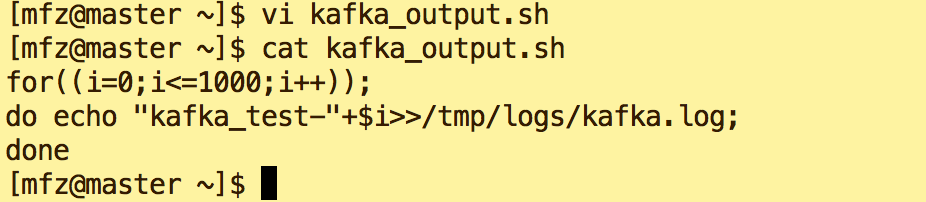
for((i=0;i<=1000;i++));
do echo "kafka_test-"+$i>>/tmp/logs/kafka.log;
done
b. 在kafka安装目录下执行如下命令,启动zk,kafka 。(不明白此处可参照 大数据系列之Flume+HDFS)
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties &
bin/kafka-server-start.sh -daemon config/server.properties &
c.新增Topic kafkatest
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatest
d.打开新终端,在kafka安装目录下执行如下命令,生成对topic kafkatest 的消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafkatest --from-beginning --zookeeper master
e.启动flume
bin/flume-ng agent --conf-file conf/kafka.properties -c conf/ --name agent -Dflume.root.logger=DEBUG,console
d.执行kafkaoutput.sh脚本(注意观察kafka.log内容及消费终端接收到的内容)

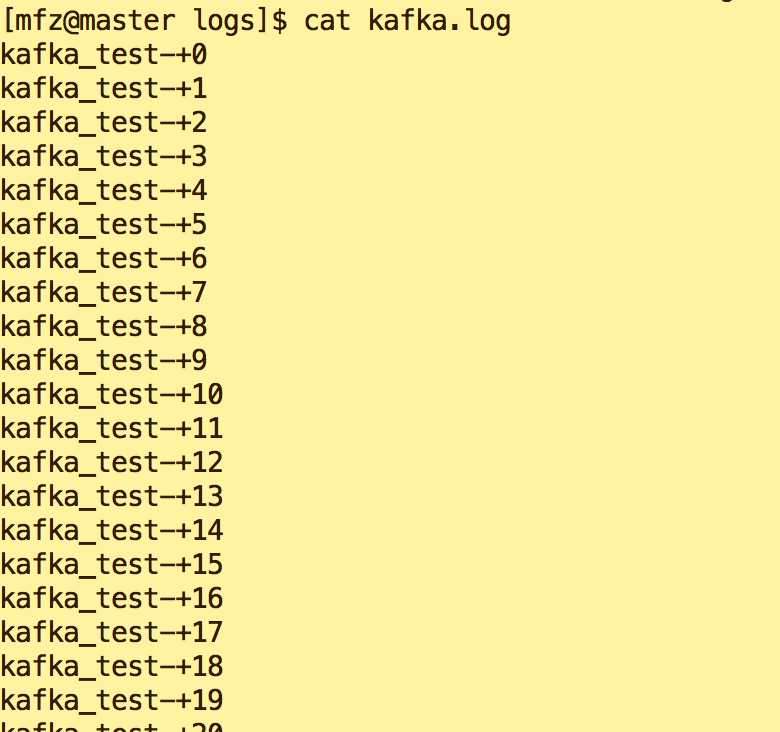
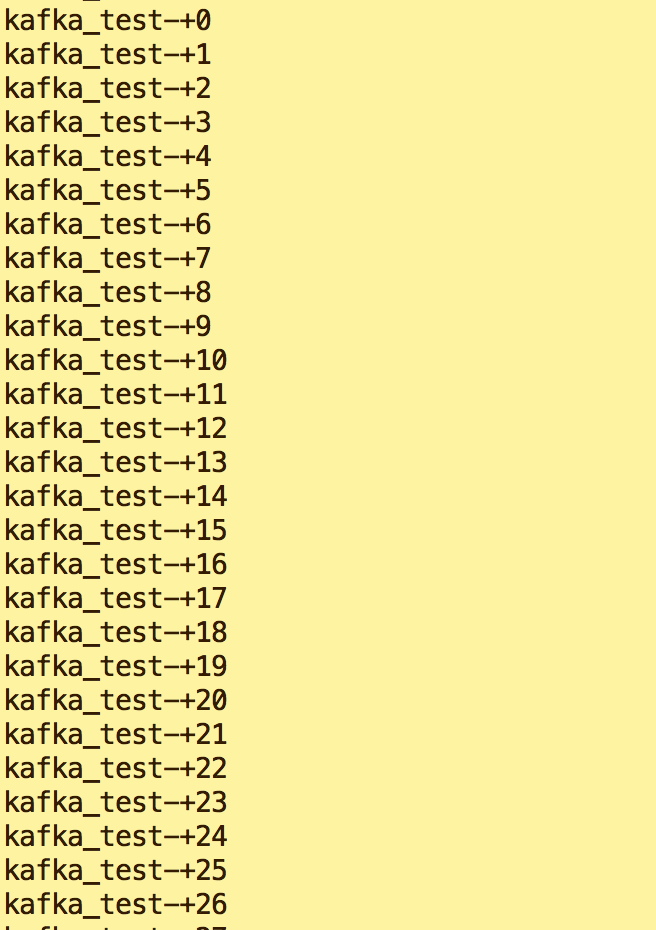
e.查看新终端消费信息
整体流程如图:
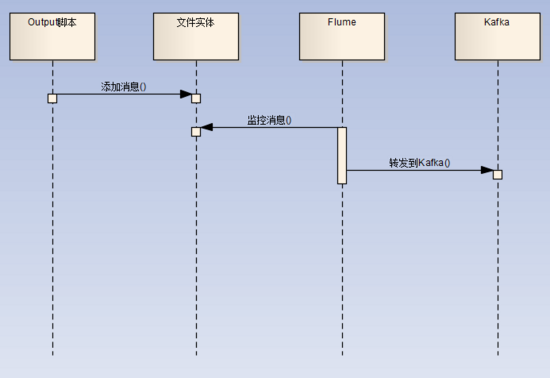
完~~
后续将介绍Java代码对于Flume+HDFS ,Flume+Kafka的实现。敬请期待~
大数据系列之Flume+kafka 整合的更多相关文章
- 大数据入门第十八天——kafka整合flume、storm
一.实时业务指标分析 1.业务 业务: 订单系统---->MQ---->Kakfa--->Storm 数据:订单编号.订单时间.支付编号.支付时间.商品编号.商家名称.商品价格.优惠 ...
- 大数据系列之Flume+HDFS
本文将介绍Flume(Spooling Directory Source) + HDFS,关于Flume 中几种Source详见文章 http://www.cnblogs.com/cnmenglang ...
- Flume+Kafka整合
脚本生产数据---->flume采集数据----->kafka消费数据------->storm集群处理数据 日志文件使用log4j生成,滚动生成! 当前正在写入的文件在满足一定的数 ...
