使用 Hadoop 进行语料处理(面试题)
原创播客,如需转载请注明出处。原文地址:http://www.cnblogs.com/crawl/p/7751741.html
----------------------------------------------------------------------------------------------------------------------------------------------------------
笔记中提供了大量的代码示例,需要说明的是,大部分代码示例都是本人所敲代码并进行测试,不足之处,请大家指正~
本博客中所有言论仅代表博主本人观点,若有疑惑或者需要本系列分享中的资料工具,敬请联系 qingqing_crawl@163.com
-----------------------------------------------------------------------------------------------------------------------------------------------------------
前言:近日有高中同学求助,一看题目,正好与楼主所学技术相关,便答应了下来,因为正是兴趣所在,也没有管能不能实现。
话不多说,先上题:

同学告诉我 ,这是浪潮实习生的面试题。
楼主先对题目作简单的说明,给定了一个 corpus.txt 文件作为语料处理的源文件,文件大小 30.3M,内容即题目要求中的图片所示,要求对语料文件中出现的词进行词频统计,并把词频相同的词语用 ## 相连(如 研究##落实 1008 ),并按词频从大到小排序。题目要求的是根据所学的 Java I/O 处理、集合框架、字符集与国际化、异常处理等基础知识完成此题,但同学表明可以使用大数据的相关知识,让楼主感到兴趣的是,最近楼主一直在研究 Hadoop,词频统计的题目做了不少,便欣然接受同学的求助。自己挖的坑总要填的,若是进行简单的词频统计,很简单,涉及到将相同词频的词语排在一行并用 ## 连接,因为楼主水平有限,在实现的过程中还是遇到了不少的困难 。
一、简单实现词频统计
刚入手此题目,楼主的思路就是先实现一个简单的词频统计,然后在实现简单词频统计的基础上,对代码进行修改,实现相同词频的词语放在 一行使用 ## 连接。思路很简单,简单的词频统计实现的也非常顺利,但接下的思路实现起来便没有那么容易了。先来看一看简单的词频统计这个功能吧。
1. 首先先来写 Mapper 的功能,上代码:
public class WordHandlerMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs = StringUtils.split(value.toString(), "\t");
for(String str : strs) {
int index = str.indexOf("/");
if(index < 0) {
index = 0;
}
String word = str.substring(0, index);
context.write(new Text(word), new LongWritable(1));
}
}
}
WordHandlerMapper 类的功能,首先此类实现了 Mapper 类,重写了 mapper 方法,使用默认的 TextOutputFormat 类,将读取到的一行数据以形参 value 的形式传入 mapper 方法,第 7 行对这行数据也就是 value 进行处理,以 \t 进行分割,得到了一个 String 数组, 数组的形式为:["足协/j", "杯赛/n", "常/d"] 形式,然后 10 行对数组进行遍历,然后获取到 /之前的内容,也就是我们需要统计词频的词语,如 10 - 16 行所示,然后将得到的词语传入 context 的 write 方法,map 程序进行缓存和排序后,再传给 reduce 程序。
2. 然后再来看 Reduce 程序:
public class WordHandlerReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long count = 0;
for(LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
WordHandlerReducer 的逻辑很简单,此类继承了 Reduce,重写了 reduce 方法,传入的 key 即需要统计词频的词语,vaues 为 {1,1,1} 形式,8 行定义了一个计数器,然后对 values 进行增强 for 循环遍历,使计数器加 1,然后将词语和词频输出即可。
3. 然后我们再定义个类来描述这个特定的作业:
public class WordHandlerRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcJob = Job.getInstance(conf);
wcJob.setJarByClass(WordHandlerRunner.class);
wcJob.setMapperClass(WordHandlerMapper.class);
wcJob.setReducerClass(WordHandlerReducer.class);
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(LongWritable.class);
wcJob.setMapOutputKeyClass(Text.class);
wcJob.setMapOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(wcJob, new Path("/wc/srcdata2/"));
FileOutputFormat.setOutputPath(wcJob, new Path("/wc/wordhandler/"));
wcJob.waitForCompletion(true);
}
}
第 6 行得到 Job 对象,之后便是对一些基本参数的设置,基本上就是见方法名而知其意了 。 19 和 21 行定义存放元数据的路径和输入结果的路径,23行提交作业。
