数据分析之pandas模块
一、Series
类似于一位数组的对象,第一个参数为数据,第二个参数为索引(索引可以不指定,就默认用隐式索引)
Series(data=np.random.randint(1,50,(10,)))
Series(data=[1,2,3],index=('a','b','c'))
dic={'math':88,'chinese':99,'english':50}
Series(data=dic)
对于data来说,可以是列表、np数组、字典,当用字典时,字典的key会成为行索引
1,索引和切片
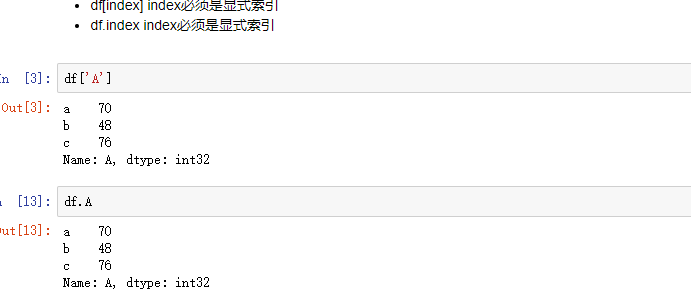
用中括号时,可以是显示索引,也可以是隐式索引
用句点符‘.’
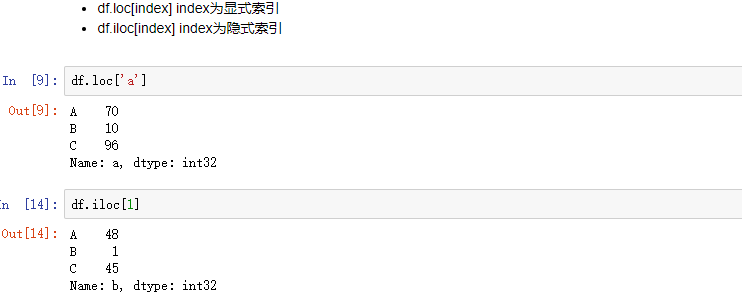
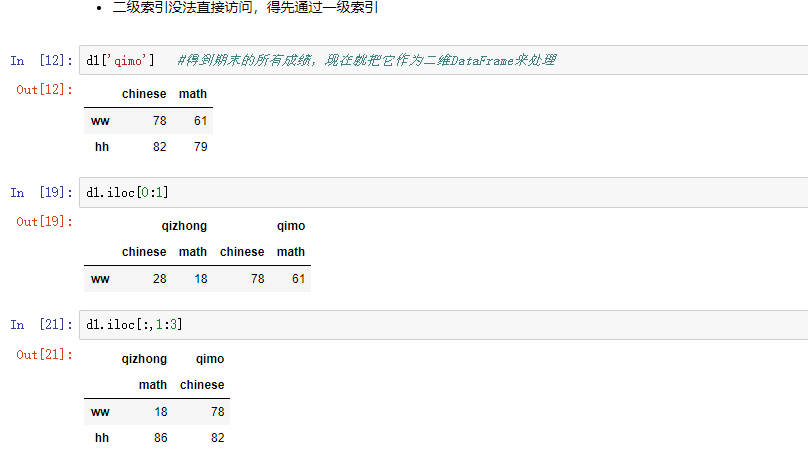
用.loc[]时,只能有显示索引
用.iloc[]时,只能用隐式索引
2,属性

3,去重

4,加法
索引相同的加在一起,当索引不一致的项,就用NaN填充

5,数据清洗
