机器学习——k-近邻算法
k-近邻算法(kNN)采用测量不同特征值之间的距离方法进行分类。
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中的k的出处,通常k是不大于20的整数。然后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。

kNN.py
# coding:utf-8
# !/usr/bin/env python '''
Created on Sep 16, 2010
kNN: k Nearest Neighbors Input: inX: vector to compare to existing dataset (1xN)
dataSet: size m data set of known vectors (NxM)
labels: data set labels (1xM vector)
k: number of neighbors to use for comparison (should be an odd number) Output: the most popular class label @author: pbharrin
''' from numpy import *
import operator
from os import listdir def classify0(inX, dataSet, labels, k): #inX是用于分类的输入向量,dataSet是输入的训练样本集,labels是标签向量,k是选择最近邻居的数目
dataSetSize = dataSet.shape[0] #shape函数求数组array的大小,例如dataSet一个4行2列的数组
#距离计算
diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile函数的功能是重复某个数组,例如把[0,0]重复4行1列,并和dataSet相减
sqDiffMat = diffMat**2 #对数组中和横纵坐标平方
#print(sqDiffMat)
sqDistances = sqDiffMat.sum(axis=1) #把数组中的每一行向量相加,即求a^2+b^2
#print(sqDistances)
distances = sqDistances**0.5 #开根号,√a^2+b^2
#print(distances)
#a = array([1.4, 1.5,1.6,1.2])
sortedDistIndicies = distances.argsort() #按升序排序,从小到大的下标依次是2,3,1,0
#print(sortedDistIndicies)
classCount={} #字典 #选择距离最小的k个点
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] #按下标取得标记
#print(voteIlabel)
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #在字典中计数
#print(classCount[voteIlabel])
#排序
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
#print(sortedClassCount)
return sortedClassCount[0][0] #返回计数最多的标记 def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels def file2matrix(filename): #处理格式问题,输入为文件名字符串,输出为训练样本矩阵和类标签向量
fr = open(filename)
numberOfLines = len(fr.readlines()) #取得文件的行数,1000行
returnMat = zeros((numberOfLines,3)) #生成一个1000行3列的矩阵
classLabelVector = [] #创建一个列表
fr = open(filename)
index = 0 #表示特征矩阵的行数
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t') #将字符串切片并转换为列表
returnMat[index,:] = listFromLine[0:3] #选取前三个元素,存储在特征矩阵中
#print listFromLine
#print returnMat[index,:]
classLabelVector.append(int(listFromLine[-1])) #将列表的最后一列存储到向量classLabelVector中
index += 1
return returnMat,classLabelVector #返回特征矩阵和类标签向量 def autoNorm(dataSet): #归一化特征值
minVals = dataSet.min(0) #最小值
maxVals = dataSet.max(0) #最大值
ranges = maxVals - minVals #范围
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1)) #原来的值和最小值的差
normDataSet = normDataSet/tile(ranges, (m,1)) #特征值差除以范围
return normDataSet, ranges, minVals def datingClassTest():
hoRatio = 0.10 #测试数据的比例
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
#inX是用于分类的输入向量,dataSet是输入的训练样本集,labels是标签向量,k是选择最近邻居的数目
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "分类器的结果: %d, 真正的结果: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "整体的错误率: %f" % (errorCount/float(numTestVecs))
print errorCount def classifyPerson():
resultList = ['不喜欢','一点点','很喜欢']
percentTats = float(raw_input('请输入玩游戏的时间百分比:'))
ffMiles = float(raw_input('请输入飞行里程总数:'))
iceCream = float(raw_input('请输入冰淇淋的升数:'))
datingDateMat,datingLabels = file2matrix("datingTestSet2.txt") #导入数据
normMat,ranges,minVals = autoNorm(datingDateMat) #归一化
inArr = array([ffMiles,percentTats,iceCream])
classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3) #分类的结果
print "喜欢的程度:",resultList[classifierResult-1] def img2vector(filename): #把32×32的二进制图像矩阵转换为1×1024的向量
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect def handwritingClassTest():
#准备训练数据
hwLabels = []
trainingFileList = listdir('digits/trainingDigits') #导入训练数据集合
m = len(trainingFileList)
trainingMat = zeros((m,1024))
#和m个训练样本进行对比
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #取得去掉后缀名的文件名
classNumStr = int(fileStr.split('_')[0]) #取得文件名中代表的数字
hwLabels.append(classNumStr) #由文件名生成标签向量
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr) #输入的训练样本集
#准备测试数据
testFileList = listdir('digits/testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
#预测测试样本
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #取得去掉后缀名的文件名
classNumStr = int(fileStr.split('_')[0]) #取得文件名中代表的数字
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr) #用于分类的输入向量
#inX是用于分类的输入向量,dataSet是输入的训练样本集,labels是标签向量,k是选择最近邻居的数目
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "分类器的结果: %d, 真实的结果: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\n预测的错误数是: %d" % errorCount
print "\n预测的错误率是: %f" % (errorCount/float(mTest)) if __name__ == '__main__':
# #group,labels = createDataSet()
# #classify0([0,0],group,labels,3)
# datingDateMat,datingLabels = file2matrix("datingTestSet2.txt")
# #print datingDateMat
# #print datingLabels
# import matplotlib
# import matplotlib.pyplot as plt
# fig = plt.figure()
# ax = fig.add_subplot(111) #控制位置
# ax.scatter(datingDateMat[:,1],datingDateMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels)) #点的横纵坐标,大小和颜色
# #plt.show()
#
# normMat,ranges,minVals = autoNorm(datingDateMat)
# print normMat
# print ranges
# print minVals # datingClassTest()
# classifyPerson()
# testVector = img2vector("digits/testDigits/0_0.txt")
# print testVector[0,0:31]
handwritingClassTest()
1.使用Python导入数据
NumPy函数库中存在两种不同的数据类型(矩阵matrix和数组array),都可以用于处理行列表示的数字元素
>>> import kNN
>>> group,labels = kNN.createDataSet()
>>> group
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])
>>> labels
['A', 'A', 'B', 'B']
>>> group
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])
>>> group.shape #shape函数求数组array的大小
(4, 2)
>>> group.shape[0]
4
>>> group.shape[1]
2
2.从文本文件中解析数据

