Python+Requests+异步线程池爬取视频到本地
1、本次项目为获取梨视频中的视频,再使用异步线程池下载视频到本地
2、获取视频时,其地址中的Url是会动态变化,不播放时src值为图片的地址,播放时src值为mp4格式
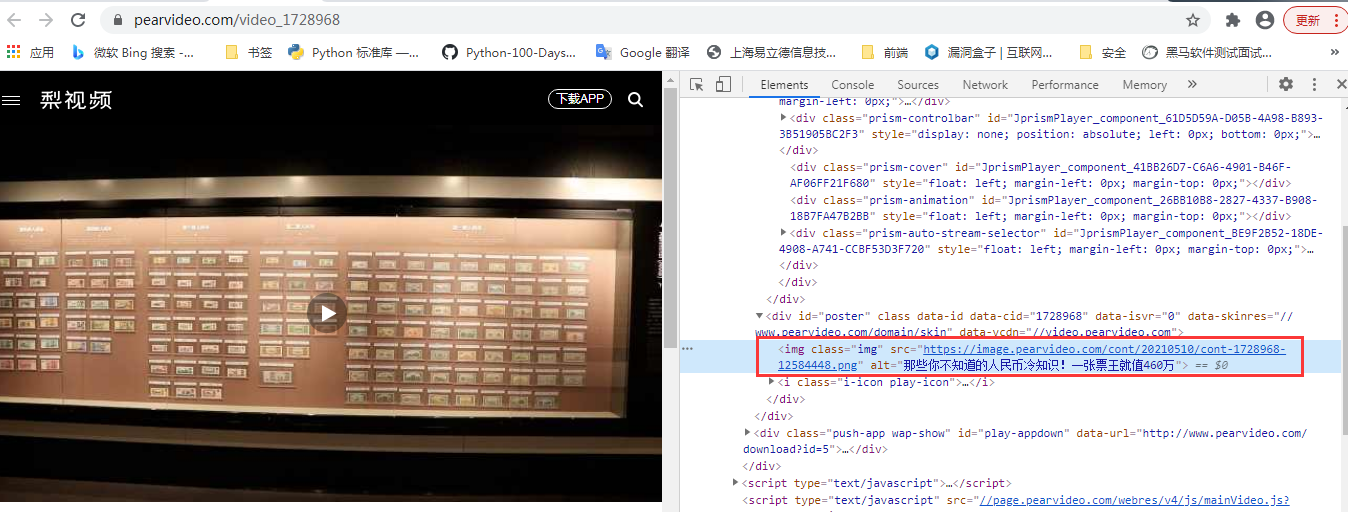

3、查看视频链接是否存在ajax,果然是存在的,但是返回的Url与真实的MP4地址存在部分不一致,此时需要使用字符串替换
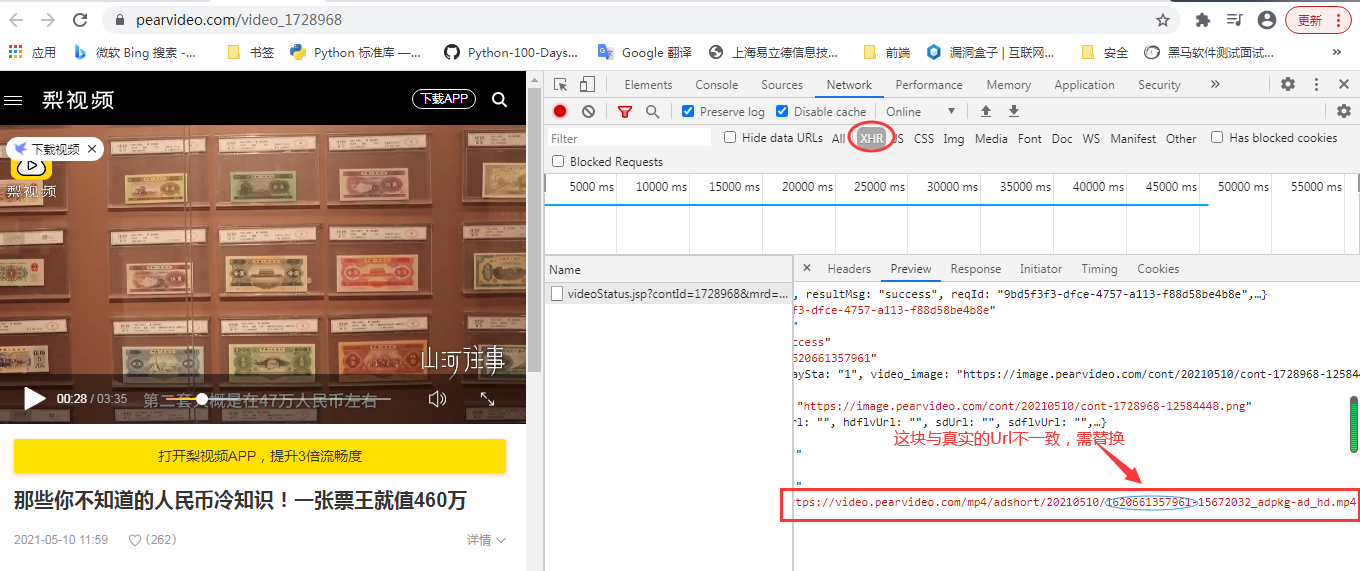
4、获取到真实的mp4视频地址后,再使用二进制流的方式进行下载到本地
5、使用Pool(4),四个线程池进行异步下载,互不干扰
6、源码如下:
import os
import requests
from lxml import etree
import random
import re
#安装fake-useragent库:pip install fake-useragent
from fake_useragent import UserAgent
#导入线程池模块
from multiprocessing.dummy import Pool
# 新建文件存储视频
if not os.path.exists('./threadFile'):
os.makedirs('./threadFile')
session = requests.Session()
# 存储所有视频的Url及标题
video_urls = []
# 梨视频Url
url = 'https://www.pearvideo.com/'
UA = UserAgent().random
headers = {
'User-Agent':UA
}
# 获取首页页面数据
page_text = session.get(url=url,headers=headers).text
#对获取的首页页面数据中的相关视频详情链接进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="vervideoTlist"]/div/ul/li')
for li in li_list:
# 视频详情页的Url
detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
# 视频详情页的Title
detail_title = li.xpath('./div/a/div[2]/div[2]/text()')[0]+'.mp4'
page_text = session.get(url=detail_url,headers=headers).text
# 字符串切割为value值
value = str("".join(li.xpath('./div/a/@href')[0]).split('_')[-1])
