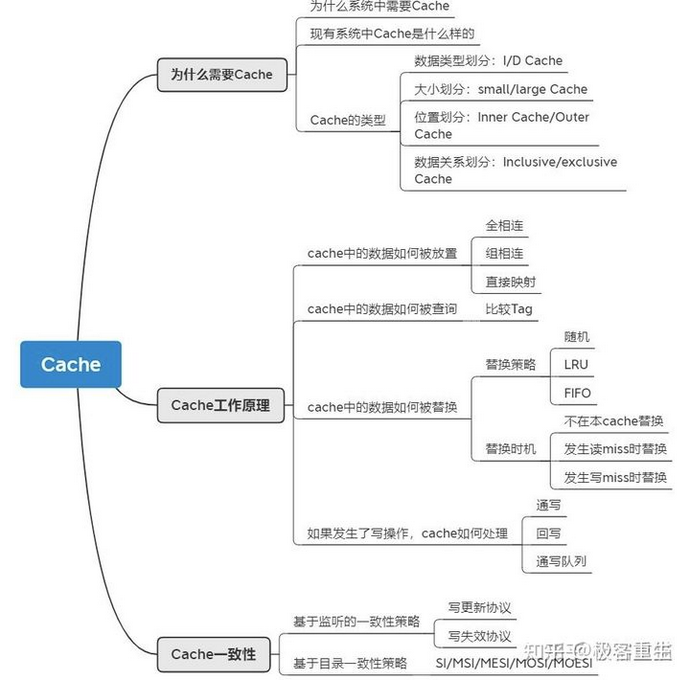
深入理解Cache工作原理
内容来源:https://zhuanlan.zhihu.com/p/435031232
内容来源:https://zhuanlan.zhihu.com/p/102293437
本文主要内容如下,基本涉及了Cache的概念,工作原理,以及保持一致性的入门内容。
一、CPU缓存是什么?
总结起来,Cache是为了给CPU提供高速存储访问,利用数据局部性而设计的小存储单元。
CPU缓存(Cache Memory)也就高速缓冲存储器是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
当CPU需要读取数据并进行计算时,首先需要将CPU缓存中查到所需的数据,并在最短的时间下交付给CPU。如果没有查到所需的数据,CPU就会提出“要求”经过缓存从内存中读取,再原路返回至CPU进行计算。而同时,把这个数据所在的数据也调入缓存,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
缓存大小是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是从CPU芯片面积和成本的因素来考虑,缓存都很小。
二 为什么需要 Cache
1、cpu速度快于内存读写速度100多倍。为了避免内存成为 CPU 速度的瓶颈,
我们首先从一张图来开始讲为什么需要 Cache.
根据摩尔定律,CPU 的访问速度每 18 个月就会翻倍,相当于每年增长 60% 左右,内存的速度当然也会不断增长,但是增长的速度远小于 CPU,平均每年只增长 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。
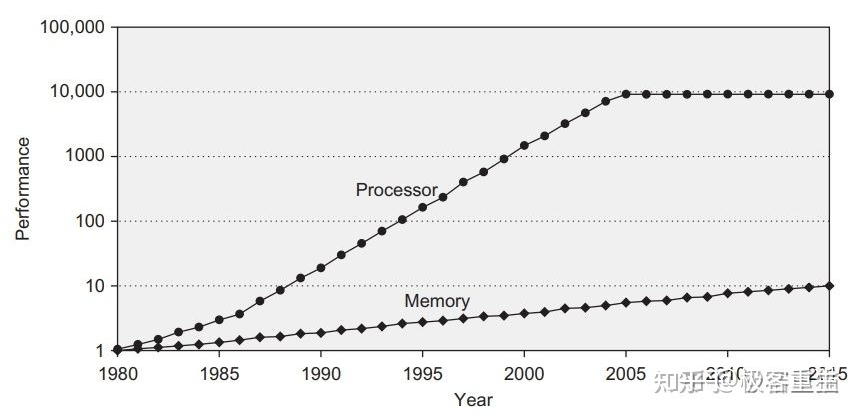
上图是 CPU 性能和 Memory 存储器访问性能的发展。
我们可以看到,随着工艺和设计的演进,CPU 计算性能其实发生了翻天覆地的变化,但是DRAM存储性能的发展没有那么快。
所以造成了一个问题,存储限制了计算的发展。
容量与速度不可兼得。
2、程序处理的数据有局部性
如何解决这个问题呢?可以从计算访问数据的规律入手。
我们随便贴段代码:
for (j = 0; j < 100; j = j + 1)
for( i = 0; i < 5000; i = i + 1)
x[i][j] = 2 * x[i][j];
可以看到,由于大量循环的存在,我们访问的数据其实在内存中的位置是相近的。
主要是利用到大部分的程序,在处理数据时,都有一定程度的区域性。
换句专业点的话说,我们访问的数据有局部性。
