如何使用Hive&R从Hadoop集群中提取数据进行分析
一个简单的例子!
环境:CentOS6.5
Hadoop集群、Hive、R、RHive,具体安装及调试方法见博客内文档。
1、分析题目
--有一个用户数据样本(表名huserinfo)10万数据左右;
--其中有一个字段:身份证号(id_card)
--身份证号前两位代表:省,例如:11北京,12天津,13河北;
--身份证前x位对照表(表名hidcard_province)
--要求1:计算出每个省份出现的次数,并按从大到小排序取前30个;
--要求2:使用R画出柱状图。
2、编写Hive提取数据脚本:hive_getdata.sql
--创建临时表
DROP TABLE if exists tmp.t_province;
CREATE TABLE tmp.t_province(
id int,
p_name string,
cnt int
) COMMENT '用户数据中省份出现次数临时表' --将提取到的数据保存到临时表中
insert overwrite table tmp.t_province
select t1.cid, t2.province, t1.cnt from(
--取出前30条
select y.rownum, y.cid, y.cnt from(
--排序
select x.cid, x.cnt, row_number() over (distribute by x.cnt sort by x.cnt desc) as rownum from(
--分组
select a1.cid, count(1) as cnt from
--取数据
(select substring(id_card, 0, 2) as cid from bdm.huserinfo)a1
group by a1.cid
)x
)y where y.rownum <= 30
)t1
join bdm.hidcard_province t2 on t2.id = t1.cid
运行:
[root@Hadoop-NN-01 ~]$ hive -f hive_getdata.sql
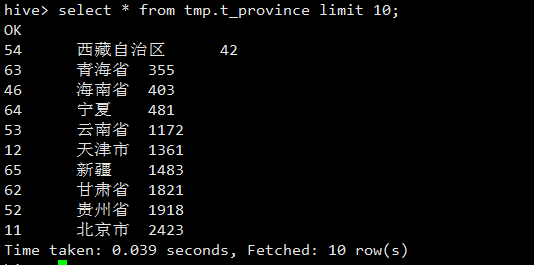
查看数据如下图:
hive> select * from tmp.t_province limit 10;
3、编写R语言绘图脚本:r_draw.r
#!/usr/bin/Rscript
library(RHive); #加载rhive包
rhive.connect(host ='192.168.100.20'); #rhive连接hive
x <- rhive.query('select id from tmp.t_province')
x <- x$id
y <- rhive.query('select cnt from tmp.t_province')
y <- y$cnt library(Cairo) #加载图形渲染库 png("r-province-pic.png", width=960, height=600) #生成图片
#说明:此里可以处理很多问题,可以使用很多算法解决很多的问题,具体算法我就不写了,只简单画个柱柱图,把代码跑通即可!
barplot(beside=TRUE,
y, #纵轴
names.arg=x, #横轴
ylim=c(0,10000) #纵轴取值范围 还有其它参数,可以根据自己需求设置。
) title(xlab="province name") #横轴名称
title(ylab="people number") #纵轴名称 #图例参数
lbls <- round(y/sum(y)*100)
lbls <- paste(lbls,"%",sep="")