# 由于存在ajax则使用新的请求地址
headers_new = {
'User-Agent': UA,
'Referer': 'https://www.pearvideo.com/video_{}'.format(value)
}
detail_url_new = "https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}".format(value,float(random.random()))
detail_text = session.get(url=detail_url_new,headers=headers_new)
url = detail_text.json()['videoInfo']['videos']['srcUrl']
ER = '//(.*?)-'
list_url= re.findall(ER,url)
for url1 in list_url:
if url1.split('/')[-1] in url:
url = url.replace(url1.split('/')[-1],'cont-{}'.format(value))
else:
print('替换失败')
dic = {
"url":url,
"title":detail_title
}
video_urls.append(dic)
# 对视频链接发起请求获取视频的二进制数据,然后将视频数据返回
def get_video(dic):
print(dic['title'],'正在下载....')
page_content = session.get(url=dic['url'],headers=headers).content
fileName = './threadFile/'+dic['title']
# 持久化存储数据
with open(fileName,'wb') as fp:
fp.write(page_content)
print(dic['title'], '下载完成!!!')
#实例化线程池对象
# 使用线程池对视频数据进行请求(较为耗时阻塞的操作)
pool = Pool(4)
pool.map(get_video,video_urls)
# 关闭线程池
pool.close()
pool.join()
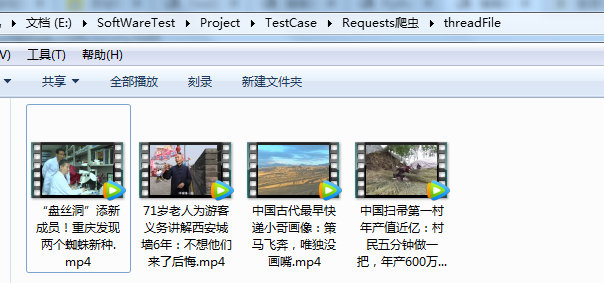
7、下载本地
Python+Requests+异步线程池爬取视频到本地的更多相关文章
- 基于requests模块的cookie,session和线程池爬取
目录 基于requests模块的cookie,session和线程池爬取 基于requests模块的cookie操作 基于requests模块的代理操作 基于multiprocessing.dummy ...