大部分的程序,在处理数据时,都有一定程度的区域性。所以,我们可以用一小块快速的内存,来暂存目前需要的数据。
3、cpu多核和多线程技术的发展。数据的状态需要在多个CPU进行同步
4、因为成为问题所以缓存比较小,1mb内存成本是0.01美元。1mb缓存成本是7美元
三、CPU一级缓存、二级缓存、三级缓存是什么意思?
大家都知道现在CPU的多核技术,都会有几级缓存,现在的CPU会有三级内存(L1,L2, L3),如下图所示:
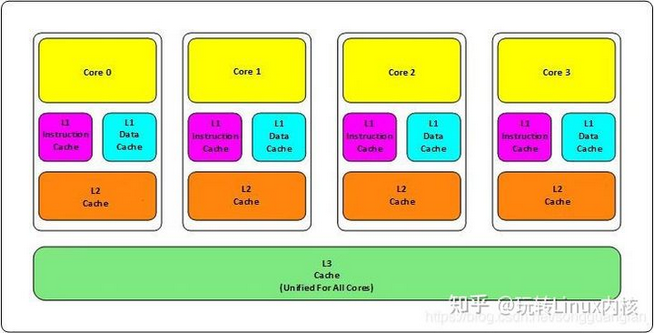
CPU一级缓存、二级缓存、三级缓存是什么意思?
一级缓存(L1 Cache)
CPU一级缓存,就是指CPU的第一层级的高速缓存,主要当担的工作是缓存指令和缓存数据。一级缓存的容量与结构对CPU性能影响十分大,但是由于它的结构比较复杂,又考虑到成本等因素,一般来说,CPU的一级缓存较小,通常CPU的一级缓存也就能做到256KB左右的水平。L1缓存分成两种,一种是指令缓存,一种是数据缓存.L1 cache一般工作在CPU的时钟频率,要求的就是够快
在L1缓存中,又有一个叫做Cache line的东西。为了提升处理速度,CPU每次处理都是读取一个Cache line大小的数据。
Cache line:cpu从一级缓存读取数据的最小单位
补充:鲁大师》硬件参数》处理器 ,可以查看电脑的 Cache line 大小,本人电脑是64 byte

二级缓存(L2 Cache)
CPU二级缓存,就是指CPU的第二层级的高速缓存,而二级缓存的容量会直接影响到CPU的性能,二级缓存的容量越大越好。例如intel的第八代i7-8700处理器,共有六个核心数量,而每个核心都拥有256KB的二级缓存,属于各核心独享,这样二级缓存总数就达到了1.5MB。
三级缓存(L3 Cache)
CPU三级缓存,就是指CPU的第三层级的高速缓存,其作用是进一步降低内存的延迟,同时提升海量数据量计算时的性能。和一级缓存、二级缓存不同的是,三级缓存是核心共享的,能够将容量做的很大。
///////题外话1 开始///////////////////////////////////////
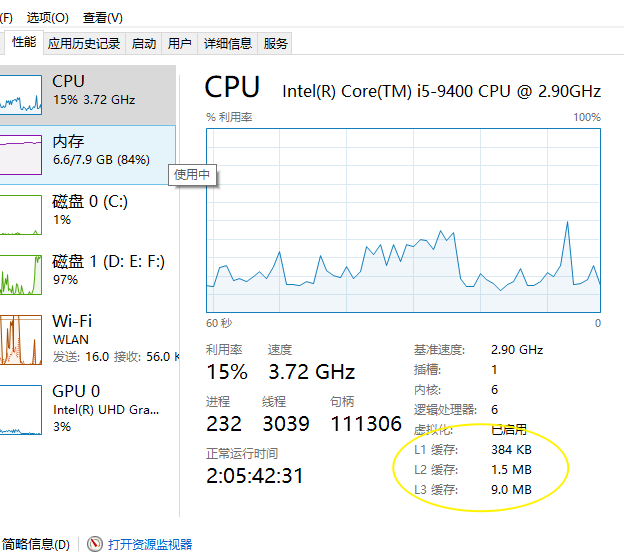
题外话:如何查看个人电脑cpu缓存?答案 查看任务管理器
下图我本人的cpu缓存 L1:384K=6核* 64K/核。64K=32K 数据缓存+32K 指令缓存
L2:1.5MB=256K/核*/6核
L3:9MB是共享的。
///////题外话1 结束///////////////////////////////////////
其中:
- L1缓存分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。在L1缓存中,有一个叫做Cache line的东西。 他表示cpu从一级缓存读取数据的最小单位。
