Understanding and Improving Fast Adversarial Training
概
本文主要探讨:
- 为什么简单的FGSM不能够提高鲁棒性;
- 为什么FGSM-RS(即加了随机扰动)可以更好地提高鲁棒性;
- 一种正则化方法, 即使不加随机扰动亦可提高鲁棒性.
主要内容
对抗训练是迄今最有效的防御手段, 其思想为:
\]
为了求解inner maximum, 一般通过PGD来近似求解. 但是这种multi-steps的方法很耗时, 所以最近也有一些方法基于FGSM进行一些改进, 其发现是FGSM在额外加一个扰动之后可以有效提高网络鲁棒性:
\]
但是作者发现这种方法所带来的鲁棒性作用范围(\(\epsilon\))非常狭窄:
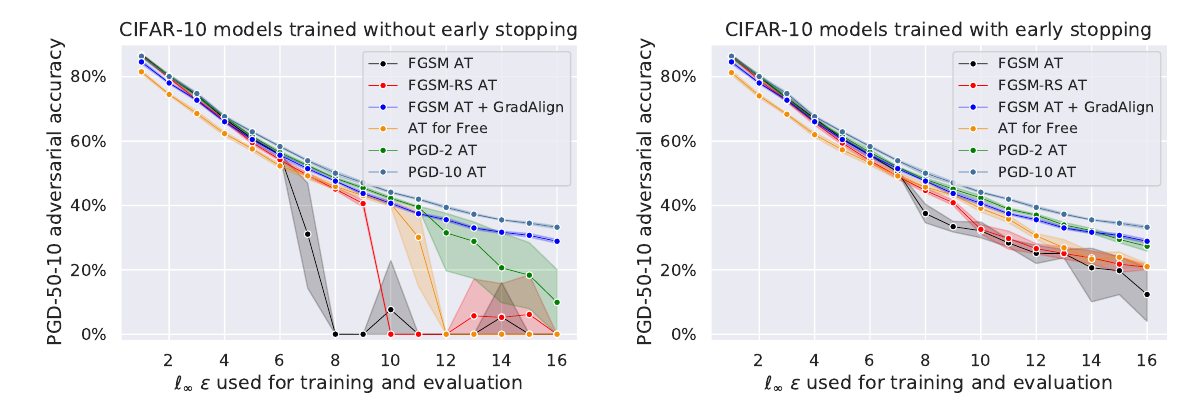
其和FGSM-AT一样, 会在某个点鲁棒性突然崩溃, 没有很好的扩展性.
Random Step的作用
为什么RS能起到一定作用, 作者认为实际上加了RS之后, \(\epsilon\)在某种意义是'变小'了,
作者推得
\]
特别的, 作者设定小的\(\epsilon\)试了(且不加RS)发现能与加了RS效果一致:

线性性质
接下来作者提出自己的观点, 剖析FGSM为啥有这些异常的情况出现.
作者认为一开始FGSM是对于inner maximum求解是较为准确的, 但是随着训练的深入, 不准确了, 为什么不准确, 作者认为是\(\ell(x;\theta)\)关于\(x\)并不那么线性了.
我们知道, FGSM实际上是对于线性情况的最优解:
\]
当\(\ell\)在\(\epsilon\)球内不那么线性的时候, 这个解就不好了, 可以通过下面的条件来衡量是否线性:
\]

如上图所示, 普通的FGSM和FGSM-RS在训练过程中越发变得局部非线性, 所以求解越来越差.
gradient alignment
本文提出的解决方法就是利用上述的条件作为一个正则化项.
个人感觉这个正则化条件比以往的想法子让梯度变小更有趣一点(不局限于光滑性之上).
代码
Understanding and Improving Fast Adversarial Training的更多相关文章
- Adversarial Training
原于2018年1月在实验室组会上做的分享,今天分享给大家,希望对大家科研有所帮助. 今天给大家分享一下对抗训练(Adversarial Training,AT). 为何要选择这个主题呢? 我们从上图的 ...
- 《C-RNN-GAN: Continuous recurrent neural networks with adversarial training》论文笔记
出处:arXiv: Artificial Intelligence, 2016(一年了还没中吗?) Motivation 使用GAN+RNN来处理continuous sequential data, ...