- 使用requests、BeautifulSoup、线程池爬取艺龙酒店信息并保存到Excel中
import requests import time, random, csv from fake_useragent import UserAgent from bs4 import Beauti ...
- 使用requests、re、BeautifulSoup、线程池爬取携程酒店信息并保存到Excel中
import requests import json import re import csv import threadpool import time, random from bs4 impo ...
- Python爬取视频指南
摘自:https://www.jianshu.com/p/9ca86becd86d 前言 前两天尔羽说让我爬一下菜鸟窝的教程视频,这次就跟大家来说说Python爬取视频的经验 正文 https://w ...
- py3+requests+re+urllib,爬取并下载不得姐视频
实现原理及思路请参考我的另外几篇爬虫实践博客 py3+urllib+bs4+反爬,20+行代码教你爬取豆瓣妹子图:http://www.cnblogs.com/UncleYong/p/6892688. ...
- python day 20: 线程池与协程,多进程TCP服务器
目录 python day 20: 线程池与协程 2. 线程 3. 进程 4. 协程:gevent模块,又叫微线程 5. 扩展 6. 自定义线程池 7. 实现多进程TCP服务器 8. 实现多线程TCP ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- 进程池爬取并存入mongodb
设置进程池爬取拉钩网: # coding = utf- import json import pymongo import pandas as pd import requests from lxml ...
随机推荐
- Django(64)频率认证源码分析与自定义频率认证
前言 有时候我们发送手机验证码,会发现1分钟只能发送1次,这是做了频率限制,限制的时间次数,都由开发者自己决定 频率认证源码分析 def check_throttles(self, request): ...
- 【NX二次开发】Block UI 选项卡控件
[NX二次开发]Block UI 选项卡控件
- 【C++】枚举类型(enum )
定义枚举类型的主要目的是:增加程序的可读性.枚举类型最常见也最有意义的用处之一就是用来描述状态量.枚举类型数据的其他处理也往往应用switch语句,以保证程序的合法性和可读性.枚举值是常量不是变量,不 ...
- JavaScript中基本数据类型和引用数据类型的区别(栈——堆)
JavaScript中基本数据类型和引用数据类型的区别 1.基本数据类型和引用数据类型 ECMAScript包括两个不同类型的值:基本数据类型和引用数据类型. 基本数据类型指的是简单的数据段,引用数据 ...
- 『无为则无心』Python基础 — 10、Python字符串的格式化输出
目录 1.什么是格式化输出 2.Python格式化输出的五种方式 方式一:字符串之间用+号拼接 方式二:print()函数可同时输出多个字符串 方式三:占位符方式 方式四:f格式化方式(推荐) 方式五 ...
- Linux 命令行查看etcd v2所有的Key
etcd 是一个树型的数据结构,这样看所有的key: curl localhost:2379/v2/keys 这样看某个key的内容: curl localhost:2379/v2/keys/key ...
- Docker启动PostgreSQL时创建多个数据库
1 前言 在文章<Docker启动PostgreSQL并推荐几款连接工具>中我们介绍如何通过Docker来启动PostgreSQL,但只有一个数据库,如果想要创建多个数据库在同一个Dock ...
- Linux 中的 AutoHotKey 键映射替代方案
1. Windows 之 AutoHotKey 初次了解AutoHotKey,是在Win 下最爱效率神器:AutoHotKey | 晚晴幽草轩这篇博客中,博主有对AutoHotKey作详细介绍,这里不 ...
- 温故知新Docker概念及Docker Desktop For Windows v3.1.0安装
Docker 简介 什么是Docker? Docker是一个开放源代码软件项目,项目主要代码在2013年开源于GitHub.它是云服务技术上的一次创新,让应用程序布署在软件容器下的工作可以自动化进行, ...
- 10.ODBC创建/读取Excel QT4
看到一篇MFC的参考链接:https://blog.csdn.net/u012319493/article/details/50561046 改用QT的函数即可 创建Excel //创建Excel v ...