- L1和L2缓存在每一个CPU核中,L3则是所有CPU核心共享的内存。
- L1、L2、L3的越离CPU近就越小,速度也就越快,越离CPU远,速度也越慢。
再往后面就是内存,内存的后面就是硬盘。我们来看一些他们的速度
- L1的存取速度:4个CPU时钟周期
- L2的存取速度:11个CPU时钟周期
- L3的存取速度:39个CPU时钟周期
- RAM内存的存取速度:107个CPU时钟周期
- 固态硬盘访问10-100us
- 机械硬盘访问1-10ms
这边4个cpu周期,中时许电路中Latency (延迟)。
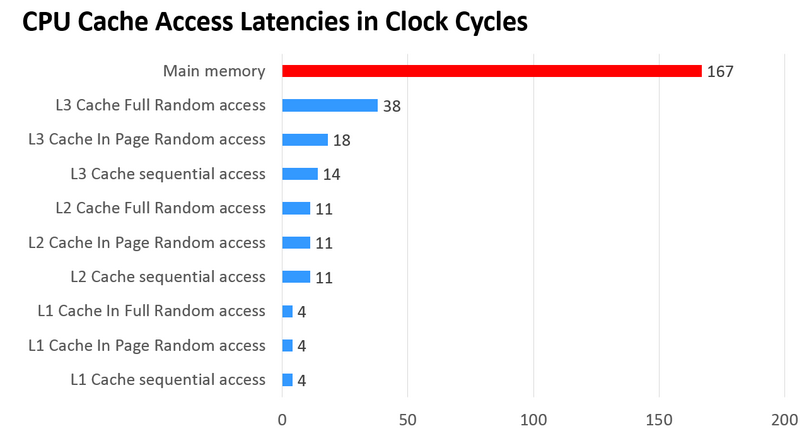
我们可以看到,L1的速度是RAM的27倍,L1和L2的存取大小基本上是KB级的,L3则是MB级别的。例如,Intel Core i7-8700K,是一个6核的CPU,每核上的L1是64KB(数据和指令各32KB),L2是256K,L3有2MB。
四、为什么设置多级缓存
我们的数据从内存向上,先到L3,再到L2,再到L1,最后到寄存器进行计算。那么,为什么会设计成三层?这里有以下几方面的考虑:
物理速度,如果要更大的容量就需要更多的晶体管,除了芯片的体积会变大,更重要的是大量的晶体管会导致速度下降,因为访问速度和要访问的晶体管所在的位置成反比。也就是当信号路径变长时,通信速度会变慢,这就是物理问题。
另外一个问题是,多核技术中,数据的状态需要在多个CPU进行同步。我们可以看到,cache和RAM的速度差距太大。所以,多级不同尺寸的缓存有利于提高整体的性能。
这个世界永远是平衡的,一面变得有多光鲜,另一方面也会变得有多黑暗,建立多级的缓存,一定就会引入其它的问题。这里有两个比较重要的问题。
一个是比较简单的缓存命中率的问题,另一个是比较复杂的缓存更新的一致性问题
尤其是第二个问题,在多核技术下,这就很像分布式系统了,要面对多个地方进行更新。
/////////////////////题外话2 开始///////////////////////
1 MB 大小的 CPU Cache 需要 7 美金的成本,而内存只需要 0.015 美金的成本,成本方面相差了 466 倍,所以 CPU Cache 不像内存那样动辄以 GB 计算,它的大小是以 KB 或 MB 来计算的。
为了解决这一问题,CPU设置了多级缓存结构
其中较为典型的有L1,L2,L3高速缓存
其中L1高速缓存具有和寄存器差不多的速度。
L1,L2,L3缓存都位于芯片内部,这些缓存我们统称为Cache
/////////////////////题外话2 结束///////////////////////
Cache高速缓冲存储器写机制
