AdaBoost入门
写一点自己理解的AdaBoost,然后再贴上面试过程中被问到的相关问题。按照以下目录展开。
当然,也可以去我的博客上看
- Boosting提升算法
- AdaBoost
- 原理理解
- 实例
- 算法流程
- 公式推导
- 面经
Boosting提升算法
AdaBoost是典型的Boosting算法,属于Boosting家族的一员。在说AdaBoost之前,先说说Boosting提升算法。Boosting算法是将“弱学习算法“提升为“强学习算法”的过程,主要思想是“三个臭皮匠顶个诸葛亮”。一般来说,找到弱学习算法要相对容易一些,然后通过反复学习得到一系列弱分类器,组合这些弱分类器得到一个强分类器。Boosting算法要涉及到两个部分,加法模型和前向分步算法。加法模型就是说强分类器由一系列弱分类器线性相加而成。一般组合形式如下:
$$F_M(x;P)=\sum_{m=1}^nβ_mh(x;a_m)$$
其中,$h(x;a_m)$ 就是一个个的弱分类器,$a_m$是弱分类器学习到的最优参数,$β_m$就是弱学习在强分类器中所占比重,$P$是所有$a_m$和$β_m$的组合。这些弱分类器线性相加组成强分类器。
前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以写成这样的形式:
$$F_m (x)=F_{m-1}(x)+ β_mh_m (x;a_m)$$
由于采用的损失函数不同,Boosting算法也因此有了不同的类型,AdaBoost就是损失函数为指数损失的Boosting算法。
AdaBoost
原理理解
基于Boosting的理解,对于AdaBoost,我们要搞清楚两点:
- 每一次迭代的弱学习$h(x;a_m)$有何不一样,如何学习?
- 弱分类器权值$β_m$如何确定?
对于第一个问题,AdaBoost改变了训练数据的权值,也就是样本的概率分布,其思想是将关注点放在被错误分类的样本上,减小上一轮被正确分类的样本权值,提高那些被错误分类的样本权值。然后,再根据所采用的一些基本机器学习算法进行学习,比如逻辑回归。
对于第二个问题,AdaBoost采用加权多数表决的方法,加大分类误差率小的弱分类器的权重,减小分类误差率大的弱分类器的权重。这个很好理解,正确率高分得好的弱分类器在强分类器中当然应该有较大的发言权。
实例
为了加深理解,我们来举一个例子。
有如下的训练样本,我们需要构建强分类器对其进行分类。x是特征,y是标签。
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
令权值分布$D_1=(w_{1,1},w_{1,2},…,w_{1,10} )$
并假设一开始的权值分布是均匀分布:$w_{1,i}=0.1,i=1,2,…,10$
现在开始训练第一个弱分类器。我们发现阈值取2.5时分类误差率最低,得到弱分类器为:
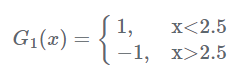
当然,也可以用别的弱分类器,只要误差率最低即可。这里为了方便,用了分段函数。得到了分类误差率$e_1=0.3$。
第二步计算$(G_1 (x)$在强分类器中的系数$α_1=\frac{1}{2} log\frac{ 1-e_1}{e_1}=0.4236$,这个公式先放在这里,下面再做推导。
第三步更新样本的权值分布,用于下一轮迭代训练。由公式:
$$w_{2,i}=\frac{w_{1,i}}{z_1}exp(-α_1 y_i G_1 (x_i )),i=1,2,…,10$$
得到新的权值分布,从各0.1变成了:
$$D_2=(0.0715,0.0715,0.0715,0.0715,0.0715,0.0715,0.1666,0.1666,0.1666,0.0715)$$
可以看出,被分类正确的样本权值减小了,被错误分类的样本权值提高了。
第四步得到第一轮迭代的强分类器:
$$sign(F_1 (x))=sign(0.4236G_1 (x))$$
以此类推,经过第二轮……第N轮,迭代多次直至得到最终的强分类器。迭代范围可以自己定义,比如限定收敛阈值,分类误差率小于某一个值就停止迭代,比如限定迭代次数,迭代1000次停止。这里数据简单,在第3轮迭代时,得到强分类器:
$$sign(F_3 (x))=sign(0.4236G_1 (x)+0.6496G_2 (x)+0.7514G_3 (x))$$