在 Eclipse 中将程序打成 jar 包,名为 wordhandler.jar 导出,上传到 Linux 服务器 ,将原始的语料处理文件上传到程序中指定了路径下,通过
hadoop jar wordhandler.jar com.software.hadoop.mr.wordhandler.WordHandlerRunner 命令执行,很快就会执行完毕,然后到输出路径中查看输出结果(图片展示部分结果):

到此简单的词频统计功能就到此结束了,观察可知,MapReduce 默认是按输出的 key 进行排序的。得到的数据距离题目要求的结果还有很大的悬殊,那么剩下需要进一步实现的还有两处,一处是将词频相同的词语放到一行并用 ## 连接,第二处就是对词频进行排序(按从大到小) 。
楼主的思路是,排序肯定是要放到最后一步实现,若先进行排序,在对相同词频的词语处理的话,很有可能会打乱之前的排序。那么,现在就是对词频相同的词语进行处理了,使它们显示在一行并用 ## 连接。在实现这个功能时,楼主遇到了困难,主要是对 TextOutputFarmat 默认只读取一行数据意识不够深入,走了许多的弯路,比如楼主相到修改 Hadoop 的源码,读取多行数据等,但由于楼主水平有限,结果以失败告终。到此时已经是夜里将近十二点了,因为到第二天还要早起,所以就没再熬夜,暂时放下了。
第二天中午,楼主想到了倒排索引,使用倒排索引实现的思路便一点一点形成。把我们之前得到的数据读入,然后将词频当做 key,这样 Mapper 程序便会在 Reduce 执行之前进行缓存和分类,思路来了,便马上动手实现。
二、使用倒排索引初步实现相同词频写入一行并用 ## 连接
1. 还是先来 Mapper 的功能:注意,这次读入的数据是我们之前得到的按默认的形式排好序,并统计出词频的数据。
public class WordHandlerMapper2 extends Mapper<LongWritable, Text, LongWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs = StringUtils.split(value.toString(), "\t");
String text = strs[0];
long count = Long.parseLong(strs[1]);
context.write(new LongWritable(count), new Text(text));
}
}
Map 的功能很简单,我们需要输出的 key 是 LongWritable 类型,value 是 Text 类型,即 [205, {"检验", "加入", "生存"}] 这种类型。第 7 行同样是对一行的数据进行拆分,然后得到 词语(text) 和 词频(count),然后 第 13 行进行输出即可,很简单。
2. Reduce 程序的功能:
public class WordHandlerReducer2 extends Reducer<LongWritable, Text, Text, LongWritable> {
//key: 3 values: {"研究","落实"}
@Override
protected void reduce(LongWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String result = "";
for(Text value : values) {
result += value.toString() + "##";
}
context.write(new Text(result), key);
}
}
Reduce 的逻辑比之前的稍微复杂一点,从 Mapper 中输入的数据格式为 [205, {"检验", "加入", "生存"}] 类型,我们希望输出的格式为:[检验##加入##生存 205], 重写的 reduce 方法传入的 values 即 {"检验", "加入", "生存"} 类型,第十行对 values 进行遍历,11 行向 result 中追加,即可得到我们需要的结果,然后 15 行进行输出。
3. 然后再来定义一个类来描述此作业,
public class WordHandlerRunner2 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcJob = Job.getInstance(conf);
wcJob.setJarByClass(WordHandlerRunner2.class);
wcJob.setMapperClass(WordHandlerMapper2.class);
wcJob.setReducerClass(WordHandlerReducer2.class);
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(LongWritable.class);
wcJob.setMapOutputKeyClass(LongWritable.class);
wcJob.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(wcJob, new Path("/wc/wordhandler/"));
FileOutputFormat.setOutputPath(wcJob, new Path("/wc/wordhandleroutput/"));
wcJob.waitForCompletion(true);
}
}
这个类与之前的那个 Job 描述类很类似,使用的 Job 的方法没有变化,方法的参数只做稍微修改即可,楼主标红的行即需要进行修改的行。
然后是同样的步骤,在 Eclipse 中将程序打成 jar 包导出,也叫 wordhandler.jar,然后上传到 Linux 服务器中,使用
hadoop jar wordhandler.jar com.software.hadoop.mr.wordhandler2.WordHandlerRunner2 进行运行,同过 Map 和 Reduce 的处理后,进入相应的目录下,查看结果(图片展示部分结果):