1.write through:Write-through(直写模式)在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
2. write back:(回写模式)在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
对于写操作,存在写入缓存缺失数据的情况,这时有两种处理方式:
Write allocate方式将写入位置读入缓存,然后采用write-hit(缓存命中写入)操作。写缺失操作与读缺失操作类似。
No-write allocate方式并不将写入位置读入缓存,而是直接将数据写入存储。这种方式下,只有读操作会被缓存。
无论是Write-through还是Write-back都可以使用写缺失的两种方式之一。只是通常Write-back采用Write allocate方式,而Write-through采用No-write allocate方式;因为多次写入同一缓存时,Write allocate配合Write-back可以提升性能;而对于Write-through则没有帮助。
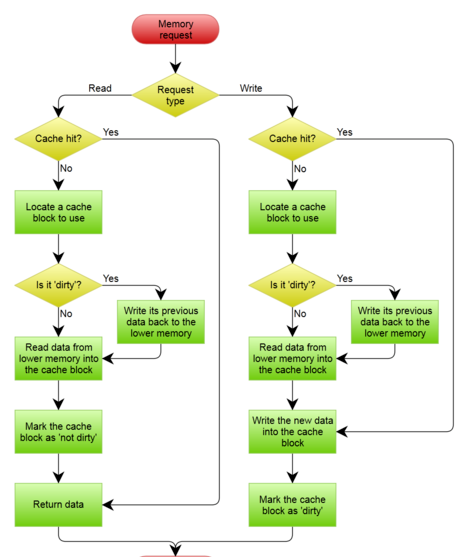
处理流程图
Write-through模式处理流程:

A Write-Through cache with No-Write Allocation
Write-back模式处理流程:
CPU缓存一致性协议MESI
深入理解Cache工作原理的更多相关文章
- Linux内核设计第一周 ——从汇编语言出发理解计算机工作原理
Linux内核设计第一周 ——从汇编语言出发理解计算机工作原理 作者:宋宸宁(20135315) 一.实验过程 图1 编写songchenning5315.c文件 图2 将c文件汇编成32位机器语言 ...
- Linux内核设计(第一周)——从汇编语言出发理解计算机工作原理
Linux内核设计(第一周)——从汇编语言出发理解计算机工作原理 计算机工作原理 汇编指令 C语言代码汇编分析 by苏正生 原创作品转载请注明出处 <Linux内核分析>MOOC课程htt ...
- yum服务器搭建(深入理解yum工作原理)
作者:firefoxbug 时间:July 27, 2014 分类:Linux 前言 在前面一篇rpm包制作描述了rpm的打包过程,这篇文章主要讲述yum的工作原理. yum 运行原理 yum的工作需 ...
- 通过一个小故事,理解 HTTPS 工作原理
本文摘录参考: 细说 CA 和证书(主要讲解 CA 的使用) 数字签名是什么?(简单理解原理) 深入浅出 HTTPS 工作原理(深入理解原理) HTTP 协议由于是明文传送,所以存在三大风险: 1.被 ...