的分类误差率为0,结束迭代。
$F(x)=sign(F_3 (x))$就是最终的强分类器。
算法流程
总结一下,得到AdaBoost的算法流程:
- 输入:训练数据集$T=\{(x_1,y_1),(x_2,y_2),(x_N,y_N)\}$,其中,$x_i∈X⊆R^n$,$y_i∈Y={-1,1}$,迭代次数$M$
- 1. 初始化训练样本的权值分布:$D_1=(w_{1,1},w_{1,2},…,w_{1,i}),w_{1,i}=\frac{1}{N},i=1,2,…,N$。
- 2. 对于$m=1,2,…,M$
- (a) 使用具有权值分布$D_m$的训练数据集进行学习,得到弱分类器$G_m (x)$
- (b) 计算$G_m(x)$在训练数据集上的分类误差率:
$$e_m=\sum_{i=1}^Nw_{m,i} I(G_m (x_i )≠y_i )$$
- (c) 计算$G_m (x)$在强分类器中所占的权重:
$$α_m=\frac{1}{2}log \frac{1-e_m}{e_m} $$
- (d) 更新训练数据集的权值分布(这里,$z_m$是归一化因子,为了使样本的概率分布和为1):
$$w_{m+1,i}=\frac{w_{m,i}}{z_m}exp(-α_m y_i G_m (x_i )),i=1,2,…,10$$
$$z_m=\sum_{i=1}^Nw_{m,i}exp(-α_m y_i G_m (x_i ))$$
- 3. 得到最终分类器:
$$F(x)=sign(\sum_{i=1}^Nα_m G_m (x))$$
公式推导
现在我们来搞清楚上述公式是怎么来的。
假设已经经过$m-1$轮迭代,得到$F_{m-1} (x)$,根据前向分步,我们可以得到:
$$F_m (x)=F_{m-1} (x)+α_m G_m (x)$$
我们已经知道AdaBoost是采用指数损失,由此可以得到损失函数:
$$Loss=\sum_{i=1}^Nexp(-y_i F_m (x_i ))=\sum_{i=1}^Nexp(-y_i (F_{m-1} (x_i )+α_m G_m (x_i )))$$
这时候,$F_{m-1}(x)$是已知的,可以作为常量移到前面去:
$$Loss=\sum_{i=1}^N\widetilde{w_{m,i}} exp(-y_i α_m G_m (x_i ))$$
其中,$\widetilde{w_{m,i}}=exp(-y_i (F_{m-1} (x)))$ ,敲黑板!这个就是每轮迭代的样本权重!依赖于前一轮的迭代重分配。
是不是觉得还不够像?那就再化简一下:
$$\widetilde{w_{m,i}}=exp(-y_i (F_{m-1} (x_i )+α_{m-1} G_{m-1} (x_i )))=\widetilde{w_{m-1,i}} exp(-y_i α_{m-1} G_{m-1} (x_i ))$$
现在够像了吧?ok,我们继续化简Loss:
$$Loss=\sum_{y_i=G_m(x_i)}\widetilde{w_{m,i}} exp(-α_m)+\sum_{y_i≠G_m(x_i)}\widetilde{w_{m,i}} exp(α_m)$$
$$=\sum_{i=1}^N\widetilde{w_{m,i}}(\frac{\sum_{y_i=G_m(x_i)}\widetilde{w_{m,i}}}{\sum_{i=1}^N\widetilde{w_{m,i}}}exp(-α_m)+\frac{\sum_{y_i≠G_m(x_i)}\widetilde{w_{m,i}}}{\sum_{i=1}^N\widetilde{w_{m,i}}}exp(α_m))$$
公式变形之后,炒鸡激动!$\frac{\sum_{y_i≠G_m(x_i)}\widetilde{w_{m,i}}}{\sum_{i=1}^N\widetilde{w_{m,i}}}$这个不就是分类误差率$e_m$吗???!重写一下,
$$Loss=\sum_{i=1}^N\widetilde{w_{m,i}}exp(-α_m)+e_m exp(α_m))$$
Ok,这样我们就得到了化简之后的损失函数。接下来就是求导了。
对$α_m$求偏导,令$\frac{∂Loss}{∂α_m }=0$得到:
$$α_m=\frac{1}{2}log\frac{1-e_m}{e_m} $$
真漂亮!
