【原创】MapReduce运行原理和过程
一.Map的原理和运行流程
Map的输入数据源是多种多样的,我们使用hdfs作为数据源。文件在hdfs上是以block(块,Hdfs上的存储单元)为单位进行存储的。
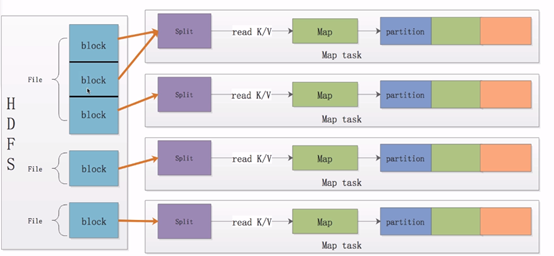
1.分片

我们将这一个个block划分成数据分片,即Split(分片,逻辑划分,不包含具体数据,只包含这些数据的位置信息),那么上图中的第一个Split则对应两个个文件块,第二个Split对应一个块。需要注意的是一个Split只会包含一个File的block,不会跨文件。
2. 数据读取和处理

当我们把数据块分好的时候,MapReduce(以下简称mr)程序将这些分片以key-value的形式读取出来,并且将这些数据交给用户自定义的Map函数处理。
3.

用户处理完这些数据后同样以key-value的形式将这些数据写出来交给mr计算框架。mr框架会对这些数据进行划分,此处用进行表示。不同颜色的partition矩形块表示为不同的partition,同一种颜色的partition最后会分配到同一个reduce节点上进行处理。
Map是如何将这些数据进行划分的?
默认使用Hash算法对key值进行Hash,这样既能保证同一个key值的数据划分到同一个partition中,又能保证不同partition的数据梁是大致相当的。
总结:
1.一个map指挥处理一个Split
2.map处理完的数据会分成不同的partition
3.一类partition对应一个reduce
那么一个mr程序中 map的数量是由split的数量决定的,reduce的数量是由partiton的数量决定的。
二.Shuffle
Shuffle,翻译成中文是混洗。mr没有排序是没有灵魂的,shuffle是mr中非常重要的一个过程。他在Map执行完,Reduce执行前发生。
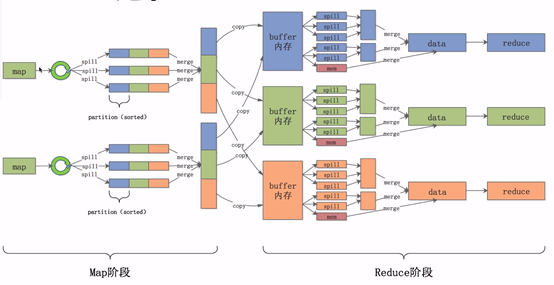
Map阶段的shuffle
数据经过用户自定的map函数处理完成之后,数据会放入内存中的环形缓冲区之内, ,他分为两个部分,数据区和索引区。数据区是存放用户真实的数据,索引区存放数据对应的key值,partition和位置信息。当环形缓冲区数据达到一定的比例后,会将数据溢写到一个文件之中,即途中的spill(溢写)过程。
,他分为两个部分,数据区和索引区。数据区是存放用户真实的数据,索引区存放数据对应的key值,partition和位置信息。当环形缓冲区数据达到一定的比例后,会将数据溢写到一个文件之中,即途中的spill(溢写)过程。
在溢写前,会将数据根据key和partition进行排序,排好序之后会将数据区的数据按照顺序一个个写入文件之中。这样就能保证文件中数据是按照key和parttition进行排序的。最后会将溢写出的一个个小文件合并成一个大的文件,并且保证在每一个partition
中是按照Key值有序的。
总结:
- Collect阶段将数据放进环形缓冲区,缓冲区分为数据区和索引区。
- Sort阶段对在同一partition内的索引按照key排序。
- Spill阶段跟胡排好序的索引将数据按照顺序写到文件中。
- Merge阶段将Spill生成的小文件分批合并排序成一个大文件。
Reduce阶段的shuffle
reduce节点会将数据拷贝到自己的buffer缓存区中,当缓存区中的数据达到一定的比例的时候,同样会发生溢写过程,我们任然要保证每一个溢写的文件是有序的。与此同时,后台会启一个线程,将这些小文件合并成一个大文件,经过一轮又一轮的合并,最后将这些文件合并成一个大的数据集。在这个数据集中,数据是有序的,相同的key值对应的value值是挨在一起的。最后,将这些数据交给reduce程序进行聚合处理。
总结:
- 1. Copy阶段将Map端的数据分批拷贝到Reduce的缓冲区。
- 2. Spill阶段将内存缓存区的数据按顺序写到文件中。
- 3. Merge阶段将溢出的文件合并成一个排序的数据集。
三.Reduce运行过程