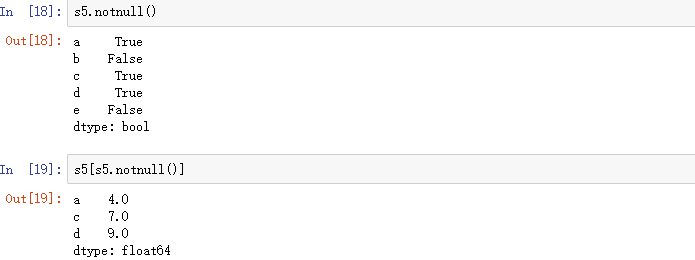
主要用isnull()判断值是否为空,notnull()判断值是否不为空,返回的都是值为bool型的Series,然后把它作为索引,就可以把为False的值给删除。
二、DataFrame
DataFrame是一个表格型的数据结构,DataFrame由一定顺序排列的多列数据组成,设计初衷是将Series的使用场景从一维拓展到多维,DataFrame既有行索引index,也有列索引columns,值values。
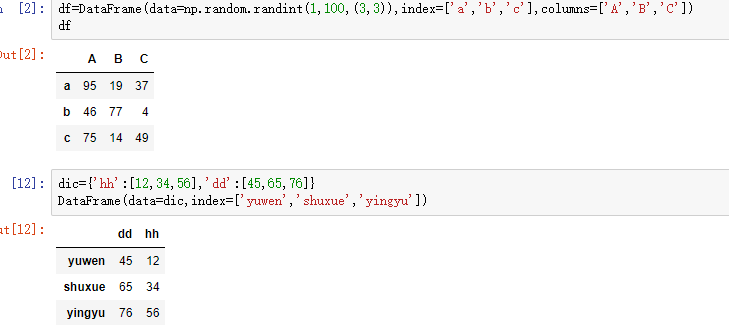
1,DataFrame的创建
最常用的方法是传递一个字典,以字典的key为列索引,以每一个key对应的值作为对应列的数据,所以值应该是个列表。还可以指定行索引,但不可以指定列索引。
2,索引和切片
2.1 列索引
2.2 行索引
2.3 元素索引
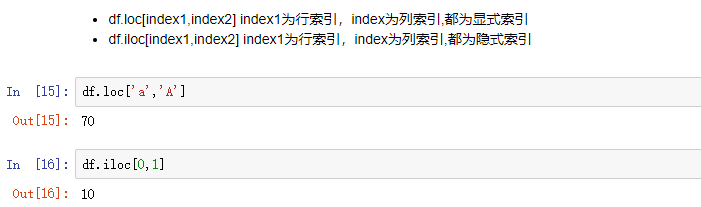
2.4 切片
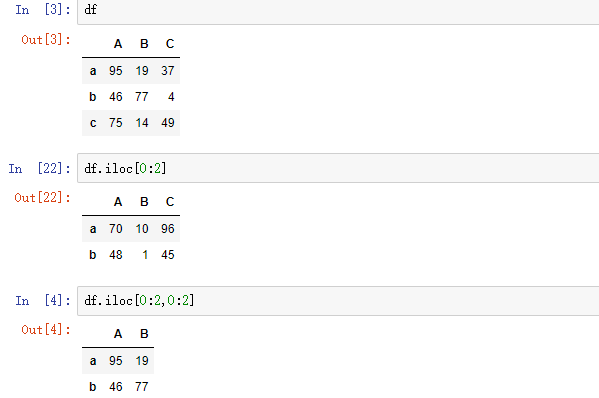
3,运算