>>> kNN.classify0([0,0],group,labels,3) #[0,0]是用于分类的输入向量,group是输入的训练样本集,labels是标签向量,3是选择最近邻居的数目
'B'


3.如何测试分类器

例子:使用k-近邻算法改进约会网站的配对效果
1.准备数据:从文本文件中解析数据

2.分析数据:使用Matplotlib创建散点图
datingDateMat,datingLabels = file2matrix("datingTestSet2.txt")
#print datingDateMat
#print datingLabels
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111) #控制位置
ax.scatter(datingDateMat[:,1],datingDateMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels)) #点的横纵坐标,大小和颜色
plt.show()
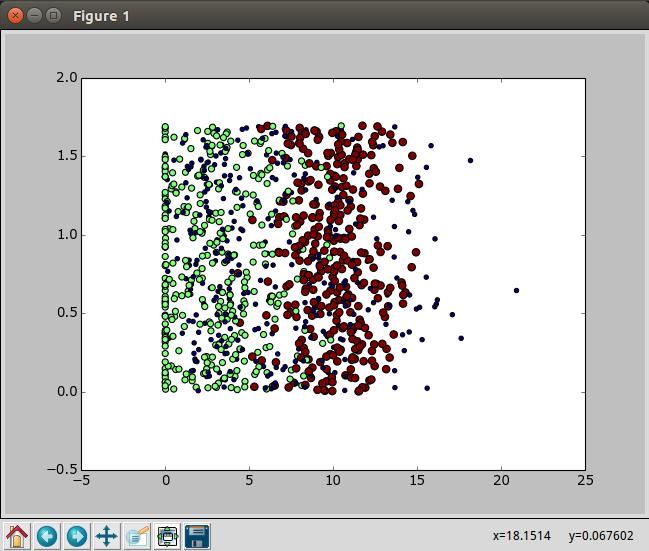
3.准备数据:归一化数值
在计算欧式距离的时候,数值差最大的属性对计算结果的影响最大。在处理这种不同取值范围的特征值的时候,我们通常的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。

def autoNorm(dataSet): #归一化特征值
minVals = dataSet.min(0) #最小值
maxVals = dataSet.max(0) #最大值
ranges = maxVals - minVals #范围
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1)) #原来的值和最小值的差
normDataSet = normDataSet/tile(ranges, (m,1)) #特征值差除以范围
return normDataSet, ranges, minVals
normMat,ranges,minVals = autoNorm(datingDateMat)
print normMat
print ranges
print minVals
4.测试算法:作为完整程序验证分类器