我们分析一下得到的结果,是不是距离题目要求的输出结果更接近了一步,但是还差点事,一个是每一行的最后多了一个 ##,这个好解决,在生成字符串的时候判断该词语是否为最后一个即可,另一个就是题目要求词频按从大到小的顺序输出,而我们的输出顺序是从小到大。明确了问题之后,继续开动吧。
三、实现按词频从大到小进行排序
排序问题是使用 Hadoop 进行词频处理的常见问题了,实现起来并不困难。说一说思路,因为我们这里是默认读取一行,那么我们构造一个 Word 类,此类有属性 text (内容),和(count)词频,此类需要实现 WritableComparable 接口,重写其中的方法,使用我们自定义的排序方式即可。既然思路明确了,那我们一步一步的实现。
1. 先定义一个 word 类:
public class Word implements WritableComparable<Word> {
private String text;
private long count;
public Word() {}
public Word(String text, long count) {
super();
this.text = text;
this.count = count;
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public long getCount() {
return count;
}
public void setCount(long count) {
this.count = count;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(text);
out.writeLong(count);
}
@Override
public void readFields(DataInput in) throws IOException {
text = in.readUTF();
count = in.readLong();
}
@Override
public int compareTo(Word o) {
return count > o.getCount() ? -1 : 1;
}
}
此类需要实现 WritableComparable 接口,重写第 32 行的 write 方法,第 38 行的 readFields 方法,第 44 行 compareTo 方法,32 行和 38 行的方法是 Hadoop 中序列化相关的方法,44 行 compareTo 方法才是我们自定义排序方式的方法。值的注意的是,write 方法中和 readFields 方法中属性的序列化和反序列化的顺序必须一致,即 33、34 和 39、40 行的属性需要对应。然后 compareTo 中 第 45 行实现自定义的从大到小的排序即可。
2. Mapper 类的功能:
public class WordHandlerMapper3 extends Mapper<LongWritable, Text, Word, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs = StringUtils.split(value.toString(), "\t");
String text = strs[0];
long count = Long.parseLong(strs[1]);
Word word = new Word(text, count);
context.write(word, NullWritable.get());
}
}
我们定义 Mapper 的输出的 key 为 Word 类型是排序成功的关键,在 mapper 方法中常规的拆分一行数据,获得到相应的字段,然后第 13 行封装为一个 Word 对象,第 15 行输出即可,楼主定义 Mapper 的输出的 vlaue 为 NullWritable 类型,思路为只要输出的 key 为 Word 型,那么我们就可以获取到需要的信息了。
2. 再来看 Reduce 的功能:
public class WordHandlerReducer3 extends Reducer<Word, NullWritable, Text, LongWritable> {
@Override
protected void reduce(Word key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(new Text(key.getText()), new LongWritable(key.getCount()));
}
}
Reduce 的功能再简单不过了,得到的 key 是一个一个的 Word ,6 行获取相应的字段输出即可。
3. 再来描述排序这个特定的作业,代码与之前的类似,只做稍微修改即可,代码楼主就不贴出来了。这样我们排序的功能就实现了,然后在 Linux 中通过命令运行,将得到的结果导出到 Windows 中,重命名为 postagmodel.txt 即可,此文件共 1163 行,现在贴一下部分结果的图片:
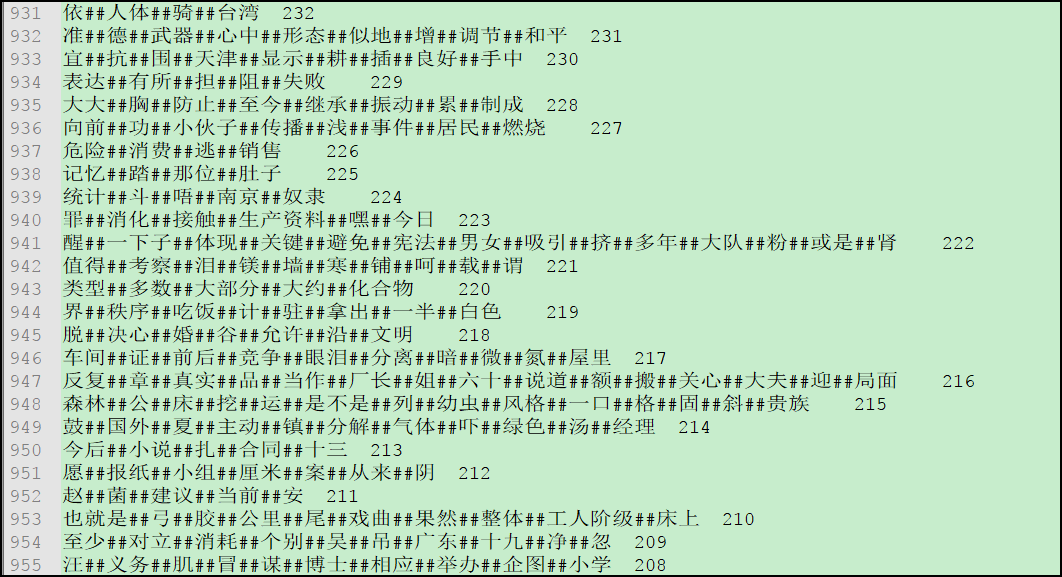
结果出来了,基本与题目要求吻合,楼主松了一口气。
在实现功能之后楼主稍微总结了一下:
可能由于经验不足,遇到问题不知如何解决,积累经验尤为重要,毕竟经验这个问题不是短时间内形成的,多学多敲多练是根本;
然后,一个功能或者一个需求的实现,何为简单,何为困难,楼主认为最终如果我们实现了这个功能或需求,回过头来看,它就是简单的,此时也有可能是熟练度的问题,使它蒙上了那层困难的面纱,遇到困难,别放弃,学会短暂性舍弃,过段时间再捡起来,可能灵感就来了。
还需要说一点,此功能的实现楼主的思路和方法可能不是最好的,也有可能会有不妥的地方存在,欢迎大家一块交流学习,若有不足之处,还请指出,留言、评论、邮箱楼主均可。
使用 Hadoop 进行语料处理(面试题)的更多相关文章
- Hadoop,MapReduce,HDFS面试题
今天发这个的目的是为了给自己扫开迷茫,告诉自己该进阶了,下面内容不一定官方和正确.全然个人理解,欢迎大家留言讨论 1.什么是hadoop 答:是google的核心算法MapReduce的一个开源实现. ...