要保证行索引和列索引都一致才能运算,否则用NaN填充
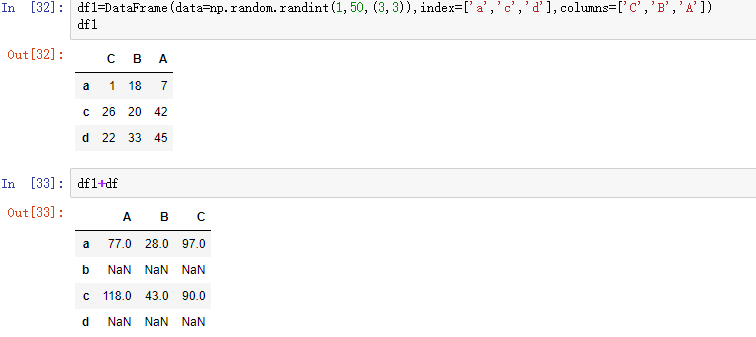
4,数据清洗
4.1 用isnull(),notnull(),any(),all()搭配使用,得到一组bool值的Series,然后把它作为索引,就可以清洗为False的行
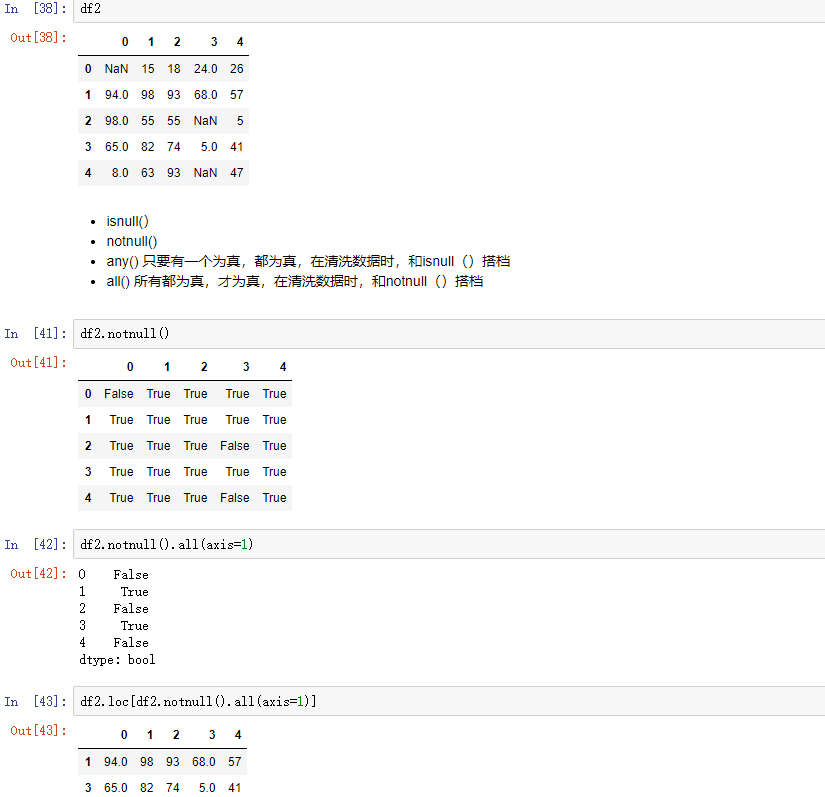
4.2 还可以用drop(),drop系列的函数中,axis=1表示列,axis=0代表行,这和其他所有场景都是相反的
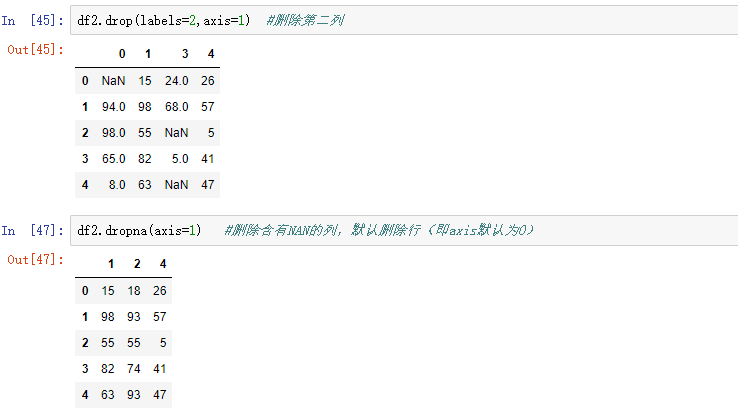
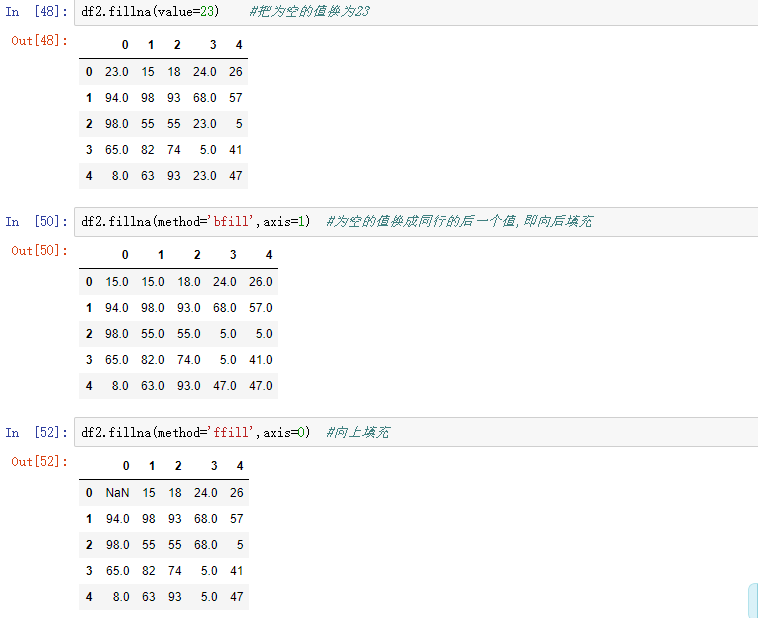
4.3 上面两种清洗方法都是删除整行或者,整列,有时是不允许这样子删除。我也可以用fillna()来把空值给填上。当inplace参数设为Ture时,表示修改后的数据映射到原数据,相当于修改原数据。
5,多层索引
5.1 隐式构造,最常用的方法是给DataFrame构造函数的index或columns传递两个或多个数组。

5.2 显式构造,用pd.MultiIndex.from_product

