Hadoop之简单文件读写
文件简单写操作:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class writeFile {
public static void main(String[] args) {
try{
Configuration conf=new Configuration();
//如果没有把配置文件加入bin文件夹,那么需要加入下面两行
//conf.set("fs.defaultFS","hdfs://localhost:9000" );
//conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs =FileSystem.get(conf);
byte[] buffer="Hello world!".getBytes();
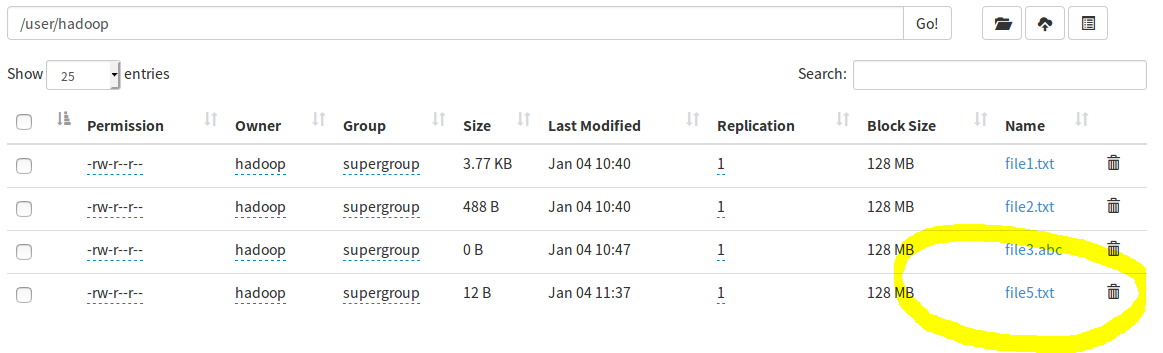
String Filename="hdfs://localhost:9000/user/hadoop/file5.txt"; FSDataOutputStream os=fs.create(new Path(Filename));
os.write(buffer,0,buffer.length); System.out.println("creat "+Filename+" successfully");
os.close();
fs.close();
}
catch(Exception e){
e.printStackTrace();
}
}
}
文件简单读操作:
import java.io.BufferedReader;
import java.io.InputStreamReader; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class readFile {
public static void main(String argsp[]){
try{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000" );
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
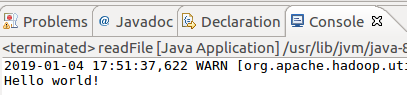
FileSystem fs = FileSystem.get(conf); Path file = new Path("hdfs://localhost:9000/user/hadoop/file5.txt"); FSDataInputStream is = fs.open(file); BufferedReader bd = new BufferedReader(new InputStreamReader(is));
String content = bd.readLine(); System.out.println(content); bd.close();
fs.close();
}
catch(Exception e){
e.printStackTrace();
}
}
}
Hadoop之简单文件读写的更多相关文章
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- Python——函数,模块,简单文件读写
函数(function)定义原则: 最大化代码重用,最小化代码冗余,流程符合思维逻辑,少用递归; 函数的定义方法: def function_name(param_1, param_2): ..... ...
- Python——函数,模块,简单文件读写(python programming)
函数(function)定义原则: 最大化代码重用,最小化代码冗余,流程符合思维逻辑,少用递归; 函数的定义方法: def function_name(param_1, param_2): ..... ...
- Python简单文件读写
''' 用文件存储账户信息 使用列表存储多个账户信息,每个账户为一个字典对象 ''' users=[] #创建一个空列表 users.append({'id':'admin','pwd':'1235@ ...
- Hadoop的文件读写操作流程
以下主要讲解了Hadoop的文件读写操作流程: 读文件 读文件时内部工作机制参看下图: 客户端通过调用FileSystem对象(对应于HDFS文件系统,调用DistributedFileSystem对 ...
- 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
一 原理阐述 1' DFS 分布式文件系统(即DFS,Distributed File System),指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连.该系统架构 ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- ios 简单的plist文件读写操作(Document和NSUserDefaults)
最近遇到ios上文件读写操作的有关知识,记录下来,以便以后查阅,同时分享与大家. 一,简单介绍一下常用的plist文件. 全名是:Property List,属性列表文件,它是一种用来存储串行化后的对 ...
随机推荐
- 防止xss和sql注入:JS特殊字符过滤正则
function stripscript(s) { var pattern = new RegExp("[%--`~!@#$^&*()=|{}':;',\\[\\].<> ...
- react纯手写全选与取消全选
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
错误情况 解决办法: 首先查看mysql的命令 其次修改root用户的密码 set password for 'root'@'localhost' = password('123456'); 最后退出 ...
- js设计模式(四)---迭代器模式
定义: 迭代器模式是指提供一种方法,顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示,迭代器模式可以把迭代的过程从业务逻辑中分离出来,使用迭代器模式,即使不关心对象的内部构造,也可以按 ...
- Linux re
正则表达式并不是一个工具程序,而是一个字符串处理的标准依据,如果想要以正则表达式的方式处理字符串,就得使用支持正则表达式的工具,例如grep.vi.sed.asw等. 注意:ls不支持正则表达式. g ...
- MGF 637: Financial Modeling
MGF 637: Financial ModelingSpring 2019Extra Credit AssignmentInstructions: This is an extra credit o ...
- 实验二:MAL——简单后门 by:赵文昊
实验二:MAL--简单后门 一.后门是什么? 哪里有后门呢? 编译器留后门 操作系统留后门 最常见的当然还是应用程序中留后门 还有就是潜伏于操作系统中或伪装为特定应用的专用后门程序. 二.认识netc ...
- 1、vue 笔记之 组件
1.组件个人理解: <组件>是页面的一部分,将界面切分成部分,每部分称为 <组件> 2.组件化思想: //2.1.定义一个全局的组件,组件支持‘驼峰命名 ...
- java框架之SpringCloud(4)-Ribbon&Feign负载均衡
在上一章节已经学习了 Eureka 的使用,SpringCloud 也提供了基于 Eureka 负载均衡的两种方案:Ribbon 和 Feign. Ribbon负载均衡 介绍 SpringCloud ...
- vs添加github代码库
1.安装git for windows 2.在vs中工具->扩展和更新,安装github extension 3.在项目中右键,添加源码到git,之后配置git,然后选择同步或者commit即可