tf多线程读取数据
队列
tf与python一样,有多种队列
tf.FIFOQueue 先入先出
tf.RandomShuffleQueue 随机出队
tf.PaddingFIFOQueue 以固定长度批量出列的队列
tf.PriorityQueue 带优先级出列的队列
使用逻辑都类似
tf.FIFOQueue(capacity, dtypes, shapes=None, names=None ...)
简单例子 (需要理解python的队列使用)
import tensorflow as tf tf.InteractiveSession() q = tf.FIFOQueue(2, "float") # 最多2个元素
init = q.enqueue_many(([0,0],)) # 初始化队列 x = q.dequeue() # get
y = x+1
q_inc = q.enqueue([y]) # put init.run() ## 初始化队列[0, 0]
# print(x.eval()) # 0.0
# print(x.eval()) # 0.0 q_inc.run() ## get 0 +1 put 1, 队列变成 [0, 1]
q_inc.run() ## get 0 +1 put 1,队列变成 [1, 1]
q_inc.run() ## get 1 +1 put 2,队列变成 [1, 2]
print(x.eval()) ## get 1
print(x.eval()) # get 2.0
x.eval() # 阻塞
enqueue_many 生成队列,enqueue put元素,dequeue get元素
tf多线程
tf提供了两个类来实现多线程协同的功能。分别是 tf.Coordinator() and tf.QueueRunner()。
tf.Coordinator()
tf.Coordinator()主要用于协同多个线程一起停止,包括 should_stop、 request_stop、 join 三个接口。
实现机制:
在启动线程前,先创建Coordinator类的实例对象coord,并将coord传给每一个线程,每个线程要不断检测这个实例的 should_stop 方法,如果返回True,就停止,
并且可以启动这个实例的 request_stop 方法(任意线程都可随时启动这个方法),这个方法会通知其他线程,一起结束,而且一旦这个方法被调用,should_stop方法就会返回True,其他线程都会结束。
示例代码
__author__ = 'HP'
# coding utf-8
import tensorflow as tf
import numpy as np
import threading
import time # 线程中运行的程序,这个程序每隔1秒判断是否需要停止并打印自己的ID。
def MyLoop(coord, worker_id):
# 使用tf.Coordinator类提供的协同工具判断当前线程是否需要停止并打印自己的ID
while not coord.should_stop():
# 人为制造一个停止的条件
if np.random.rand() < 0.1:
print('Stoping from id: %d\n' % worker_id)
# 调用coord.request_stop()函数来通知其他线程停止
coord.request_stop()
else:
# 打印当前线程的ID
print('Working on id: %d\n' % worker_id)
# 暂停1秒
time.sleep(1) # 声明一个tf.train.Coordinator类来协同多个线程
coord = tf.train.Coordinator()
# 声明创建5个线程
threads = [threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5)]
# 启动所有的线程
for t in threads: t.start()
# 等待所有线程退出
coord.join(threads)
输出
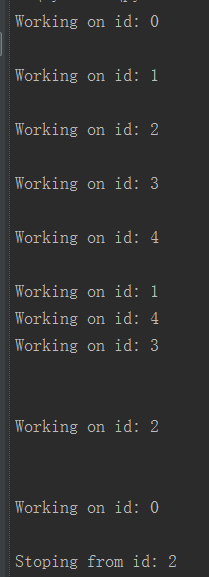
可以看到,一旦一个线程结束了,其他线程也跟着结束。
tf.QueueRunner()
tf.QueueRunner()用来同时启动多个线程操作同一个队列。并借助 tf.Coordinator()对线程进行管理。
示例代码
import tensorflow as tf # 声明一个先进先出的队列,队列中最多n个元素,类型
queue = tf .FIFOQueue(10, 'float')
# 定义队列的入队操作
enqueue_op = queue.enqueue([tf.random_normal([1])]) # 使用 tf.train.QueueRunner来创建多个线程运行队列的入队操作
# tf.train.QueueRunner给出了被操作的队列,[enqueue_op] * 5
# 表示了需要启动5个线程,每个线程中运行的是enqueue_op操作
qr = tf.train.QueueRunner(queue, [enqueue_op] * 5)
# 将定义过的QueueRunner加入TensorFlow计算图上指定的集合
# tf.train.add_queue_runner函数没有指定集合,
# 则加入默认集合tf.GraphKeys.QUEUE_RUNNERS。
# 下面的函数就是将刚刚定义的qr加入默认的tf.GraphKeys.QUEUE_RUNNERS结合
tf.train.add_queue_runner(qr)
# 定义出队操作
out_tensor = queue.dequeue() with tf.Session() as sess:
# 使用tf.train.Coordinator来协同启动的线程
coord = tf.train.Coordinator()
# 使用tf.train.QueueRunner时,需要明确调用tf.train.start_queue_runners
# 来启动所有线程。否则因为没有线程运行入队操作,当调用出队操作时,程序一直等待
# 入队操作被运行。tf.train.start_queue_runners函数会默认启动
# tf.GraphKeys.QUEUE_RUNNERS中所有QueueRunner.因为这个函数只支持启动指定集合中的QueueRunner,
# 所以一般来说tf.train.add_queue_runner函数和tf.train.start_queue_runners函数会指定同一个结合
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 获取队列中的取值
for _ in range(11): print(sess.run(out_tensor)[0]) # 使用tf.train.Coordinator来停止所有线程
coord.request_stop()
coord.join(threads)
同时启动多个线程,每个线程每次运行都将一个随机数写入队列,所以每次都能取到一个随机数。
用法小结
1. 创建多线程,方法是 tf.QueueRunner(aim_queue, [operation] * thread_num),目标队列,创建n个线程,执行某操作
2. 然后将多线程加入 tensorflow 节点,
3. 然后显示的调用 start_queue_runners 启动所有线程
参考资料:
http://www.cnblogs.com/demian/p/8005407.html
https://www.cnblogs.com/yinghuali/p/7506073.html#top
https://blog.csdn.net/qq_37423198/article/details/80524600
http://wiki.jikexueyuan.com/project/tensorflow-zh/how_tos/reading_data.html
https://blog.csdn.net/s_sunnyy/article/details/72924317
tf多线程读取数据的更多相关文章
- TensorFlow queue多线程读取数据
一.tensorflow读取机制图解 我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率. 解决 ...