5.3 索引和切片
6,级联
pandas使用pd.concat(),与np.concatedate()类似,参数有些不同。
参数join:'outer'将所有的项进行级联(忽略匹配和不匹配),'inner'只会把匹配的项进行级联。

由于在以后的级联的使用很多,因此有一个函数append专门用于在后面添加。

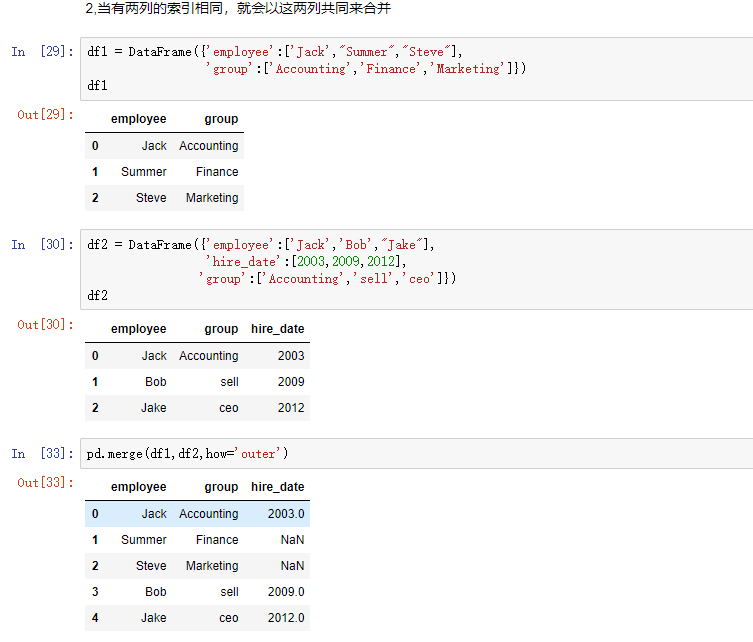
7,合并
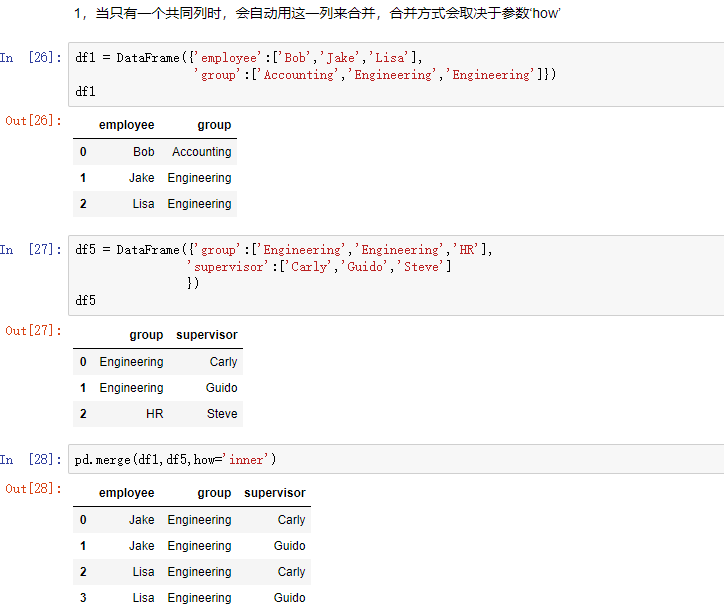
合并用merge().它和数据库中的链表差不多
merge和concat的区别在于,merge需要依据某一共同的列进行合并。
在使用merge时,会自动根据两者相同的columns,来合并
每一列元素不要求一致
参数:
how:out取并集,inner取交集
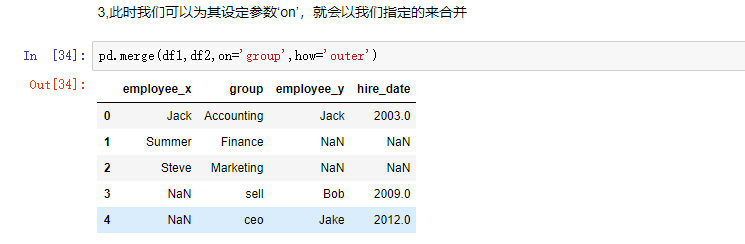
on:当两者有多列的名字相同时,我们想指定某一列进行合并,那我们就要把想指定列的名字赋给它
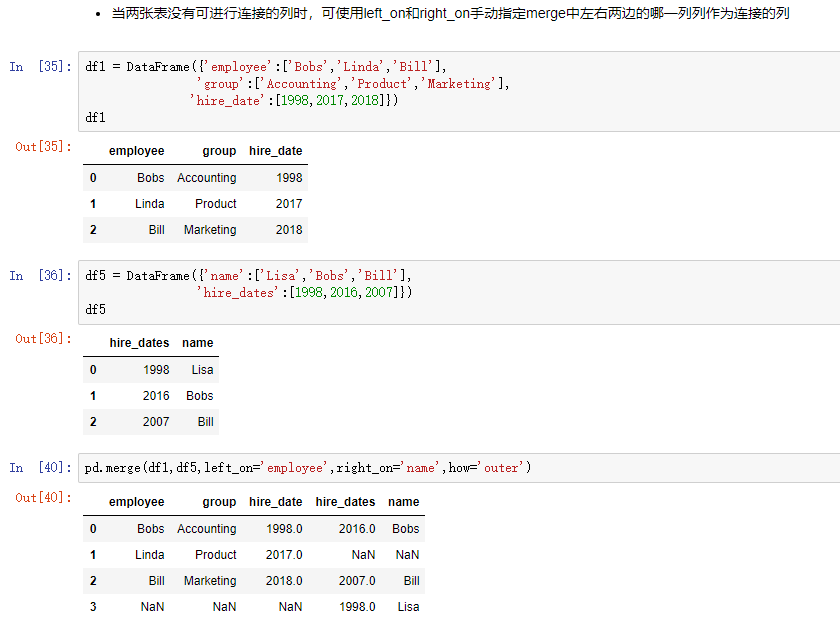
