TCP 中的两个细节点
TCP 超时和重传
没有永远不出错误的通信,这句话表明着不管外部条件多么完备,永远都会有出错的可能。所以,在 TCP 的正常通信过程中,也会出现错误,这种错误可能是由于数据包丢失引起的,也可能是由于数据包重复引起的,甚至可能是由于数据包失序 引起的。
TCP 的通信过程中,会由 TCP 的接收端返回一系列的确认信息来判断是否出现错误,一旦出现丢包等情况,TCP 就会启动重传操作,重传尚未确认的数据。
TCP 的重传有两种方式,一种是基于时间,一种是基于确认信息,一般通过确认信息要比通过时间更加高效。
所以从这点就可以看出,TCP 的确认和重传,都是基于数据包是否被确认为前提的。
TCP 在发送数据时会设置一个定时器,如果在定时器指定的时间内未收到确认信息,那么就会触发相应的超时或者基于计时器的重传操作,计时器超时通常被称为重传超时(RTO)。
但是有另外一种不会引起延迟的方式,这就是快速重传。
TCP 在每次重传一次报文后,其重传时间都会加倍,这种"间隔时间加倍"被称为二进制指数补偿(binary exponential backoff) 。等到间隔时间加倍到 15.5 min 后,客户端会显示
Connection closed by foreign host.
TCP 拥有两个阈值来决定如何重传一个报文段,这两个阈值被定义在 RFC[RCF1122] 中,第一个阈值是 R1,它表示愿意尝试重传的次数,阈值 R2 表示 TCP 应该放弃连接的时间。R1 和 R2 应至少设为三次重传和 100 秒放弃 TCP 连接。
这里需要注意下,对连接建立报文 SYN 来说,它的 R2 至少应该设置为 3 分钟,但是在不同的系统中,R1 和 R2 值的设置方式也不同。
在 Linux 系统中,R1 和 R2 的值可以通过应用程序来设置,或者是修改 net.ipv4.tcp_retries1 和 net.ipv4.tcp_retries2 的值来设置。变量值就是重传次数。
tcp_retries2 的默认值是 15,这个充实次数的耗时大约是 13 - 30 分钟,这只是一个大概值,最终耗时时间还要取决于 RTO ,也就是重传超时时间。tcp_retries1 的默认值是 3 。
对于 SYN 段来说,net.ipv4.tcp_syn_retries 和 net.ipv4.tcp_synack_retries 这两个值限制了 SYN 的重传次数,默认是 5,大约是 180 秒。
Windows 操作系统下也有 R1 和 R2 变量,它们的值被定义在下方的注册表中
