机器学习之决策树_CART算法

决策树基本知识参考,请点击:https://www.cnblogs.com/hugechuanqi/p/10498786.html
3、CART算法(classification and regression tree tree)
- CART,即分类与回归树,是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法。CART假定决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。
- CART算法分为两个步骤:
- 决策树生成:基于训练集生成决策树,生成的决策树要尽量大;
- 决策树剪枝:基于验证数据对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
3.1 CART生成算法(回归树生成和分类树生成)
- CART包括回归树和分类树,回归树和分类树的区别:
- 回归树用平方误差最小化准则,进行特征选择,递归地构建二叉树。
- 分类树用基尼指数最小化准则,进行特征选择,递归地构建二叉树。
- CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子节点都有两个分支。因此CART算法生成的决策树是结构简单的二叉树,做决策时只有“是”和“否”两个分支,即使一个特征下有多个分类取值,也只能把数据分为两部分。
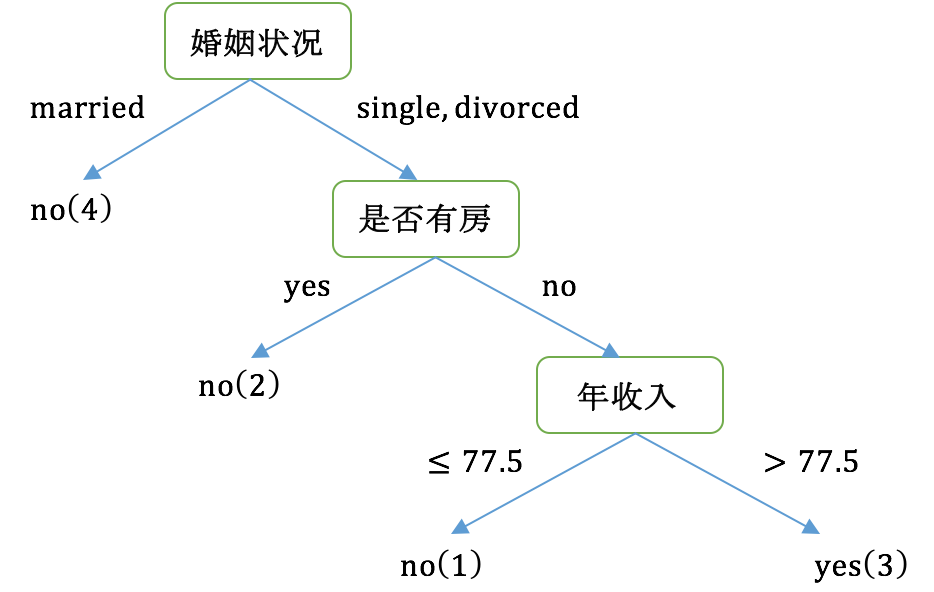
(1)CART回归树生成
- 回归树用平方误差最小化准则,进行特征选择,递归地构建二叉树。
数据集\(D={(x_{1}, y_{2}), (x_{2}, y_{2}), ..., (x_{N}, y_{N})}\),其中\(x = \{x^{1}, x^{2}, ..., x^{l}, ..., x^{M}\}\)为输入变量,例如\(x_{1} = \{x_{1}^{1}, x_{1}^{2}, ..., x_{1}^{l}, ..., x_{1}^{M}\}\),\(Y\)是连续的输入变量。
- 一个回归树对应着输入特征空间中的一个划分,以及在划分单元的输出值。假定已经将输入特征空间划分为M个单元\(R_{1}, R_{2}, ..., R_{M}\),并且在每个单元\(R_{m}\)上有一个固定的输出值\(c_{m}\),则回归树的模型为:
\[f(x) = \sum\limits_{m=1}^{M} c_{m} I(x \in R_{m})\] 每个单元最优输出值的确定:当输入特征空间已经划分时,可以用平方误差\(\sum\limits_{x_[i] \in R_{m}} (y_{i} - f(x_{i}))^{2}\)来表示预测误差,然后用最小平方误差的准则求解每个单元上的最优输出值\(\hat{c}_{m}\)。从统计分析的角度,平均值概括了大多数样本。因此单元\(R_{m}\)上的\(c_{m}\)的最优值\(\hat{c}_{m}\)是\(R_{m}\)上的所有输入实例\(x_{i}\)对应的输出平均值,即
\[\hat{c}_{m} = ave(y_{i} | x_{i} \in R_{m})\]空间划分:选择第\(j\)个变量\(x^{j}\)和它的取值s,作为切分变量和切分点。并定义两个区域:
\[R_{1}(j,s) = \{x | x^{(j)} \leq s\} \ 和\ R_{2}(j,s) = \{x | x^{(j)} > s\}\]
然后寻找最优切分变量\(j\)和最优切分点s。具体求解:
\[\min\limits_{j,s} [\min\limits_{c1} \sum\limits_{x_{i} \in R_{1}(j,s)} (y_{i} - c_{1})^{2} + \min\limits_{c2} \sum\limits_{x_{i} \in R_{2}(j,s)} (y_{i} - c_{2})^{2}]\]
对固定输入变量\(j\)可以找到最优切分点。
\[\hat{c}_{1} = ave(y_{i} | x_{i} \in R_{1}(j,s)) \ 和 \hat{c}_{2} = ave(y_{i} | x_{i} \in R_{2}(j,s))\]
遍历所有的输入变量,找到最优的切分变量\(j\),构成一个对(j,s),依次将输入特征空间划分为两个区域。接下来,对每个区域重复上述划分过程,直到满足停止条件为止,这样就生成一颗回归树。- 最小二乘回归树生成算法流程:

其中变量J指某一个特征,该特征变量取值\(x_{1} = \{x_{1}^{1}, x_{1}^{2}, ..., x_{1}^{l}, ..., x_{1}^{M}\}\),对应的输出为\(y_{1} = \{y_{1}^{1}, y_{1}^{2}, ..., y_{1}^{l}, ..., y_{1}^{M}\}\)。并利用拟合出来的残差\(r_{1}^{i} = y_{1}^{i} -f(x_{1}^{i})\)代替输出\(y_{1}^{i}\)继续生成子树。 扩展:在梯度提升树中,GBDT利用损失函数的负梯度\(r_{ti} = - [\frac{\partial L(y_{i}, f(x_{i})) }{\partial f(x_{i}) }]_{f(x)=f_{t-1}(x)}\)代替残差的近似值继续生成子树。(具体实例见下回分解)