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
随机推荐
- BZOJ5011 JXOI2017颜色(主席树)
相当于求满足在子段中出现的颜色只在该子段中出现的非空子段数量.这也就相当于其中出现的颜色最左出现的位置在左端点右侧,最右出现的位置在右端点左侧.那么若固定某个端点,仅考虑对该端点的限制,会有一段合法区 ...
- NOIP模拟
1.要选一个{1,2,...n}的子集使得假如a和b在所选集合里且(a+b)/2∈{1,2,...n}那么(a+b)/2也在所选集合里 f[i]=2*f[i-1]-f[i-2]+g[i] g[n]:选 ...
- listen() 函数
声明:本文来自网络博文的合并,文后有链接. 一.listen函数仅由TCP服务器调用 它做两件事: 1.当socket函数创建一个套接字时,它被假设为一个主动套接字,也就是说,它是一个将调用conne ...
- Redis的键值命令、服务器命令
Redis提供了丰富的命令对数据库和各种数据类型进行操作,这些命令可以在Linux 终端使用.在编程时,比如各类语言包,这些命令都有对应的方法. 键值命令 服务器命令 获取数据库中所有键名 >k ...
- 利用MSXSL.exe绕过AppLocker应用程序控制策略
1.需要用到微软工具MSXSL.exe,msxsl.exe是微软用于命令行下处理XSL的一个程序,所以通过他,我们可以执行JavaScript进而执行系统命令,其下载地址为: https://www. ...
- 驱动之DMA的介绍与应用20170210
本文主要介绍的是DMA相关的知识,首先: 1)在实现DMA传输时,是由DMA控制器直接掌管总线,因此,存在着一个总线控制权转移问题.即DMA传输前,CPU要把 总线控制权交给DMA控制器,而在结束DM ...
- Hibernate持久化对象修改id重新保存的办法
Hibernate持久化对象修改id重新保存的办法——Hibernate学习记录二 2017年11月10日 20:16:48 筱光 阅读数:1122 版权声明:本文为博主原创文章,未经博主允许不得 ...
- 【OpenCV】SIFT原理与源码分析:关键点描述
<SIFT原理与源码分析>系列文章索引:http://www.cnblogs.com/tianyalu/p/5467813.html 由前一篇<方向赋值>,为找到的关键点即SI ...
- STL源码分析-function
http://note.youdao.com/noteshare?id=269e16541b43095eaf97636d4e046b1d
- Error : getaddrinfo ENOTFOUND registry.npmjs.org registry.npmjs.org:443
环境 阿里云 centos7 node v8.11.3 npm 5.6.0 错误 npm update 解决 ping registry.npmjs.org 发现https://registry.np ...