- 深入理解yum工作原理
前言 在前面一篇rpm包制作描述了rpm的打包过程,这篇文章主要讲述yum的工作原理. yum 运行原理 yum的工作需要两部分来合作,一部分是yum服务器,还有就是client的yum工具.下面分别 ...
- 理解 HTTPS 工作原理(公钥、私钥、签名、数字证书、加密、认证)(转)
本文摘录参考: 细说 CA 和证书(主要讲解 CA 的使用) 数字签名是什么?(简单理解原理) 深入浅出 HTTPS 工作原理(深入理解原理) HTTP 协议由于是明文传送,所以存在三大风险: 1.被 ...
- 理解Tomcat工作原理
WEB服务器 只要Web上的Server都叫Web Server,但是大家分工不同,解决的问题也不同,所以根据Web Server提供的功能,每个Web Server的名字也会不一样. 按功能分类,W ...
- Linux系统的Cache工作原理和管理机制
Linux系统Cache 管理是 Linux 内核中一个很重要并且较难理解的组成部分.本文详细介绍了 Linux 内核中文件 Cache 管理的各个方面,希望能够帮助到你. 操作系统和文件 Cache ...
- 自我理解foreach工作原理
很多时候我们在使用for循环遍历一个数组的时候,我们都知道可以通过下标的索引找到当前数组中所对应的数据.这只对于简单的数组或集合,如果我们存储的数据不止只有数据项,还有一个标识项,就如同Has ...
随机推荐
- Cesium中级教程3 - Camera - 相机(摄像机)
Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ Camera CesiumJS中的Camera控制场景的视图.有 ...
- vue学习13-自定义组件
1 <!DOCTYPE html> 2 <html lang='en'> 3 <head> 4 <meta charset='UTF-8'> 5 < ...
- 前端基础之javaScript(基本类型-布尔值数组-if-while)
目录 一:javaScript基本数据类型 1.字符串类型常用方法 2.返回长度 3.移出空白 4.移除左边的空白 5.移出右边的空格 6.返回第n个字符 7.子序列位置 8.根据索引获取子序列 9. ...
- python matplotlib通过 plt.scatter在图上画圆
import matplotlib.pyplot as plt lena = mpimg.imread(r'C:\Users\Administrator.WIN-QV9HPTF0DHS\Desktop ...
- STS中创建 javaweb 项目?
package com.aaa.readme; /* * 一. * 1.安装Tomcat 版本8.5 * * 2.file---->new------>dynamic java web p ...
- 别人都在认真听课,而我埋头写Python为主播疯狂点点点点点赞!
最近有次在钉钉看直播,发现这个直播非常之精彩,于是情不自禁地想要为主播大佬连刷一波赞: 但我发现,手动连击点赞速度十分不可观.气人的是,钉钉直播不能长按刷赞!这让我很恼怒.心中满怀的激动和兴奋以及对大 ...
- 一次SQL查询优化原理分析(900W+数据,从17s到300ms) (转)
有一张财务流水表,未分库分表,目前的数据量为9555695,分页查询使用到了limit,优化之前的查询耗时16 s 938 ms (execution: 16 s 831 ms, fetching: ...
- Docker容器启动失败 Failed to start Docker Application Container Engine
1.在k8s mster节点执行 1.kubectl get nodes 发现node节点没起来 [root@guanbin-k8s-master ~]# kubectl get nodes NAME ...
- 1、interface/implements 接口与引用
转载请注明来源:https://www.cnblogs.com/hookjc/ 1.类中全部为抽象方法 2.抽象方法前不用加abstract 3.接口抽象方法属性为public 4.成员属性必须为常量 ...
- laravel操作Redis排序/删除/列表/随机/Hash/集合等方法全解
Song • 3563 次浏览 • 0 个回复 • 2017年10月简介 Redis模块负责与Redis数据库交互,并提供Redis的相关API支持: Redis模块提供redis与redis.con ...