left_on和right_on:同时使用,当两者间没有共同的列名称时,可以分别指定
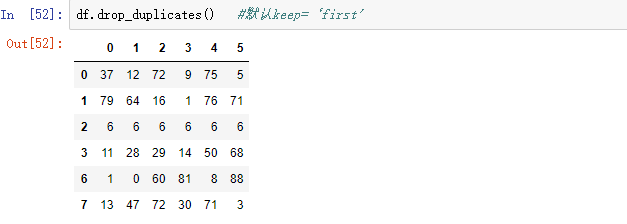
8,删除重复元素
使用duplicated()函数检测重复的行,返回元素为bool类型的Series对象,keep参数:指定保留哪一行重复的元素
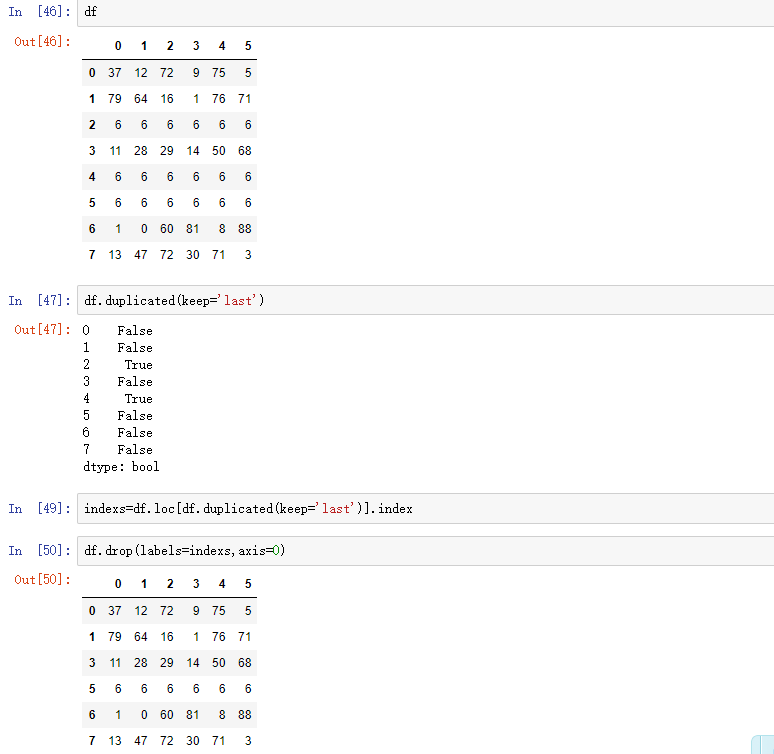
还可以使用drop_duplicates(),这也是drop系列函数。
9 ,替换replace()
df.replace(to_replace=6,value='ww') #把所有的6换成‘ww’
df.replace(to_replace={2:6},value='ww') #把列索引为‘2’这列中‘6’换成‘ww’
df.replace(to_replace={2:6,3:9},value='ww')#把列索引为2中的6和列索引为3中的9换成‘ww’
df.replace(to_replace={6:'ww'}) #把所有的6换成‘ww’