(2)CART分类树生成
- 分类树用基尼指数选择最优特征,通过选择基尼指数最小的特征及其对应的切分点作为最优特征和最优切分点。
- 概率分布的基尼指数定义为:
\[Gini(p) = \sum\limits_{k=1}^{K} p_{k}(1-p_{k}) = 1 - \sum_{k=1}^{K} p_{k}^{2}\]
其中,假设分类问题中有K个类,样本点属于第K类的概率为\(p_{k}\)。 - 对于二分类问题,属于第一个类的概率为p,则属于第二个类的概率为1-p,其概率分布的基尼指数为:
\[Gini(p) = 2p(1-p)\] - 对于给定的样本集合D,其基尼指数为:
\[Gini(D) = 1 - \sum\limits_{k=1}^{K} (\frac{|C_{k}|}{|D|})^{2}\]
其中,\(C_{k}\)是D中属于第k类的样本子集,K是类的个数。 - 如果在样本集合D根据A是否取某一可能值a被分割成\(D_{1}\)和\(D_{2}\)两部分,即\(D_{1} = \{(x,y) \in D | A(x) = a\}\), \(D_{2}=D-D_{1}\),则在特征A的条件下,集合D 的基尼指数定义为:
\[Gini(D,A) = \frac{|D_{1}|}{|D|} Gini(D_{1}) + \frac{|D_{2}|}{|D|} Gini(D_{2})\] 基尼指数\(Gini(D)\)表示集合D的不确定性,基尼指数\(Gini(D,A)\)表示经\(A=a\)分割后集合D的不确定性。基尼指数值越大,样本集合的不确定性也就越大,类似于殇。
CART分类树的生成算法流程:

3.2 CART剪枝
- CART剪枝算法从“完全生长”的决策树的底端剪去一些子树,使决策树变简单,防止过拟合。分两步:
- 首先从生成算法产生的决策树\(T_{0}\)底端开始不断剪枝,知道==直到\(T_{0}\)的根结点,形成一个子树序列\(\{T_{0}, T_{1}, ..., T_{n},\}\);
- 然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。
(1)形成一个子树序列
剪枝过程中子树的损失函数:
\[C_{\alpha}(T) = C(T) + \alpha |T|\]
其中T为任意子树,\(C_{T}\)是对训练数据的预测误差(如基尼指数),\(|T|\)为子树的叶结点个数,C_{\alpha}(T)为参数\(\alpha\)时的子树T的整体损失,参数\(\alpha\)权衡训练数据的拟合程度与模型的复杂度。对\(T_{0}\)中每一个内部结点t,计算
\[g(t) = \frac{C(t) - C(T_{t})}{|T_{t}| - 1}\]
g(t)表示剪枝后整体损失函数减少的程度,\(C(t)\)表示剪枝前的损失函数,\(C(T_{t})\)表示剪枝后的损失函数。在\(T_{0}\)中剪去g(t)最小的\(T_{t}\),将得到的子树作为\(T_{1}\),同时将最小的g(t)设为\(\alpha_{1}\)。\(T_{1}\)为区间\([\alpha_{1}, \alpha_{2}]\)的最优子树。不断剪枝下去,直至得到根结点。在这个过程中,不断地增加\(\alpha\)的值,产生新的空间。
(2)在剪枝得到的子树序列\(T_{0}, T_{1}, .., T_{n}\)中通过交叉验证选取最优子树\(T_{\alpha}\)
主要是通过验证数据集,测试这些子树序列中各棵子树的平方误差或者基尼指数。取平方误差或者基尼指数最小的决策树为最优决策树\(T_{k}\),对应的\(\alpha_{k}\)也就确定了。
CART剪枝算法流程:

参考:
- 李航《统计学习方法》
- CART分类树原理示例:https://blog.csdn.net/aaa_aaa1sdf/article/details/81587359
- 数据挖掘十大算法之CART:https://blog.csdn.net/baimafujinji/article/details/53269040
机器学习之决策树_CART算法的更多相关文章
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- [机器学习实战] 决策树ID3算法
1. 决策树特点: 1)优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据. 2)缺点:可能会产生过度匹配问题. 3)适用数据类型:数值型和标称型. 2. 一般流程: ...