另外,AdaBoost的代码实战与详解请戳代码实战之AdaBoost
面经
今年8月开始找工作,参加大厂面试问到的相关问题有如下几点:
1、手推AdaBoost
2、与GBDT比较
3、AdaBoost几种基本机器学习算法哪个抗噪能力最强,哪个对重采样不敏感?
AdaBoost入门的更多相关文章
- Adaboost入门教程——最通俗易懂的原理介绍(图文实例)
https://blog.csdn.net/px_528/article/details/72963977 写在前面 说到Adaboost,公式与代码网上到处都有,<统计学习方法>里面有详 ...
- 100天搞定机器学习|Day57 Adaboost知识手册(理论篇)
Boosting算法 Boosting是一种用来提高弱分类器准确度的算法,是将"弱学习算法"提升为"强学习算法"的过程,主要思想是"三个臭皮匠顶个诸葛 ...
- 机器学习笔记·adaboost
一.算法简介 Adaboost算法是一种集成算法,所谓集成算法就是将多个弱的分类器组合在一起变成一个强的分类器.弱分类器通常是指分类效果比随机分类稍微好一点的分类器.就像我们在做一个重要决定的时候,通 ...
- [白话解析] 通俗解析集成学习之bagging,boosting & 随机森林
[白话解析] 通俗解析集成学习之bagging,boosting & 随机森林 0x00 摘要 本文将尽量使用通俗易懂的方式,尽可能不涉及数学公式,而是从整体的思路上来看,运用感性直觉的思考来 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- 【转载】GBDT(MART) 迭代决策树入门教程 | 简介
转载地址:http://blog.csdn.net/w28971023/article/details/8240756 GBDT(Gradient Boosting Decision Tree) 又叫 ...
- 转:GBDT(MART) 迭代决策树入门教程 | 简介
在网上看到一篇对从代码层面理解gbdt比较好的文章,转载记录一下: GBDT(Gradient Boosting Decision Tree) 又 叫 MART(Multiple Additive R ...
- 16-GDBT(MART) 迭代决策树入门教程 | 简介
转载:http://blog.csdn.net/w28971023/article/details/8240756 GBDT(Gradient Boosting Decision Tree) 又叫 M ...
- xgboost入门与实战(原理篇)
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
随机推荐
- (转自知乎https://www.zhihu.com/question/20794107)动态代理
作者:雨夜偷牛的人链接:https://www.zhihu.com/question/20794107/answer/23330381来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- Java加密与解密笔记(二) 对称加密
前面的仅仅是做了编码或者摘要,下面看看真正的加密技术. DES public class DESUtil { static final String ALGORITHM = "DES&quo ...
- WebUploader上传文件(一)
写在前面: 文件上传方式很多的,对于大文件的上传,在本次项目中也有涉及,主要是用了分片断点上传大文件.所以就去了解了一下WebUploader,先从简单的上传文件开始吧~ 在代码中写注释,这样看的比较 ...
- 多表连接时USING和ON的区别,USING会去掉重复列,ON显示重复列。
- 通过 JS 实现简单的拖拽功能并且可以在特定元素上禁止拖拽
前言 关于讲解 JS 的拖拽功能的文章数不胜数,我确实没有必要大费周章再写一篇重复的文章来吸引眼球.本文的重点是讲解如何在某些特定的元素上禁止拖拽.这是我在编写插件时遇到的问题,其实很多插件的拖拽功能 ...
- qt中进程的使用
qt中的进程使用需要用到头文件:include<QProcess> 首先来看看需要用到的主要的函数 (1)进程的定义: QProcess *mprocess; //定义一个进程参数 (2) ...
- Sublime Text 使用教程
Sublime Text 是一款非常轻量级而且功能十分强大的编辑器,支持大量插件,深受前端开发者的喜爱.多的不说,我们直接进入正题. 1.下载 ①.官网下载地址:http://www.sublimet ...
- popupwindow那些坑
1. new PopupWindow(vw, ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT); 如果 ...
- Python random模块sample、randint、shuffle、choice随机函数概念和应用
Python标准库中的random函数,可以生成随机浮点数.整数.字符串,甚至帮助你随机选择列表序 列中的一个元素,打乱一组数据等. random中的一些重要函数的用法: 1 ).random() 返 ...
- 使用plenv安装perl,并使其支持多线程
plenv与pyenv.rbenv等都是同类型软件中非常好用的,这三个软件不仅命名类似,操作方式也相差无几,节约了很多学习的成本,所以非常推荐: 安装使用plenv: git clone git:// ...