在map处理完之后,reduce节点会将各个map节点上属于自己的数据拷贝到内存缓冲区中,最后将数据合并成一个大的数据集,并且按照key值进行聚合,把聚合后的value值作为iterable(迭代器)交给用户使用,这些数据经过用户自定义的reduce函数进行处理之后,同样会以key-value的形式输出出来,默认输出到hdfs上的文件。
四.Combine优化
我们说mr程序最终是要将数据按照key值进行聚合,对value值进行计算,那么我们是不是可以提前对聚合好的value值进行计算?of course,我们将这个过程称为Combine。哪些场景可以进行conbine优化。如下。
Map端:
1. 在数据排序后,溢写到磁盘前,运行combiner。这个时候相同Key值的value值是挨在一起的,可以对这些value值进行一次聚合计算,比如说累加。
2. 溢写出的小文件合并之前,我们也可以执行一次combiner,需要注意的是mr程序默认至少存在三个文件才进行combiner,否则mr会认为这个操作是不值得的。当然这个值可以通过min.num.spills.for.combine设置。
Reduce端:
- 和map端一样,在合并溢出文件输出到磁盘之前,运行combiner。
写在最后
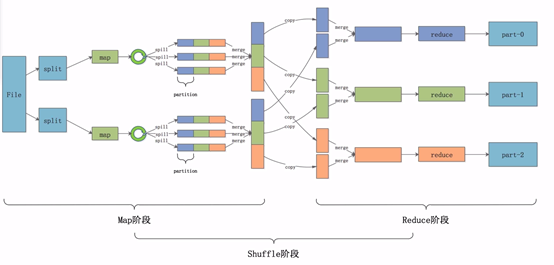
送上整个MR过程图。
【原创】MapReduce运行原理和过程的更多相关文章
- MapReduce运行原理和过程
原文 一.Map的原理和运行流程 Map的输入数据源是多种多样的,我们使用hdfs作为数据源.文件在hdfs上是以block(块,Hdfs上的存储单元)为单位进行存储的. 1.分片 我们将这一个个bl ...
- MapReduce运行原理
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各 ...
- MapReduce概述,原理,执行过程
MapReduce概述 MapReduce是一种分布式计算模型,运行时不会在一台机器上运行.hadoop是分布式的,它是运行在很多的TaskTracker之上的. 在我们的TaskTracker上面跑 ...
- Hadoop 2.6 MapReduce运行原理详解
市面上的hadoop权威指南一类的都是老版本的书籍了,索性学习并翻译了下最新版的Hadoop:The Definitive Guide, 4th Edition与大家共同学习. 我们通过提交jar包, ...
- mapreduce运行原理及YARN
mapreduce1回顾 mapreduce1的不足 yarn的基本架构 yarn工作流程
- Web应用运行原理
web应用启动做了什么? 读取web.xml文件 - web.xml常用配置参数: 1).context-param(上下文参数)2).listener(监听器配置参数)3).filter(过滤器 ...
- 【原创】分布式之数据库和缓存双写一致性方案解析(三) 前端面试送命题(二)-callback,promise,generator,async-await JS的进阶技巧 前端面试送命题(一)-JS三座大山 Nodejs的运行原理-科普篇 优化设计提高sql类数据库的性能 简单理解token机制
[原创]分布式之数据库和缓存双写一致性方案解析(三) 正文 博主本来觉得,<分布式之数据库和缓存双写一致性方案解析>,一文已经十分清晰.然而这一两天,有人在微信上私聊我,觉得应该要采用 ...
- Linux X Window System运行原理和启动过程
本文主要说明X Window System的基本运行原理,其启动过程,及常见的跨网络运行X Window System. 一) 基本运行原理 X Window System采用C/S结构,但和我们常见 ...
- JSP起源、JSP的运行原理、JSP的执行过程
JSP起源 在很多动态网页中,绝大部分内容都是固定不变的,只有局部内容需要动态产生和改变. 如果使用Servlet程序来输出只有局部内容需要动态改变的网页,其中所有的静态内容也需要程序员用Java程序 ...
随机推荐
- 201621123018《Java程序设计》第2周学习报告
Week02-Java基本语法与类库 1.本周学习总结 Java数据类型分为基本数据类型和引用数据类型.布尔型是Java特有的数据类型.本周重点学习了字符串类型String,String类型中==和e ...
- 自定义控件和View
一.自定义控件 MotionEvent.ACTION_UP:抬起 MotionEvent.ACTION_DOWN: 按下 MotionEvent.ACTION_POINTER_UP: MotionEv ...
- LC-BLSTM结构快速解读
参考文献如下: (1) A Context-Sensitive-Chunk BPTT Approach to Training Deep LSTM/BLSTM Recurrent Neural Net ...
- iOS9新特性-UIStackView
1. UIStackView相关属性理解 UIStackView是iOS9之后推出的,我也是第一次接触,在学习的过程中对于其中的相关属性,尤其是对其中的distribution几个属性值,一知半解的, ...
- oracle 转 mysql 最新有效法
关键字:Oracle 转 MySQL . Oracle TO MySQL 没事试用了一下Navicat家族的新产品Navicat Premium,他集 Oracle.MySQL和PostgreSQL管 ...
- JavaScript中的异步操作
什么是异步操作? 异步模式并不难理解,比如任务A.B.C,执行A之后执行B,但是B是一个耗时的工作,所以,把B放在任务队列中,去执行C,然后B的一些I/O等返回结果之后,再去执行B,这就是异步操作. ...
- Java之集合(十)EnumMap
转载请注明源出处:http://www.cnblogs.com/lighten/p/7371744.html 1.前言 本章介绍Map体系中的EnumMap,该类是专门针对枚举类设计的一个集合类.集合 ...
- Linq基础知识小记四之操作EF
1.EF简介 EF之于Linq,EF是一种包含Linq功能对象关系映射技术.EF对数据库架构和我们查询的类型进行更好的解耦,使用EF,我们查询的对象不再是C#类,而是更高层的抽象:Entity Dat ...
- APP 渠道推广【摘自网络】
渠道的合作方式无非三种,一种是付费合作,那很简单,谈好价格付钱.第二种是免费,主要是就是首发,还有就是跟渠道的运营小伙伴搞好关系让帮忙给个免费的位置等,第三种是活动奖品合作,简而言之,就是渠道商会逢年 ...
- protocol buffer开发指南
ProtoBuf 是一套接口描述语言(IDL)和相关工具集(主要是 protoc,基于 C++ 实现),类似 Apache 的 Thrift).用户写好 .proto 描述文件,之后使用 protoc ...