- 用Python开始机器学习(2:决策树分类算法)
http://blog.csdn.net/lsldd/article/details/41223147 从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树 ...
- 机器学习之决策树(ID3)算法
最近刚把<机器学习实战>中的决策树过了一遍,接下来通过书中的实例,来温习决策树构造算法中的ID3算法. 海洋生物数据: 不浮出水面是否可以生存 是否有脚蹼 属于鱼类 1 是 是 是 2 ...
- 机器学习决策树ID3算法,手把手教你用Python实现
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第21篇文章,我们一起来看一个新的模型--决策树. 决策树的定义 决策树是我本人非常喜欢的机器学习模型,非常直观容易理解 ...
- 03机器学习实战之决策树CART算法
CART生成 CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支.这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- day-7 一个简单的决策树归纳算法(ID3)python编程实现
本文介绍如何利用决策树/判定树(decision tree)中决策树归纳算法(ID3)解决机器学习中的回归问题.文中介绍基于有监督的学习方式,如何利用年龄.收入.身份.收入.信用等级等特征值来判定用户 ...
- 决策树ID3算法--python实现
参考: 统计学习方法>第五章决策树] http://pan.baidu.com/s/1hrTscza 决策树的python实现 有完整程序 决策树(ID3.C4.5.CART ...
随机推荐
- oracle日期格式化
TO_CHAR(t.CAMERA_CREAT_TIME, 'YYYY-MM-DD HH24:MI:SS') as point_registerdate,TO_CHAR(t.CAMERA_MODIFY_ ...
- js数组代码库
1 数组操作 1.1 数组去重:ES6的方法 //ES6新增的Set数据结构,类似于数组,但是里面的元素都是唯一的 ,其构造函数可以接受一个数组作为参数 //let arr=[1,2,1,2,6,3, ...
- 11.1-uC/OS-III就绪列表
准备好运行的任务被放到就绪列表中, 如图6-1.就绪列表是一个数组( OSRdyList[]),它一共有OS_CFG_PRIO_MAX条记录,记录的数据类型为OS_RDY_LIST(见OS.H).就绪 ...
- Python3学习之路~5.9 xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,以前在json还没诞生的时候,大家只能选择用xml,至今很多传统公司如金融行业的很多系统的接口还主要 ...
- JedisCluster简单使用
项目中因为一些原因需要用到缓存,之前没有接触过,在此做一些简单的使用记录. 1.jedis在项目中依赖 <dependency> <groupId>redis.clients& ...
- 问题: 揭秘Angualr2 书上问卷调查
npm install 初夏下面问题: 0 info it worked if it ends with ok1 verbose cli [ '/home/linux_ubuntu164/tools/ ...
- java之连接数据库之JDBC访问数据库的基本操作
1.将数据库的JDBC驱动加载到classpath中,在基于JavaEE的web应用实际开发过程中通常要把目标数据库产品的JDBC驱动复制到WEB—INF/lib下. 2.加载JDBC驱动并将其注册到 ...
- mysql日志介绍
1. 错误日志 错误日志记录的事件: a. 服务器启动关闭过程中的信息 b. 服务器运行过程中的错误信息 c. 事件调试器运行一个事件时间生的信息 d. 在从服务器上启动从服务器进程时产生的信息 2. ...
- 使用sp_addlinkedserver、sp_dropserver 、sp_addlinkedsrvlogin和sp_droplinkedsrvlogin 远程查询数据
一.sp_addlinkedserver 创建链接服务器. 链接服务器让用户可以对 OLE DB 数据源进行分布式异类查询. 在使用 sp_addlinkedserver 创建链接服务器后,可对该服 ...
- Hdu2041 超级楼梯 (斐波那契数列)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2041 超级楼梯 Time Limit: 2000/1000 MS (Java/Others) M ...