【机器学习】人工神经网络ANN
感谢中国人民大学的胡鹤老师,课程理论实践结合,讲得很好~
神经网络是从生物领域自然的鬼斧神工中学习智慧的一种应用。人工神经网络(ANN)的发展经历的了几次高潮低谷,如今,随着数据爆发、硬件计算能力暴增、深度学习算法的优化,我们迎来了又一次的ANN雄起时代,以深度学习为首的人工神经网络,又一次走入人们的视野。
感知机模型perceptron
不再处理离散情况,而是连续的数值,学习时权值在变化,从而记忆存储学到的知识
神经元输入:类似于线性回归z =w1x1+w2x2 +⋯ +wnxn= wT・x(linear threshold unit (LTU))
神经元输出:激活函数,类似于二值分类,模拟了生物学中神经元只有激发和抑制两种状态。
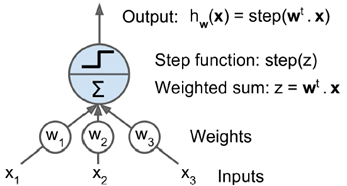
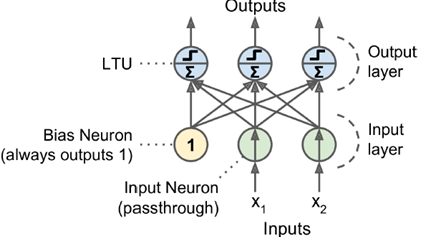
增加偏值,输出层哪个节点权重大,输出哪一个。
采用Hebb准则,下一个权重调整方法参考当前权重和训练效果
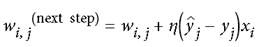
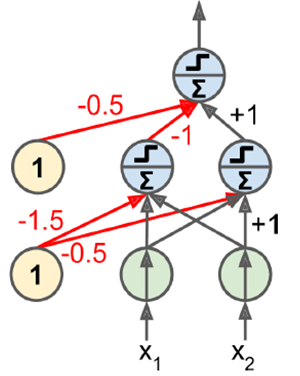
#一个感知机的例子
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # petal length, petal width
y = (iris.target == 0).astype(np.int) # Iris Setosa?
per_clf = Perceptron(random_state=42)
per_clf.fit(X, y)
y_pred = per_clf.predict([[2, 0.5]]
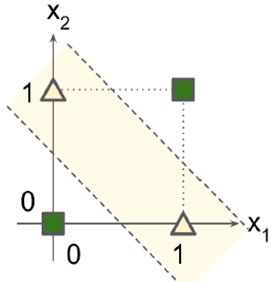
之后有人提出,perceptron无法处理异或问题,但是,使用多层感知机(MLP)可以处理这个问题
def heaviside(z):
return (z >= 0).astype(z.dtype)
def sigmoid(z):
return 1/(1+np.exp(-z))
#做了多层activation,手工配置权重
def mlp_xor(x1, x2, activation=heaviside):
return activation(-activation(x1 + x2 - 1.5) + activation(x1 + x2 - 0.5) - 0.5)
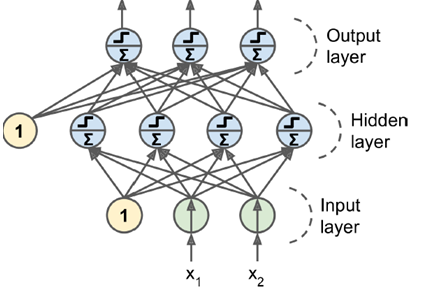
如图所示,两层MLP,包含输入层,隐层,输出层。所谓的深度神经网络,就是隐层数量多一些。
激活函数
以下是几个激活函数的例子,其微分如右图所示
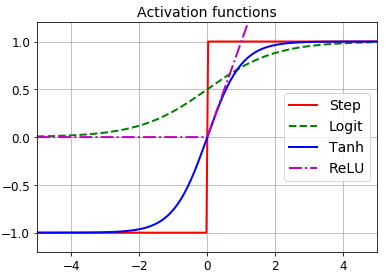
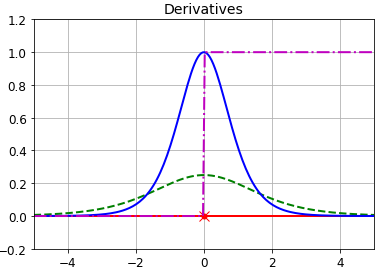
step是最早提出的一种激活函数,但是它在除0外所有点的微分都是0,没有办法计算梯度
logit和双曲正切函数tanh梯度消失,数据量很大时,梯度无限趋近于0,
relu在层次很深时梯度也不为0,无限传导下去。
如何自动化学习计算权重——backpropagation
首先正向做一个计算,根据当前输出做一个error计算,作为指导信号反向调整前一层输出权重使其落入一个合理区间,反复这样调整到第一层,每轮调整都有一个学习率,调整结束后,网络越来越合理。
step函数换成逻辑回归函数σ(z) = 1 / (1 + exp(–z)),无论x落在哪个区域,最后都有一个非0的梯度可以使用,落在(0,1)区间。
双曲正切函数The hyperbolic tangent function tanh (z) = 2σ(2z) – 1,在(-1,1)的区间。
The ReLU function ReLU (z) = max (0, z),层次很深时不会越传递越小。
多分类时,使用softmax(logistics激活函数)最为常见。
使用MLP多分类输出层为softmax,隐层倾向于使用ReLU,因为向前传递时不会有数值越来越小得不到训练的情况产生。
以mnist数据集为例
import tensorflow as tf # construction phase
n_inputs = 28*28 # MNIST
# 隐藏层节点数目
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10 X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
def neuron_layer(X, n_neurons, name, activation=None):