HKLM\System\CurrentControlSet\Services\Tcpip\Parameters
HKLM\System\CurrentControlSet\Services\Tcpip6\Parameters
其中有一个非常重要的变量就是 TcpMaxDataRetransmissions,这个 TcpMaxDataRetransmissions 对应 Linux 中的 tcp_retries2 变量,默认值是 5。这个值的意思表示的是 TCP 在现有连接上未确认数据段的次数。
快速重传
我们上面提到了快速重传,实际上快速重传机制是基于接收端的反馈信息来触发的,它并不受重传计时器的影响。所以与超时重传相比,快速重传能够有效的修复丢包情况。当 TCP 连接的过程中接收端出现乱序的报文(比如 2 - 4 - 3)到达时,TCP 需要立刻生成确认消息,这种确认消息也被称为重复 ACK。
当失序报文到达时,重复 ACK 要做到立刻返回,不允许延迟发送,此举的目的是要告诉发送方某段报文失序到达了,希望发送方指出失序报文段的序列号。
还有一种情况也会导致重复 ACK 发给发送方,那就是当前报文段的后续报文发送至接收端,由此可以判断当前发送方的报文段丢失或者延迟到达。因为这两种情况导致的后果都是接收方没有收到报文,但是我们却无法判断到底是报文段丢失还是报文段没有送达。因此 TCP 发送端会等待一定数目的重复 ACK 被接受来决定数据是否丢失并触发快速重传。一般这个判断的数量是 3,这段文字表述可能无法清晰理解,我们举个例子。
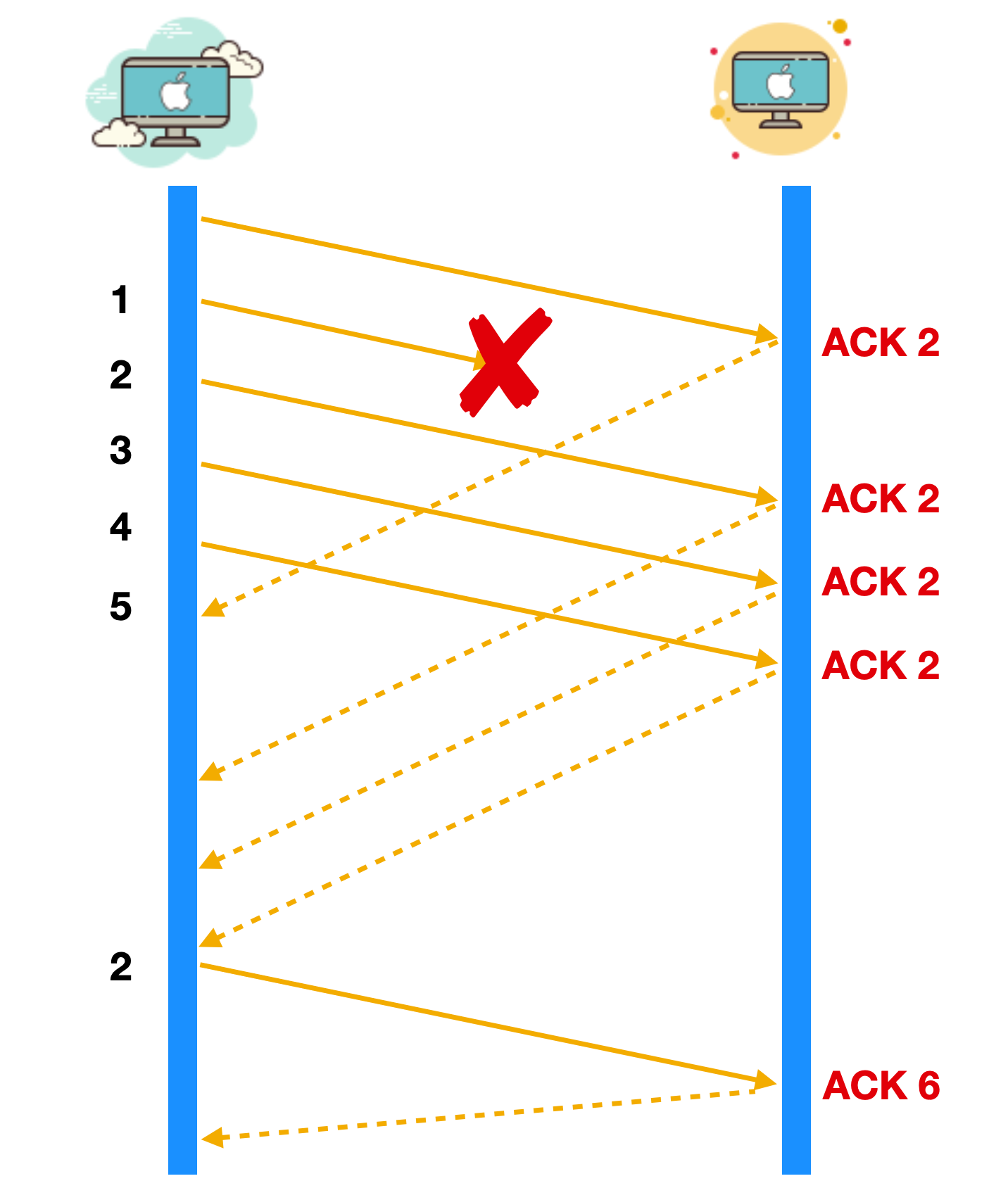
如上图所示,报文段 1 成功接收并被确认为 ACK 2,接收端的期待序号为 2,当报文段 2 丢失后,报文段 3。失序到达,但是与接收端的期望不匹配,所以接收端会重复发送冗余 ACK 2。
这样,在超时重传定时器到期之前,接收收到连续三个相同的 ACK 后,发送端就知道哪个报文段丢失了,于是发送方会重发这个丢失的报文段,这样就不用等待重传定时器的到期,大大提高了效率。
SACK
在标准的 TCP 确认机制中,如果发送方发送了 0 - 10000 序号之间的数据,但是接收方只接收到了 0 -1000, 3000 - 10000 之间的数据,而 1000 - 3000 之间的数据没有到达接收端,此时发送方会重传 1000 - 10000 之间的数据,实际上这是没有必要的,因为 3000 后面的数据已经被接收了。但是发送方无法感知这种情况的存在。
如何避免或者说解决这种问题呢?