df.replace(to_replace={6:'ww',1:'qq'}) #把所有的6换成‘ww’,把所有的1换成‘qq’
10,映射
10.1 用map()新建一列
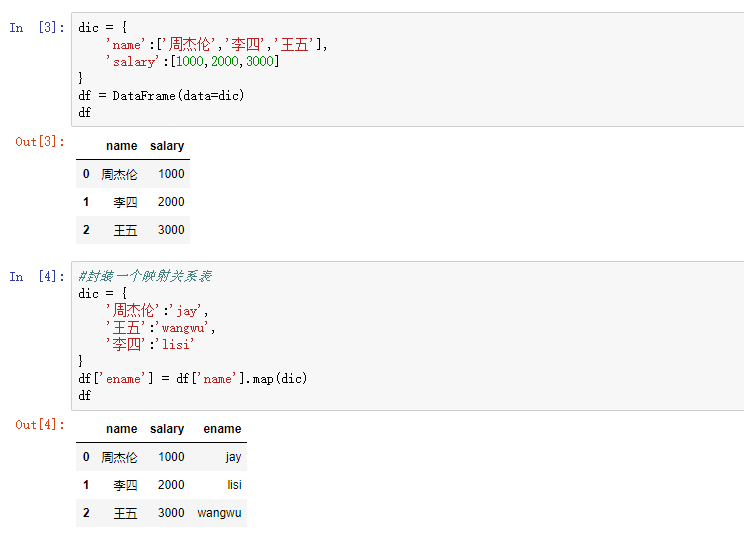
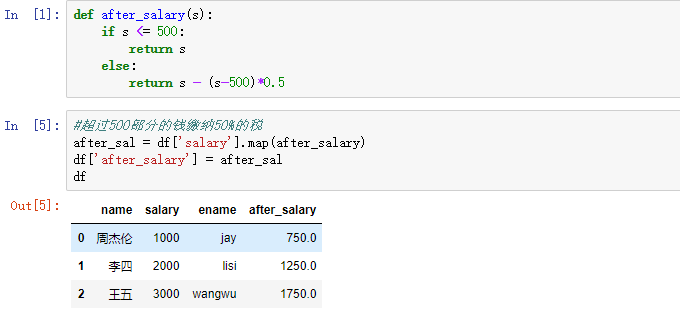
10.2 map()中还可以跟自定义函数
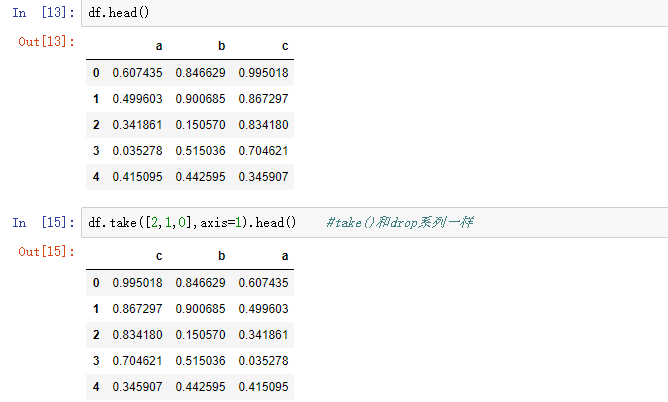
11,排序
使用take()函数排序,take接受一个索引列表,用数字表示,使得df会根据列表中索引的顺序进行排序
还可以使用np.random.permutation()函数随机排序,它返回的是一个一维的随机数组,比如参数为10,就会产生0到9这10个数字,不重复的,顺序还是打乱的。
当DataFrame规模足够大时,我们就可以借助它帮我们把数据打乱,然后用take函数实现随机抽样
values = df.take(np.random.permutation(1000),axis=0).take(np.random.permutation(3),axis=1).values
上面的代码是把1000行随机打乱,然后3列随机打乱