def datingClassTest():
hoRatio = 0.10 #测试数据的比例
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
#inX是用于分类的输入向量,dataSet是输入的训练样本集,labels是标签向量,k是选择最近邻居的数目
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "分类器的结果: %d, 真正的结果: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "整体的错误率: %f" % (errorCount/float(numTestVecs))
print errorCount
5.使用算法:构建完整可用系统
def classifyPerson():
resultList = ['不喜欢','一点点','很喜欢']
percentTats = float(raw_input('请输入玩游戏的时间百分比:'))
ffMiles = float(raw_input('请输入飞行里程总数:'))
iceCream = float(raw_input('请输入冰淇淋的升数:'))
datingDateMat,datingLabels = file2matrix("datingTestSet2.txt") #导入数据
normMat,ranges,minVals = autoNorm(datingDateMat) #归一化
inArr = array([ffMiles,percentTats,iceCream])
classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3) #分类的结果
print "喜欢的程度:",resultList[classifierResult-1]
例子:手写识别系统


1.准备数据,将图像转换为测试向量
def img2vector(filename): #把32×32的二进制图像矩阵转换为1×1024的向量
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
testVector = img2vector("digits/testDigits/0_0.txt")
print testVector[0,0:31]
2.测试算法:使用k-近邻算法识别手写数字

def handwritingClassTest():
#准备训练数据
hwLabels = []
trainingFileList = listdir('digits/trainingDigits') #导入训练数据集合
m = len(trainingFileList)
trainingMat = zeros((m,1024))
#和m个训练样本进行对比
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #取得去掉后缀名的文件名
classNumStr = int(fileStr.split('_')[0]) #取得文件名中代表的数字
hwLabels.append(classNumStr) #由文件名生成标签向量
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr) #输入的训练样本集
#准备测试数据
testFileList = listdir('digits/testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
#预测测试样本
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #取得去掉后缀名的文件名
classNumStr = int(fileStr.split('_')[0]) #取得文件名中代表的数字
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr) #用于分类的输入向量
#inX是用于分类的输入向量,dataSet是输入的训练样本集,labels是标签向量,k是选择最近邻居的数目
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "分类器的结果: %d, 真实的结果: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\n预测的错误数是: %d" % errorCount
print "\n预测的错误率是: %f" % (errorCount/float(mTest))

机器学习——k-近邻算法的更多相关文章
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
随机推荐
- java中数据类型的转换
数据类型的转换,分为自动转换和强制转换. 自动转换是程序执行过程中“悄然”进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换 强制转换必须在代码中声明,转换顺序不受限制 自动数据类 ...
- 机器学习实战笔记(Python实现)-06-AdaBoost
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- linux 安装mysql数据库——tar.gz包解压安装法
mysql数据库有多种安装方式,本文只介绍在Linux服务器上的tar.gz包解压安装法, 先通过mysql官网或者网络资源下载 mysql-5.7.3-m13-linux-glibc2.5-x86_ ...
- WPF 自定义标题栏 自定义菜单栏
自定义标题栏 自定义列表,可以直接修改WPF中的ListBox模板,也用这样类似的效果.但是ListBox是不能设置默认选中状态的. 而我们需要一些复杂的UI效果,还是直接自定义控件来的快 GitHu ...
- JS--轻松设置获取表单数据
接触过Angularjs的都知道,ng支持双向绑定,我们可以轻轻松松的通过ngModel将我们的值绑定到界面,当修改了值提交表单的时候不需要再重新通过ID去重新抓取输入框信息了.那对于我们开发前台网站 ...
- python编码最佳实践之总结
相信用python的同学不少,本人也一直对python情有独钟,毫无疑问python作为一门解释性动态语言没有那些编译型语言高效,但是python简洁.易读以及可扩展性等特性使得它大受青睐. 工作中很 ...
- [LeetCode] Largest Number 最大组合数
Given a list of non negative integers, arrange them such that they form the largest number. For exam ...
- 20145213《信息安全系统设计基础》实验一 Linux开发环境的配置
北京电子科技学院(BESTI) 实 验 报 告 课程:信息安全系统设计基础 班级:1452 姓名: 黄亚奇 祁玮 学号:20145213 20145222 成绩: 指导教师:娄嘉鹏 实验日期:2016 ...
- C语言中struct位域的定义和使用
位域的定义和使用 有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位.例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可.为了节省存储空间,并使处理简便,C语言又 ...
- webpack构建vue项目(再谈配置)
webpack配置起来确实麻烦,这不,之前用刚配好了vue1+的版本,结果在(部分)安卓机上测试,发现存在开启热加载(dev-server)的情况下不能识别vue语法的问题,试了很多方法,都没能很好的 ...