为了优化这种情况,我们有必要让客户端知道更多的消息,在 TCP 报文段中,有一个 SACK 选项字段,这个字段是一种选择性确认(selective acknowledgment)机制,这个机制能告诉 TCP 客户端,用我们的俗语来解释就是:“我这里最多允许接收 1000 之后的报文段,但是我却收到了 3000 - 10000 的报文段,请给我 1000 - 3000 之间的报文段”。
但是,这个选择性确认机制的是否开启还受一个字段的影响,这个字段就是 SACK 允许选项字段,通信双方在 SYN 段或者 SYN + ACK 段中添加 SACK 允许选项字段来通知对端主机是否支持 SACK,如果双方都支持的话,后续在 SYN 段中就可以使用 SACK 选项了。
这里需要注意下:SACK 选项字段只能出现在 SYN 段中。
伪超时和重传
在某些情况下,即使没有出现报文段的丢失也可能会引发报文重传。这种重传行为被称为 伪重传(spurious retransmission) ,这种重传是没有必要的,造成这种情况的因素可能是由于伪超时(spurious timeout),伪超时的意思就是过早的判定超时发生。造成伪超时的因素有很多,比如报文段失序到达,报文段重复,ACK 丢失等情况。
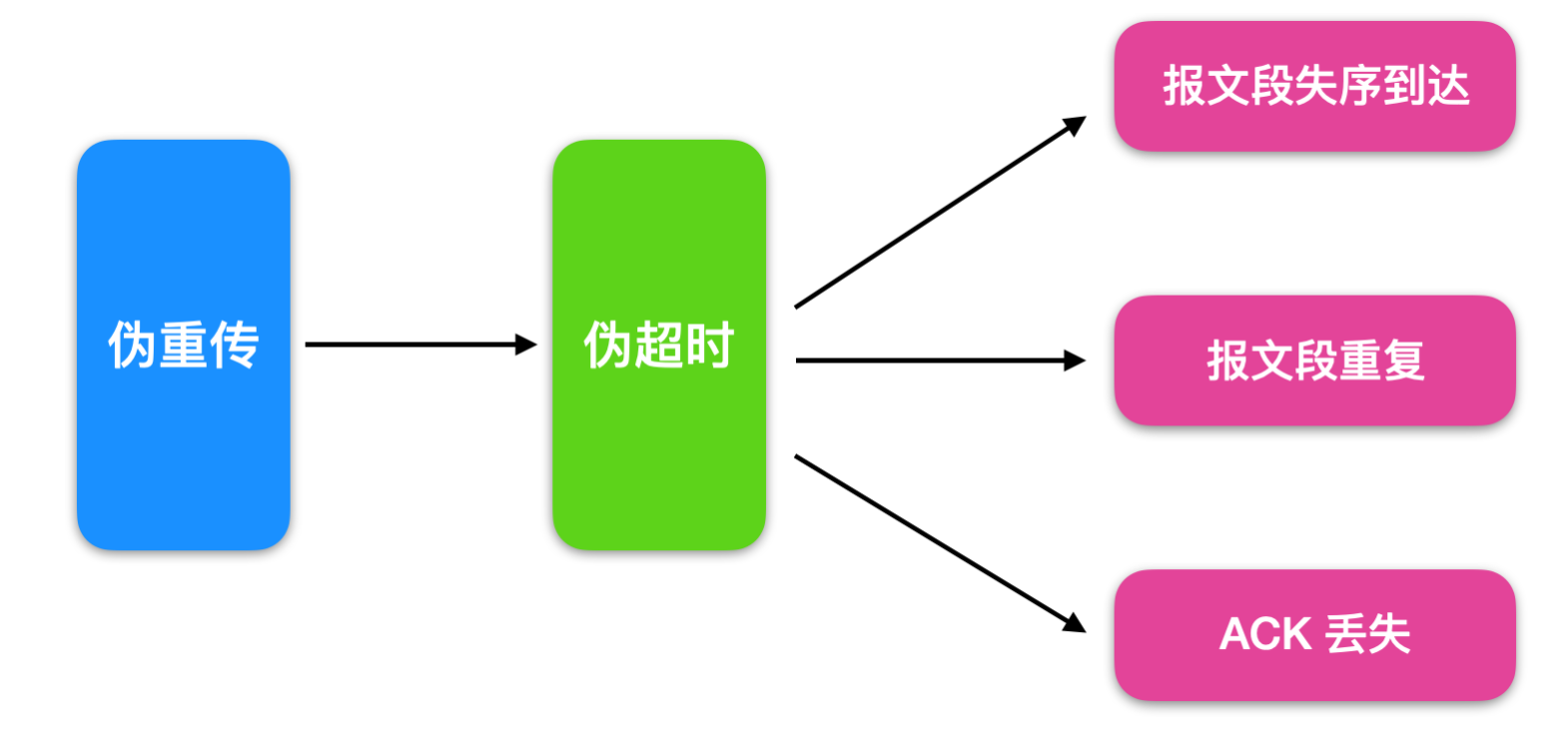
检测和处理伪超时的方法有很多,这些方法统称为检测算法和响应算法。检测算法用于判断是否出现了超时现象或出现了计时器的重传现象。一旦出现了超时或者重传的情况,就会执行响应算法撤销或者减轻超时带来的影响,下面是几种算法,此篇文章暂不深入这些实现细节
- 重复 SACK 扩展- DSACK
- Eifel 检测算法
- 前移 RTO 恢复 - F-RTO
- Eifel 响应算法
包失序和包重复
上面我们讨论的都是 TCP 如何处理丢包的问题,我们下面来讨论一下包失序和包重复的问题。
包失序
数据包的失序到达是互联网中极其容易出现的一种情况,由于 IP 层并不能保证数据包的有序性,每个数据包的发送都可能会选择当前情况传输速度最快的链路,所以很有可能出现发送了 A - > B -> C 的三个数据包,到达接收端的数据包顺序是 C -> A -> B 或者 B -> C -> A 等等。这就是包失序的一种现象。