DataFrame(data=values)这就会映射会原数据,此时的原数据就是行和列都打乱的数据
12,分类
分类就是把数据分为几个组,然后我可以对每个组进行操作,这和数据库分类是一样的效果。使用的是groupby()函数,参数by是分类的依据,groups属性可以查看分组情况
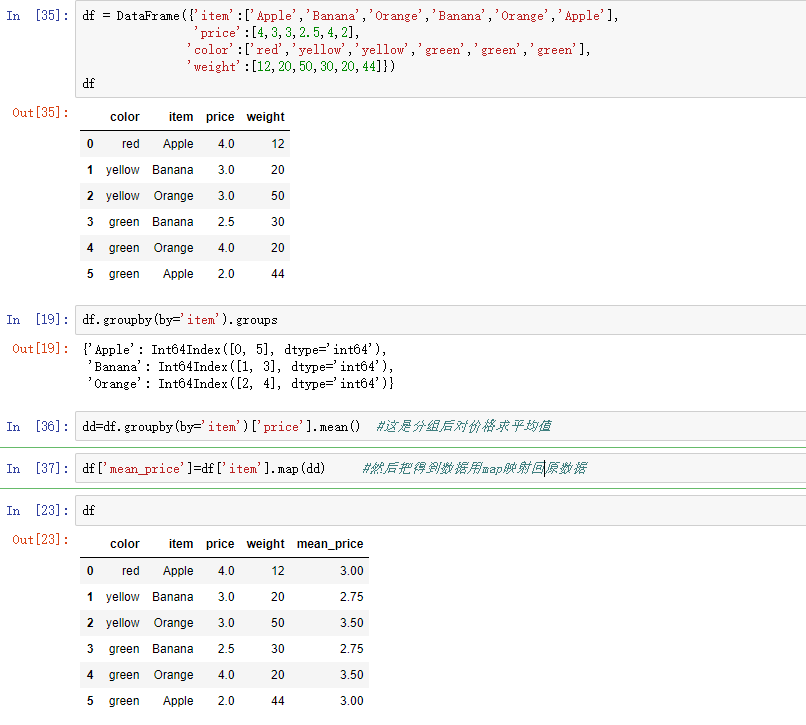
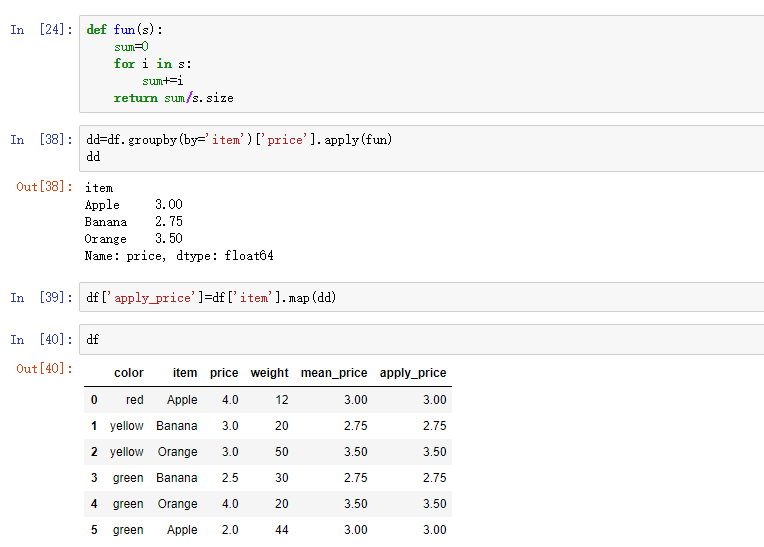
13,高级聚合
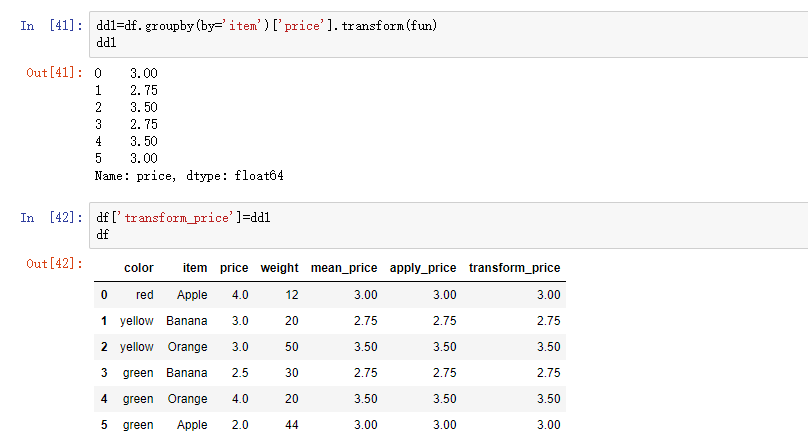
在分组后可以用sum(),mean()等聚合函数,其次还可以跟transform和apply函数,再给这两个函数传一个自定义函数,就可以是聚合函数以外的功能。
数据分析之pandas模块的更多相关文章
- 【Python 数据分析】pandas模块
上一节,我们已经安装了numpy,基于numpy,我们继续来看下pandas pandas用于做数据分析与数据挖掘 pandas安装 使用命令 pip install pandas 出现上图表示安装成 ...
