Apache Hadoop YARN: 背景及概述
从2012年8月开始Apache Hadoop YARN(YARN = Yet Another Resource Negotiator)成了Apache Hadoop的一项子工程。自此Apache Hadoop由下面四个子工程组成:
- Hadoop Comon:核心库,为其他部分服务
- Hadoop HDFS:分布式存储系统
- Hadoop MapReduce:MapReduce模型的开源实现
- Hadoop YARN:新一代Hadoop数据处理框架
概括来说,Hadoop YARN的目的是使得Hadoop数据处理能力超越MapReduce。众所周知,Hadoop HDFS是Hadoop的数据存储层,Hadoop MapReduce是数据处理层。然而,MapReduce已经不能满足今天广泛的数据处理需求,如实时/准实时计算,图计算等。而Hadoop YARN提供了一个更加通用的资源管理和分布式应用框架。在这个框架上,用户可以根据自己需求,实现定制化的数据处理应用。而Hadoop MapReduce也是YARN上的一个应用。我们将会看到MPI,图处理,在线服务等(例如Spark,Storm,HBase)都会和Hadoop MapReduce一样成为YARN上的应用。下面将分别介绍传统的Hadoop MapReduce以及新一代Hadoop YARN架构。
传统的Apache Hadoop MapReduce架构
传统的Apache Hadoop MapReduce系统由JobTracker和TaskTracker组成。其中JobTracker是master,只有一个;TaskTracker是slaves,每个节点部署一个。
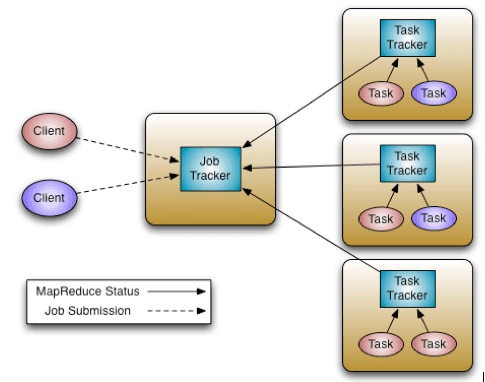
图 1 Apache Hadoop MapReduce系统架构
JobTracker负责资源管理(通过管理TaskTracker节点),追踪资源消费/释放,以及Job的生命周期管理(调度Job的每个Task,追踪Task进度,为Task提供容错等)。而TaskTracker的职责很简单,依次启动和停止由JobTracker分配的Task,并且周期性的向JobTracker汇报Task进度及状态信息。
Apache Hadoop YARN架构
YARN的最基本思想是将JobTracker的两个主要职责:资源管理和Job调度管理分别交给两个角色负责。一个是全局的ResourceManager,一个是每个应用一个的ApplicationMaster。ResourceManager以及每个节点一个的NodeManager构成了新的通用系统,实现以分布式方式管理应用。
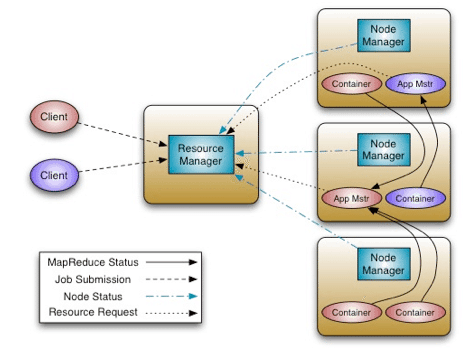
图2 Apache Hadoop YARN架构
ResourceManager是系统中仲裁应用之间资源分配的最高权威。而每个应用一个的ApplicationMaster负责向ResourceManager协商资源,并与NodeManager协同工作来执行和管理task。ResourceManager有一个可插入的调度器,负责向各个应用分配资源以满足容量,组等限制。这个调度器是一个纯粹的调度器,意思是它不负责管理或追踪应用的状态,也不负责由于硬件错误或应用问题导致的task失败重启工作。调度器只依据应用的资源需求来执行调度工作,调度内容是一个抽象概念Resource Container,其中包含了资源元素,例如内存,CPU,网络,磁盘等。
NodeManager是每个节点一个的slave,其负责启动应用的container,管理他们的资源使用(内存,CPU,网络,磁盘),并向ResourceManager汇报整体的资源使用情况。
每个应用一个的ApplicationMaster负责向ResourceManager的调度器协商合理的Resource Container并追踪他们的状态,管理进度。从系统角度看,ApplicationMaster本身也是以一个普通container的形式执行。
总结
由于MapReduce在计算模型方面的局限性,Hadoop实现了更加通用的资源管理系统YARN,并将MapReduce作为其一个应用。在YARN上可以实现多种多样计算模型的应用以满足业务需要。另外由于YARN系统将JobTracker的主要工作进行切分,使得master的压力大大减小(ResourceManager承担的工作量远小于JobTracker),这样YARN系统就可以支持更大的集群规模。
转载地址:http://blog.csdn.net/liangliyin/article/details/20729281
参考资料:
【1】http://hortonworks.com/blog/introducing-apache-hadoop-yarn/
【2】http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/
【3】http://hadoop.apache.org/
Apache Hadoop YARN: 背景及概述的更多相关文章
- hadoop错误org.apache.hadoop.yarn.exceptions.YarnException Unauthorized request to start container
错误: 14/04/29 02:45:07 INFO mapreduce.Job: Job job_1398704073313_0021 failed with state FAILED due to ...