在包传输中,主要分为两种链路:正向链路(SYN)和反向链路(ACK)
如果失序发生在正向链路,TCP 是无法正确判断数据包是否丢失的,数据的丢失和失序都会导致接收端收到无序的数据包,造成数据之间的空缺。如果这种空缺不够大的话,这种情况影响不大;但是如果空缺比较大的话,可能会导致伪重传。
如果失序发生在反向链路,就会使 TCP 的窗口前移,然后收到重复而应该被丢弃的 ACK,导致发送端出现不必要的流量突发,影响可用网络带宽。
回到我们上面讨论的快速重传,由于快速重传是根据重复 ACK 推断出现丢包而启动的,它不用等到重传计时器超时。由于 TCP 接收端会对接收到的失序报文立刻返回 ACK,所以网络中任何一个失序到达的报文都可能会造成重复 ACK。假设一旦收到 ACK,就会启动快速重传机制,当 ACK 数量激增,就会导致大量不必要的重传发生,所以快速重传应该达到重复阈值(dupthresh) 再触发。但是在互联网中,严重的失序并不常见,因此 dupthresh 的值可以设置的尽量小,一般来说 3 就能处理绝大部分情况。
包重复
包重复也是互联网中出现很少的一种情况,它指的是在网络传输过程中,包可能会出现传输多次的情况,当重传生成时,TCP 可能会出现混淆。
包的重复可以使接收端生成一系列的重复 ACK,这种情况可以使用 SACK 协商来解决。
TCP 中的两个细节点的更多相关文章
- LeetCode 24. Swap Nodes in Pairs(交换链表中每两个相邻节点)
题意:交换链表中每两个相邻节点,不能修改节点的val值. 分析:递归.如果以第三个结点为头结点的链表已经两两交换完毕(这一步递归实现---swapPairs(head -> next -> ...
- [程序员代码面试指南]二叉树问题-在二叉树中找到两个节点的最近公共祖先、[LeetCode]235. 二叉搜索树的最近公共祖先(BST)(非递归)
题目 题解 法一: 按照递归的思维去想: 递归终止条件 递归 返回值 1 如果p.q都不在root为根节点的子树中,返回null 2 如果p.q其中之一在root为根节点的子树中,返回该节点 3 如果 ...