with tf.name_scope(name):
n_inputs = int(X.get_shape()[1])
# 标准差初始设定,研究证明设为以下结果训练更快
stddev = 2 / np.sqrt(n_inputs)
# 使用截断的正态分布,过滤掉极端的数据,做了一个初始权重矩阵,是input和neurons的全连接矩阵
init = tf.truncated_normal((n_inputs, n_neurons), stddev=stddev)
W = tf.Variable(init, name="weights")
# biases项初始化为0
b = tf.Variable(tf.zeros([n_neurons]), name="biases")
# 该层输出
z = tf.matmul(X, W) + b
# 根据activation选择激活函数
if activation=="relu":
return tf.nn.relu(z)
else:
return z with tf.name_scope("dnn"):
# 算上输入层一共4层的dnn结构
hidden1 = neuron_layer(X, n_hidden1, "hidden1", activation="relu")
hidden2 = neuron_layer(hidden1, n_hidden2, "hidden2", activation="relu")
# 直接输出最后结果值
logits = neuron_layer(hidden2, n_outputs, "outputs") # 使用TensorFlow自带函数实现,最新修改成dense函数
from tensorflow.contrib.layers import fully_connected
with tf.name_scope("dnn"):
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2")
logits = fully_connected(hidden2, n_outputs, scope="outputs", activation_fn=None) # 使用logits(网络输出)计算交叉熵,取均值为误差
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss") learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss) with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) init = tf.global_variables_initializer()
saver = tf.train.Saver() # Execution Phase
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
# 外层大循环跑400次,每个循环中小循环数据量50
n_epochs = 400
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: mnist.test.images,y: mnist.test.labels})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test) # 下次再跑模型时不用再次训练了
save_path = saver.save(sess, "./my_model_final.ckpt") # 下次调用
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt") # or better, use save_path
X_new_scaled = mnist.test.images[:20]
Z = logits.eval(feed_dict={X: X_new_scaled})
y_pred = np.argmax(Z, axis=1)
超参数设置
隐层数量:一般来说单个隐层即可,对于复杂问题,由于深层模型可以实现浅层的指数级别的效果,且每层节点数不多,加至overfit就不要再加了。
每层神经元数量:以漏斗形逐层递减,输入层最多,逐渐features更少代表性更强。
激活函数选择(activation function):隐层多选择ReLU,输出层多选择softmax
【机器学习】人工神经网络ANN的更多相关文章
- 机器学习笔记之人工神经网络(ANN)
人工神经网络(ANN)提供了一种普遍而且实际的方法从样例中学习值为实数.离散值或向量函数.人工神经网络由一系列简单的单元相互连接构成,其中每个单元有一定数量的实值输入,并产生单一的实值输出. 上面是一 ...
