大数据学习(18)—— Flume介绍
老规矩,学习新东西先上官网瞅瞅Apache Flume
Flume是什么
Flume是一个分布式、可靠的大规模高效日志收集、汇聚和传输的这么一个服务。它的架构基于流式数据,配置简单灵活。它具备可调节的可靠性机制和很多失败恢复机制,这让它具有健壮性和容错性。它采用简单可扩展的数据模型为在线分析应用提供支持。
Flume架构
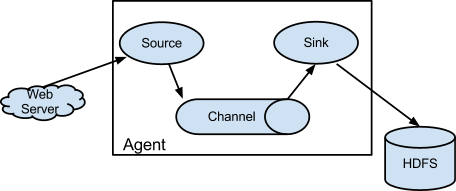
没见过这么简单的架构图,这说明了flume用起来并不复杂。它通过Source从数据源把日志拿过来放到Channel里面存一下,再通过sink写入到持久化存储里。
咋一看,这玩意跟消息队列的生产者消费者差不多,中间是个队列。网上确实也有不少拿Flume跟Kafka对比的文章,它们还是有区别的。Kafka可以参与到Flume的每一个组件里,Flume+Kafka是一个流行的组合。
玩大数据的这些技术,内存要尽量大一点,Channel用内存存储比较常见。
Flume从数据源取数写入Channel是一个事务,从Channel取数通过Sink写到目的存储又是一个事务。来个详细一点的图吧,拿来主义,从网上找的。
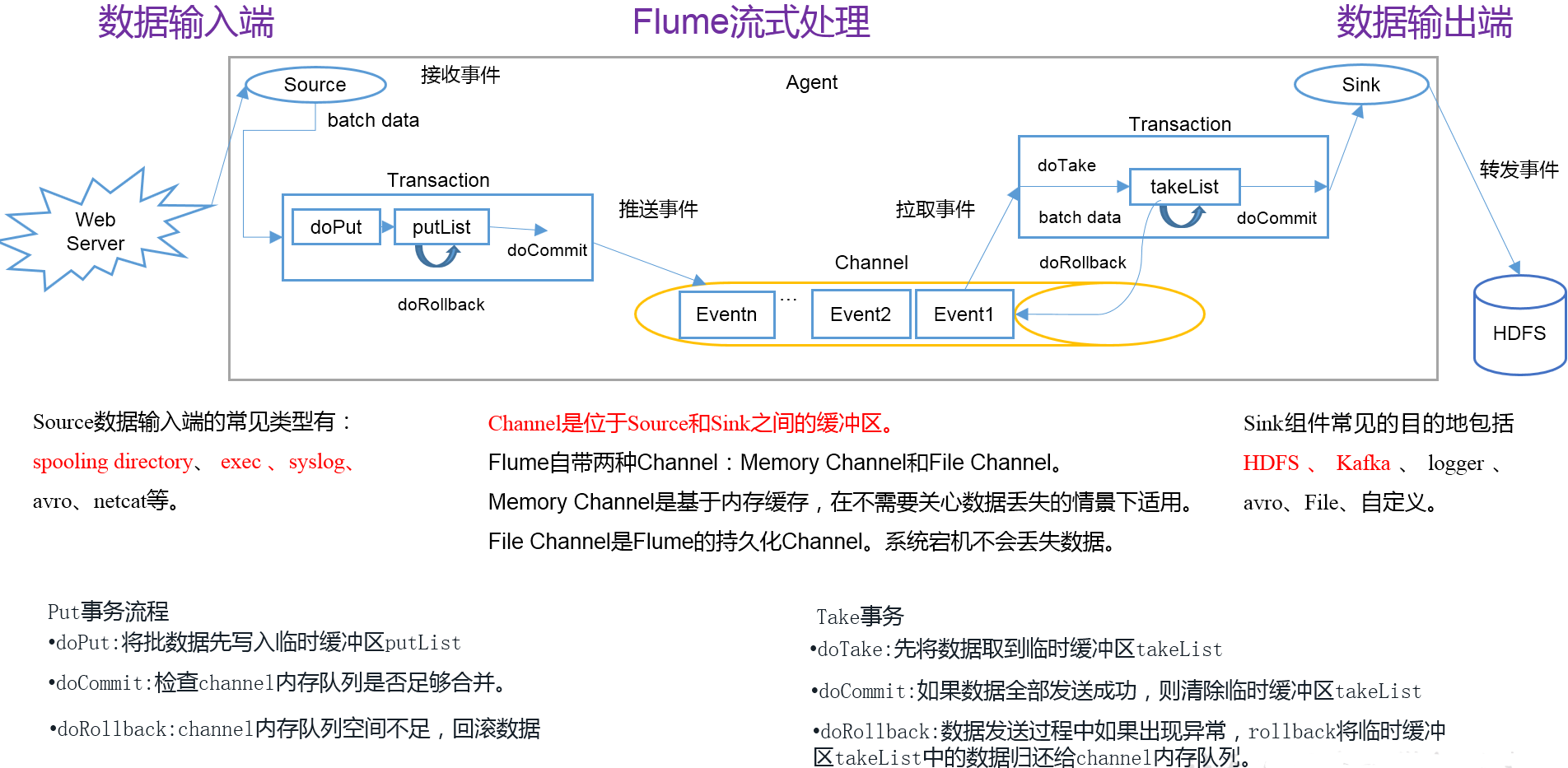
Agent
服务起来后,它是一个JVM进程,包含了Source、Channel和Sink,是Flume传输数据的基本单元。
Source
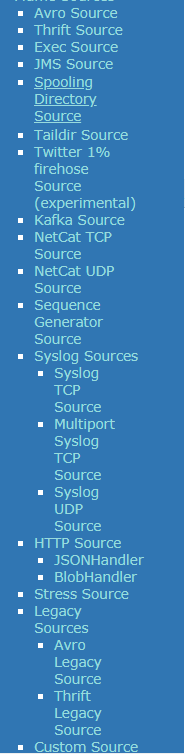
Source是负责接收数据到Flume Agent的组件。Source组件可以处理非常多的数据源。看官网目录。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘,因此在程序关闭或机器宕机的情况下不会丢失数据,但是效率很低。
Channel种类要少一点。

Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
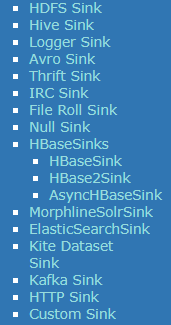
Sink的种类也比较少。
Event
官网原话A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes.它是一个数据流,包含有效荷载和可选字符串属性。
它是最小传输单元,以事件的形式将数据从源头送至目的地。 Event由可选的header和载有数据的一个byte array 构成。Header是容纳了key-value字符串对的HashMap。

Flume用在哪儿

这是Flume的一个典型应用场景。从数据源抽取数据,原封不动地存储到HDFS,经过ETL处理后存入HBase,用Hive做完分析后,通过Sqoop导入关系型数据库来展示。
大数据学习(18)—— Flume介绍的更多相关文章
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
随机推荐
- NOIP模拟测试11「string·matrix·big」
打的big出了点小问题,maxx初值我设的0然后少了10分 第二题暴力打炸 第一题剪了一些没用的枝依然40分 总分70 这是一次失败的考试 string 想到和序列那个题很像,但我没做序列,考场回忆学 ...
- 测试开发之网络篇-IP地址
IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异.这里介绍一下目前广泛使用的IPv4版本. IP地址使用一种统一的格式,为互联 ...
- split截取字符串
一.根据单个分隔字符用split截取字符串:string st="GT123_1";split代码:string[] sArray=st.split("_"); ...
- Golang控制子gorutine退出,并阻塞等待所有子gorutine全部退出
Golang控制子gorutine退出,并阻塞等待所有子gorutine全部退出 需求 程序有时需要自动重启或者重新初始化一些功能,就需要退出之前的所有子gorutine,并且要等待所有子goruti ...
- golang变量与常量
变量 变量 在程序运行中可以改变的量 枚举 var ( a3 = 1 a4 = 2 ) golang不同类型变量不能替换 func main() { var a int = 10 a = 20 a = ...
- 02 jumpserver系统设置
2.系统设置: (1)基本设置: (2)邮件设置: 1)163邮箱设置: 2)在jumpserver上填写邮箱信息: 3)邮件测试信息如下: (3)邮件内容设置: (4)终端设置: (5)安全设置:
- 《手把手教你》系列技巧篇(七)-java+ selenium自动化测试-宏哥带你全方位吊打Chrome启动过程(详细教程)
1.简介 经过前边几篇文章和宏哥一起的学习,想必你已经知道了如何去查看Selenium相关接口或者方法.一般来说我们绝大多数看到的是已经封装好的接口,在查看接口源码的时候,你可以看到这个接口上边的注释 ...
- python base64(图片)编码
参考:https://blog.csdn.net/Good_Luck_Kevin2018/article/details/80953312 通常会在网页中遇到用src="data:image ...
- ms17-010 永恒之蓝漏洞复现(CVE-2017-0143)
0x01 首先对目标机的开放端口进行探测,我们可以使用探测神器nmap 发现开放的445端口,然后进行下一步的ms17-010的漏洞验证 0x02 打开MSF美少妇神器,用search命令搜索ms17 ...
- iPhone X适配方案
iPhone X适配方案 https://github.com/Wscats/iPhone-X 绝对长度单位 英寸 厘米 毫米 磅 pc inch cm mm pt pica 相对长度单位 是网页设计 ...