- 关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题 ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- Python数据分析之pandas学习
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- Python 数据处理扩展包: numpy 和 pandas 模块介绍
一.numpy模块 NumPy(Numeric Python)模块是Python的一种开源的数值计算扩展.这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list str ...
- Pandas模块
前言: 最近公司有数据分析的任务,如果使用Python做数据分析,那么对Pandas模块的学习是必不可少的: 本篇文章基于Pandas 0.20.0版本 话不多说社会你根哥!开干! pip insta ...
- Python数据分析之pandas
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- 4 pandas模块,Series类
对gtx图像进行操作,使用numpy知识 如果让gtx这张图片在竖直方向上进行颠倒. 如果让gtx这张图片左右颠倒呢? 如果水平和竖直方向都要颠倒呢? 如果需要将gtx的颜色改变一下呢 ...
随机推荐
- (21)The history of human emotions
https://www.ted.com/talks/tiffany_watt_smith_the_history_of_human_emotions/transcript00:12I would li ...
- docker安装镜像
CMD 容器启动命令 CMD指令用于为执行容器提供默认值.每个Dockerfile只有一个CMD命令,如果指定了多个CMD命令,那么只有最后一条会被执行,如果启动容器的时候指定了运行的命令,则会覆盖掉 ...
- Spring AOP中pointcut expression表达式
Pointcut 是指那些方法需要被执行"AOP",是由"Pointcut Expression"来描述的. Pointcut可以有下列方式来定义或者通过&am ...
- 关不掉的小姐姐程序python tkinter实现 学习---打包教程
首先,我们先准备两个.py文件,还要图片文件 代码//是我自己手写的,copy时记得删掉,不然有可能错误,比如中英文啥的 当然 一些语法的无问题就百度,都能给你答案 第一个.py ...
- JDBC创建链接的几种方式
首先,使用java程序访问数据库的前提 数据库的主机地址(ip地址) 端口 数据库用户名 数据库用户密码 连接的数据库 代码: private static String url = "jd ...
- 第 1 篇 Scrum 冲刺博客
各个成员在 Alpha 阶段认领的任务 姓名 Alpha 阶段认领的任务 徐婉萍 创建服务器.域名,环境搭建查询界面及页面的设计,查询方法的编写 谭燕 支出.收入添加界面及设计,收入.支出的方法编写, ...
- Spark中的Phoenix Dynamic Columns
代码及使用示例:https://github.com/wlu-mstr/spark-phoenix-dynamic phoenix dynamic columns HBase的数据模型是动态的,很多系 ...
- SQL注入的优化和绕过
作者:Arizona 原文来自:https://bbs.ichunqiu.com/thread-43169-1-1.html 0×00 ~ 介绍 SQL注入毫无疑问是最危险的Web漏洞之一,因为我们将 ...
- Android精通:TableLayout布局,GridLayout网格布局,FrameLayout帧布局,AbsoluteLayout绝对布局,RelativeLayout相对布局
在Android中提供了几个常用布局: LinearLayout线性布局 RelativeLayout相对布局 FrameLayout帧布局 AbsoluteLayout绝对布局 TableLayou ...
- LabVIEW(十二):VI本地化-控件标题内容的修改
一.对于一般LabVIEW的学习,很少遇到本地化的问题但是我们经常会遇到界面控件标题的显示问题.由于各个技术领域的专业性,往往用户对VI界面的显示有自己的要求,其中就包括控件的标题问题,这可以理解成本 ...