- 人工神经网络--ANN
神经网络是一门重要的机器学习技术.它是目前最为火热的研究方向--深度学习的基础.学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术. 本文以一种简单的,循序的方 ...
- python大战机器学习——人工神经网络
人工神经网络是有一系列简单的单元相互紧密联系构成的,每个单元有一定数量的实数输入和唯一的实数输出.神经网络的一个重要的用途就是接受和处理传感器产生的复杂的输入并进行自适应性的学习,是一种模式匹配算法, ...
- 吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
import numpy as np from matplotlib import pyplot as plt from sklearn import neighbors, datasets from ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- [数据挖掘课程笔记]人工神经网络(ANN)
人工神经网络(Artificial Neural Networks)顾名思义,是模仿人大脑神经元结构的模型.上图是一个有隐含层的人工神经网络模型.X = (x1,x2,..,xm)是ANN的输入,也就 ...
- 【机器学习】神经网络实现异或(XOR)
注:在吴恩达老师讲的[机器学习]课程中,最开始介绍神经网络的应用时就介绍了含有一个隐藏层的神经网络可以解决异或问题,而这是单层神经网络(也叫感知机)做不到了,当时就觉得非常神奇,之后就一直打算自己实现 ...
- 人工神经网络入门(4) —— AFORGE.NET简介
范例程序下载:http://files.cnblogs.com/gpcuster/ANN3.rar如果您有疑问,可以先参考 FAQ 如果您未找到满意的答案,可以在下面留言:) 0 目录人工神经网络入门 ...
- 人工神经网络 Artificial Neural Network
2017-12-18 23:42:33 一.什么是深度学习 深度学习(deep neural network)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高 ...
随机推荐
- linux上redis安装配置及其防漏洞配置及其攻击方法
Linux上redis安装: 需先在服务器上安装yum(虚拟机可使用挂载的方式安装) 安装配置所需要的环境运行指令: yum -y install gcc 进入解压文件执行make 指令进行编译 执 ...
- YYHS-手机信号
题目描述 输入 输出 样例输入 11 10000 query 5 construct 5 500 100 query 500 query 1000 construct 10 90 5 query 44 ...
- 张高兴的 Windows 10 IoT 开发笔记:三轴数字罗盘 HMC5883L
注意,数据不包含校验,准确的来说我不知道怎么校验,但方向看起来差不多是对的... GitHub:https://github.com/ZhangGaoxing/windows-iot-demo/tre ...
- shell编程/字库裁剪(1)
我写这个帖子的意图,在于三个: 1.用代码生成代码的思维. 2.shell编程的思路. 3.裁剪字库的具体程序. 我打算分为三节来说: 第一节讲裁剪裁剪词库的意义以及使用场合: 第二节讲如何用shel ...
- checkbox插件
1.全选或者全不选 首先判断全选或全不选checkbox是否被选中. 如果被选中,则为每个选项checkbox设置obj.checked='checked'; 如果未被选中,则为每个选项checkbo ...
- 如何在不同的语言/平台中获取Android ID
如何在不同的语言/平台中获取Android ID 最近开发工作中需要使用到AndroidID,在Unity和native code中也需要使用,java获取很方便,Unity中也不难,最难的是在nat ...
- (转)MySQL存储过程/存储过程与自定义函数的区别
转自:http://www.cnblogs.com/caoruiy/p/4486249.html 语法: 创建存储过程: CREATE [definer = {user|current_user}] ...
- ASP.NET Core 企业级开发架构简介及框架汇总
企业开发框架包括垂直方向架构和水平方向架构.垂直方向架构是指一个应用程序的由下到上叠加多层的架构,同时这样的程序又叫整体式程序.水平方向架构是指将大应用分成若干小的应用实现系统功能的架构,同时这样的系 ...
- N厂劳力士黑水鬼V7出了1年,如今依旧被追捧,供不应求
今天和大家一起来谈谈,风靡复刻界的潜航者,国人眼中的一劳永逸,何为一劳永逸,即(用这个腕表能省很多事)真的有这么牛?其实不然只要是机械腕表都会有或多或少的问题,一劳永逸更多的是指腕表的质量给力,所谓潜 ...
- Install a Redmine on Ubuntu system
# How to install a Redmine on Ubuntu system Ref to: https://www.linode.com/docs/applications/project ...