- TF从文件中读取数据
从文件中读取数据 在TensorFlow中进行模型训练时,在官网给出的三种读取方式,中最好的文件读取方式就是将利用队列进行文件读取,而且步骤有两步: 把样本数据写入TFRecords二进制文件 从队列 ...
- 第十二节,TensorFlow读取数据的几种方法以及队列的使用
TensorFlow程序读取数据一共有3种方法: 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据. 从文件读取数据: 在TensorFlow图的起 ...
- Tensorflow中使用tfrecord方式读取数据-深度学习-周振洋
本博客默认读者对神经网络与Tensorflow有一定了解,对其中的一些术语不再做具体解释.并且本博客主要以图片数据为例进行介绍,如有错误,敬请斧正. 使用Tensorflow训练神经网络时,我们可以用 ...
- TensorFlow高效读取数据的方法——TFRecord的学习
关于TensorFlow读取数据,官网给出了三种方法: 供给数据(Feeding):在TensorFlow程序运行的每一步,让python代码来供给数据. 从文件读取数据:在TensorFlow图的起 ...
- TensorFlow读取数据的三种方法
tensortlfow数据读取有三种方式 placehold feed_dict:从内存中读取数据,占位符填充数据 queue队列:从硬盘读取数据 Dataset:同时支持内存和硬盘读取数据 plac ...
- tensorflow批量读取数据
Tensorflow 数据读取有三种方式: Preloaded data: 预加载数据,在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况). Feeding: Pyt ...
- Java多线程读取大文件
前言 今天是五一假期第一天,按理应该是快乐玩耍的日子,但是作为一个北漂到京师的开发人员,实在难想出去那玩耍.好玩的地方比较远,近处又感觉没意思.于是乎,闲着写篇文章,总结下昨天写的程序吧. 昨天下午朋 ...
- 云端TensorFlow读取数据IO的高效方式
低效的IO方式 最近通过观察PAI平台上TensoFlow用户的运行情况,发现大家在数据IO这方面还是有比较大的困惑,主要是因为很多同学没有很好的理解本地执行TensorFlow代码和分布式云端执行T ...
随机推荐
- Spring Boot之默认连接池配置策略
注意:如果我们使用spring-boot-starter-jdbc 或 spring-boot-starter-data-jpa “starters”坐标,Spring Boot将自动配置Hikari ...
- (GoRails)使用vue和Vuex管理嵌套的JavaScript评论, 使用组件vue-map-field
嵌套的JavaScript评论 Widget Models 创建类似https://disqus.com/ 的插件 交互插件: Real time comments: Adapts your site ...
- Vue.js示例:文本编辑器。使用_.debounce()反抖动函数
Markdown编辑器 https://cn.vuejs.org/v2/examples/index.html 新知识: Underscore.js库 用于弥补标准库,方便了JavaScript的编程 ...
- android------Eclipse Memory Analyzer (MAT)
简单介绍 MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具,是一个快速.功能丰富的JAVA heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗. 使用内 ...
- ubuntu vi配置
1.先卸载tiny版本vi 输入命令:sudo apt-get remove vim-common 2.然后再输入命令: sudo apt-get install vim sudo vim /et ...
- Django的form组件
forms组件 forms组件,是一个类.在视图函数中创建一个类,类需要继承forms.Form from django import forms 1.校验数据 步骤和语法: 1. 创建一个form ...
- Seagull License Server 9.4 SR3 2781 完美激活(解决不能打印问题)
BarTender 9.4 SR3完美激活方法 网上下载的BarTender 9.4大部分不能正常打印,已经测试过了,完美解决无法打印,界面停留在“无法打印,出现正在试图连接到seagull lice ...
- stl中的for_each() 函数的注意事项
#include<iostream> using namespace std; #include"vector" #include"algorithm&quo ...
- Linux在shell中输入历史命令
在Linux的shell中,经常输入的命令有很多雷同,甚至是一样的, 如果是长命令,再次敲一遍效率真的是很低, 不过可以通过Ctl+r, 查找history中以前输入的命令,很是好用. 按Ctrl+ ...
- MongoDB 教程(二):MongoDB 简介
概述: MongoDB 旨在为WEB应用提供可扩展.高性能的数据存储解决方案. MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成. MongoDB 文档类似于 ...