- LTD: Low Temperature Distillation for Robust Adversarial Training
目录 概 主要内容 Chen E. and Lee C. LTD: Low temperature distillation for robust adversarial training. arXi ...
- Adversarial Training with Rectified Rejection
目录 概 主要内容 rejection 实际使用 代码 Pang T., Zhang H., He D., Dong Y., Su H., Chen W., Zhu J., Liu T. Advers ...
- Boosting Adversarial Training with Hypersphere Embedding
目录 概 主要内容 代码 Pang T., Yang X., Dong Y., Xu K., Su H., Zhu J. Boosting Adversarial Training with Hype ...
- Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples 目录 概 主要内容 实验 ...
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- cs231n spring 2017 lecture16 Adversarial Examples and Adversarial Training 听课笔记
(没太听明白,以后再听) 1. 如何欺骗神经网络? 这部分研究最开始是想探究神经网络到底是如何工作的.结果人们意外的发现,可以只改变原图一点点,人眼根本看不出变化,但是神经网络会给出完全不同的答案.比 ...
- cs231n spring 2017 lecture16 Adversarial Examples and Adversarial Training
(没太听明白,以后再听) 1. 如何欺骗神经网络? 这部分研究最开始是想探究神经网络到底是如何工作的.结果人们意外的发现,可以只改变原图一点点,人眼根本看不出变化,但是神经网络会给出完全不同的答案.比 ...
随机推荐
- IDEA高颜值之最吸引小姐姐插件集合!让你成为人群中最靓的那个崽!
经常有小伙伴会来找TJ君,可能觉得TJ君比较靠谱,要TJ君帮忙介绍女朋友.TJ君一直觉得程序猿是天底下最可爱的一个群体,只不过有时候不善于表达自己的优秀,所以TJ君今天准备介绍几款酷炫实用的IDEA插 ...
- nuxt.js相关随笔
对于nuxt.js从未接触,对于项目需要进行零散了解,作此归纳,以下都是一个新手的拙见与理解,有不同意见欢迎提出,但请勿喷. 一.项目创建 npx create-nuxt-app projectNam ...
- Oracle数据库导入与导出方法简述
说明: 1.数据库数据导入导出方法有多种,可以通过exp/imp命令导入导出,也可以用第三方工具导出,如:PLSQL 2.如果熟悉命令,建议用exp/imp命令导入导出,避免第三方工具版本差异引起的问 ...
- Stream collect Collectors 常用详细实例
返回List集合: toList() 用于将元素累积到List集合中.它将创建一个新List集合(不会更改当前集合). List<Integer> integers = Arrays.as ...
- 【JAVA】【基础知识】Java程序执行过程
1. Java程序制作过程 使用文本编辑器进行编辑 2. 编译源文件,生成class文件(字节码文件) javac源文件路径. 3.运行程序class文件.
- centos7源码安装Nginx-1.6
目录 一.环境介绍 二.安装 三.使用验证 四.附录 编译参数详解 一.环境介绍 nginx的版本功能相差不大,具体支持可以查看官网的功能列表 环境信息: [nginx-server] 主机名:hos ...
- 学习整理--vue篇(1)
vue学习 vue指令 模板指令: v-model:绑定data数据实现数据双向绑定 v-html:绑定模板内容,可书写标签 v-text:绑定数据实现单向绑定 可缩写为{{}} 支持逻辑运算 可结合 ...
- 转:KVC 与 KVO 理解
KVC 与 KVO 理解 On 2012 年 6 月 7 日, in iPhone, by donly KVC 与 KVO 是 Objective C 的关键概念,个人认为必须理解的东西,下面是实例讲 ...
- 『学了就忘』Linux系统管理 — 84、Linux中进程的管理
目录 1.Linux系统中的信号 2.杀掉进程的命令 (1)kill命令 (2)killall命令 (3)pkill命令 1.Linux系统中的信号 Linux系统中可以识别的信号较多,我们可以使用命 ...
- [BUUCTF]PWN——others_shellcode
others_shellcode 附件 解题步骤: 例行检查,32位程序,开启了NX(堆栈不可执行)和PIE(地址随机化)双重保护 试运行了一下,发现直接就能执行shell的命令 远程连接运行一下,直 ...