- TCP中的RST复位信号
TCP中的RST复位信号 在TCP协议中RST表示复位,用来关闭异常的连接,在TCP的设计中它是不可或缺的. 发送RST包关闭连接时,不必等缓冲区的包都发出去,直接就丢弃缓存区的包发送RST包.而接收 ...
- 处于同一个域中的两台Sql server 实例无法连接
处于同一个域中的两台Sql server 实例无法连接,报的错误信息如下: A network-related or instance-specific error occurred while es ...
- Linux中的两种守护进程stand alone和xinetd
Linux中的两种守护进程stand alone和xinetd --http://www.cnblogs.com/itech/archive/2010/12/27/1914846.html#top 一 ...
- 剑指offer-第三章高质量的代码(输出该链表中倒数第K个节点)
题目:输入一个链表,输出这个链表中倒数第K个节点.(代码的鲁棒性) 思路:用两个指针p1和p2,都指向头节点,开始的时候,p2不动,p1移动k-1次,指向第k个节点.此时,如果p1->next! ...
- lintcode:Remove Nth Node From End of Lis 删除链表中倒数第n个节点
题目: 删除链表中倒数第n个节点 给定一个链表,删除链表中倒数第n个节点,返回链表的头节点. 样例 给出链表1->2->3->4->5->null和 n = 2. 删除 ...
- TCP/IP源码(59)——TCP中的三个接收队列
http://blog.chinaunix.net/uid-23629988-id-3482647.html TCP/IP源码(59)——TCP中的三个接收队列 作者:gfree.wind@gmai ...
- 19 Remove Nth Node From End of List(去掉链表中倒数第n个节点Easy)
题目意思:去掉链表中倒数第n个节点 思路:1.两次遍历,没什么技术含量,第一次遍历计算长度,第二次遍历找到倒数第k个,代码不写了 2.一次遍历,两个指针,用指针间的距离去计算. ps:特别注意删掉 ...
随机推荐
- 14、运行Django时浏览器中遇到Refused to display 'url' in a frame because it set 'X-Frame-Options' to 'deny'
问题:Refused to display 'url' in a frame because it set 'X-Frame-Options' to 'deny' 解决办法: 只需要在 Djagno ...
- AttributeError: 'str' object has no attribute 'lowerr' Python常见错误
方法名拼写错误 检查方法名拼写,如有错误改正即可 特别注意m和n
- 第14 章 : Kubernetes Service讲解
Kubernetes Service 本文将主要分享以下四方面的内容: 为什么需要 K8s service: K8s service 用例解读: K8s service 操作演示: K8s servi ...
- 生产中使用ssh-copy-id复制公钥到多台服务器
在系统运维的时候,可能免密码通过ssh方式登录到远程主机,这时就首先需要将本机的公钥复制到远程主机,用 ssh-copy-id 命令可以轻松做到. 对于单台远程主机,直接使用命令就可以了 # 生成密钥 ...
- 【算法学习笔记】组合数与 Lucas 定理
卢卡斯定理是一个与组合数有关的数论定理,在算法竞赛中用于求组合数对某质数的模. 第一部分是博主的个人理解,第二部分为 Pecco 学长的介绍 第一部分 一般情况下,我们计算大组合数取模问题是用递推公式 ...
- H5 端 rem 适配方案与 viewport 适配
H5 端 rem 适配方案与 viewport 适配 rem rem 是 CSS3 新增的一个相对单位(root em,根 em) 只根据当前页面 HTML 页面的 font-size 设置,如果根目 ...
- 死磕Spring之AOP篇 - Spring AOP自动代理(二)筛选合适的通知器
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读. Spring 版本:5.1 ...
- Day14_83_反射机制获取某个特定属性的各部分
反射机制获取某个特定属性的各部分 * 通过属性名(变量名)来获取一个属性整体 例如: Field userNoField=c.getDeclaredField("userNo"); ...
- 网关Ocelot功能演示完结,久等了~~~
前言 关于网关(Ocelot)的分享,还遗留一些功能没演示呢,接着来聊聊:这次重点针对网关Ocelot使用缓存.集成Polly做服务治理.集成IdentityServer4做认证授权来详细说说:如果对 ...
- 03- Linux目录与文件进阶操作
第三课 目录与文件进阶操作cat (一次性全部输出文件内容) cat -n 文件名 显示行号 cat -b 文件名 空行不显示行号less (分页显示,可以上下翻页,光标键上下键,PageUp ...