- 弄清Spark、Storm、MapReduce的这几点区别才能学好大数据
很多初学者在刚刚接触大数据的时候会有很多疑惑,比如对MapReduce.Storm.Spark三个计算框架的理解经常会产生混乱. 哪一个适合对大量数据进行处理?哪一个又适合对实时的流数据进行处理?又该 ...
- Hadoop 之面试题
颜色区别: 蓝色:hive,橙色:Hbase.黑色hadoop 请简述hadoop怎样实现二级排序. 你认为用Java,Streaming,pipe 方式开发map/reduce,各有哪些优缺点: 6 ...
- Hadoop 面试题redis
Hadoop 面试题之十 548.redis有什么特别之处,为什么用redis,用hbase 不行么? 答:redis 是基于内存的数据库,速度快 551.redis用什么版本? 3.0以上才支持集群 ...
- Hadoop 面试题之Hbase
Hadoop 面试题之九 16.Hbase 的rowkey 怎么创建比较好?列族怎么创建比较好? 答: 19.Hbase 内部是什么机制? 答: 73.hbase 写数据的原理是什么? 答: 75.h ...
- Hadoop 面试题之storm 3个
Hadoop 面试题之八 355.metaq 消息队列 zookeeper 集群 storm集群(包括 zeromq,jzmq,和 storm 本身)就可以完成对商城推荐系统功能吗?还有其他的中间件? ...
- hadoop面试题答案
Hadoop 面试题,看看书找答案,看看你能答对多少(2) 1. 下面哪个程序负责 HDFS 数据存储.a)NameNode b)Jobtracker c)Datanode d)secondary ...
- hadoop+海量数据面试题汇总(二)
何谓海量数据处理? 所谓海量数据处理,无非就是基于海量数据上的存储.处理.操作.何谓海量,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存. 那解决办法呢 ...
- hadoop+海量数据面试题汇总(一)
hadoop面试题 Q1. Name the most common InputFormats defined in Hadoop? Which one is default ? Following ...
随机推荐
- hibernate中Query的list和iterator区别
1.Test_query_list类 public class Test_query_iterator_list { public static void main(String[] args) { ...
- JavaEE学习路线
针对很多初识Java者,对如何学习Java.如何学好Java很迷茫,最近刚把JavaEE的东西学完,把我的学习的经验分享给大家,一条适合大多数人的学习路线. 第一部分:Java语言入门阶段 第二部分: ...
- MongoDB 分布式架构 复制 分片 适用性范围
转载自 http://www.mongoing.com/archives/3573
- 方法--printStackTrace()
java抛出异常的方法有很多,其中最常用的两个: System.out.println(e),这个方法打印出异常,并且输出在哪里出现的异常,不过它和另外一个e.printStackTrace()方法不 ...
- Android方法数不能超过65535
为什么方法数不能超过65535?搬上Dalvik工程师在SF上的回答,因为在Dalvik指令集里,调用方法的invoke-kind指令中,method reference index只给了16bits ...
- 不可不知的socket和TCP连接过程
html { font-family: sans-serif } body { margin: 0 } article,aside,details,figcaption,figure,footer,h ...
- kmp next数组的理解(挺好的一篇文章 ,原来kmp最初的next是这样的啊,很好理解)
KMP算法的next[]数组通俗解释 我们在一个母字符串中查找一个子字符串有很多方法.KMP是一种最常见的改进算法,它可以在匹配过程中失配的情况下,有效地多往后面跳几个字符,加快匹配速度. 当然我 ...
- hdu3729二分匹配
I'm Telling the Truth Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- http://codeforces.com/contest/402/problem/E
E. Strictly Positive Matrix time limit per test 1 second memory limit per test 256 megabytes input s ...
- 如何维护一个1000 IP的免费代理池
楔子 好友李博士要买房了, 前几天应邀帮他抓链家的数据分析下房价, 爬到一半遇到了验证码. 李博士的想法是每天把链家在售的二手房数据都抓一遍, 然后按照时间序列分析. 链家线上在交易的二手房数据大概有 ...