- Hadoop -YARN 应用程序设计概述
一概述 应用程序是用户编写的处理数据的统称,它从YARN中申请资源完毕自己的计算任务.YARN自身相应用程序类型没有不论什么限制,它能够是处理短类型任务的MapReduce作业,也能够是 ...
- Apache Hadoop YARN – NodeManager--转载
原文地址:http://zh.hortonworks.com/blog/apache-hadoop-yarn-nodemanager/ The NodeManager (NM) is YARN’s p ...
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
- spark 笔记 4:Apache Hadoop YARN: Yet Another Resource Negotiator
spark支持YARN做资源调度器,所以YARN的原理还是应该知道的:http://www.socc2013.org/home/program/a5-vavilapalli.pdf 但总体来说, ...
- Apache Hadoop YARN – ResourceManager--转载
原文地址:http://zh.hortonworks.com/blog/apache-hadoop-yarn-resourcemanager/ ResourceManager (RM) is the ...
- org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService: mapreduce_shuffle do
在yarn-site.xml 配置文件中增加: <property> <name>yarn.nodemanager.aux-services</name> < ...
- Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/exceptions/YarnException
这个是Flink 1.11.1 使用yarn-session 出现的错误:原因是在Flink1.11 之后不再提供flink-shaded-hadoop-*” jars 需要在yarn-sessio ...
- Caused by:java.lang.ClassNotFoundException:org.apache.hadoop.yarn.util.Apps
错误原因 缺少hadoop-yarn.jar包. 导入jar包就好了~-~
随机推荐
- poj 3009 冰球 【DFS】求最小步数
题目链接:https://vjudge.net/problem/POJ-3009 转载于:https://www.cnblogs.com/Ash-ly/p/5728439.html 题目大意: 要求把 ...
- ThreadPoolExecutor 源码阅读
目录 ThreadPoolExecutor 源码阅读 Executor 框架 Executor ExecutorService AbstractExecutorService 构造器 状态 Worke ...
- IntelliJ IDEA关于logger的live template配置
1.安装 log support2插件 2.配置log support2 由于项目中的日志框架是公司自己封装的,所以还需要自己手动改一下 log support2插件生成的live template ...
- BZOJ.4767.两双手(组合 容斥 DP)
题目链接 \(Description\) 棋盘上\((0,0)\)处有一个棋子.棋子只有两种走法,分别对应向量\((A_x,A_y),(B_x,B_y)\).同时棋盘上有\(n\)个障碍点\((x_i ...
- BZOJ.4753.[JSOI2016]最佳团体(01分数规划 树形背包DP)
题目链接 \(Description\) 每个点有费用si与价值pi,要求选一些带根的连通块,总大小为k,使得 \(\frac{∑pi}{∑si}\) 最大 \(Solution\) 01分数规划,然 ...
- Python图形编程探索系列-08-再次认识标签
标签的各种属性 代码展示: import tkinter as tk root = tk.Tk() root.geometry = '500x300' label1 = tk.Label(root, ...
- Python3NumPy——常用函数
Python3NumPy的常用函数 1. txt文件 (1) 单位矩阵,即主对角线上的元素均为1,其余元素均为0的正方形矩阵. 在NumPy中可以用eye函数创建一个这样的二维数组,我们只需要给定一个 ...
- LVS 之搭建
部署LVS 10.0.0.20 [root@node1 ~]# yum -y install ipvsadm 进入到 /usr/src 目录查看结果,如果有ip_vs_rr.ip_vs,表示正常 [r ...
- linux中 判断变量中是否有给定元素
grep find都是查找文件 所以shell编程时使用=~ 来进行变量中的匹配. 注意:if条件后面是两个[]. #!/bin/basha="abc.txt bde.txt ccc.txt ...
- Python打包方法——Pyinstaller
Python版本:Python3.5.2 一.安装Pyinstaller 1.安装pywin32 下载安装文件:查找到跟自己适用的python版本及window系统版本匹配的pywin32,下载后安装 ...