lbls <- paste(x, lbls) #设置图例 其它参数根据自己需求设置
legend("topright", lbls) dev.off() #关闭绘图设备
rhive.close() #关闭hive连接
运行:
[root@Hadoop-NN-01 ~]$ Rscript r_draw.r
展示成果:
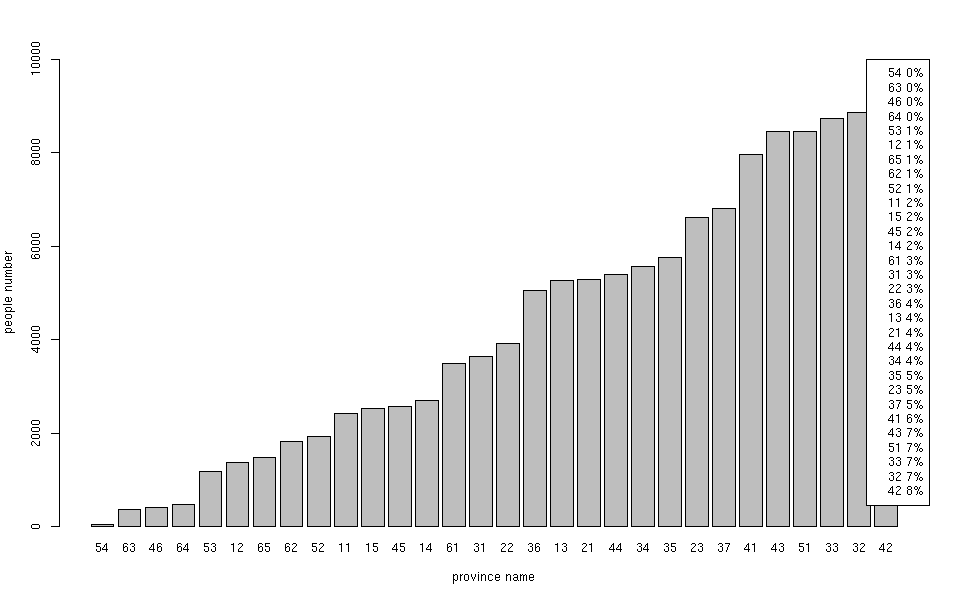
至此,一个简单的Hadoop-Hive-R实例完成!
PS:R下面中文乱码的问题仍在解决中!
如何使用Hive&R从Hadoop集群中提取数据进行分析的更多相关文章
- Hadoop集群中添加硬盘
Hadoop工作节点扩展硬盘空间 接到老板任务,Hadoop集群中硬盘空间不够用,要求加一台机器到Hadoop集群,并且每台机器在原有基础上加一块2T硬盘,老板给力啊,哈哈. 这些我把完成这项任务的步 ...
- 在Hadoop集群中添加机器和删除机器
本文转自:http://www.cnblogs.com/gpcuster/archive/2011/04/12/2013411.html 无论是在Hadoop集群中添加机器和删除机器,都无需停机,整个 ...
- hadoop集群中客户端修改、删除文件失败
这是因为hadoop集群在启动时自动进入安全模式 查看安全模式状态:hadoop fs –safemode get 进入安全模式状态:hadoop fs –safemode enter 退出安全模式状 ...
- hadoop集群中动态添加节点
集群的性能问题需要增加服务器节点以提高整体性能 https://www.cnblogs.com/fefjay/p/6048269.html hadoop集群之间hdfs文件复制 https://www ...
- hadoop集群中动态添加新的DataNode节点
集群中现有的计算能力不足,须要另外加入新的节点时,使用例如以下方法就能动态添加新的节点: 1.在新的节点上安装hadoop程序,一定要控制好版本号,能够从集群上其它机器cp一份改动也行 2.把name ...
- hadoop 集群中数据块的副本存放策略
HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性.可用性和网络带宽的利用率.目前实现的副本存放策略只是在这个方向上的第一步.实现这个策略的短期目标是验证它在生产环境下的有效 ...
- 集群中Session共享解决方案分析
一.为什么要Session共享 Session存储在服务器的内存中,比如Java中,Session存放在JVM的中,Session也可以持久化到file,MySQL,redis等,SessionID存 ...
- Hadoop集群中Hbase的介绍、安装、使用
导读 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. 一.Hbase ...
- hadoop集群中zkfc的作用和工作过程
一. 简单了解NameNode的ZKFC机制 NameNode的HA可以个人认为简单分为共享editLog机制和ZKFC对NameNode状态的控制 一般导致NameNode切换的原因 ZKFC的作用 ...
随机推荐
- parent对象
在应用有frameset或者iframe的页面时,parent是父窗口,top是最顶级父窗口(有的窗口中套了好几层frameset或者iframe),self是当前窗口, opener是用open方法 ...
- 洛谷P1098 字符串的展开【字符串】【模拟】
题目描述 在初赛普及组的“阅读程序写结果”的问题中,我们曾给出一个字符串展开的例子:如果在输入的字符串中,含有类似于“d-h”或者“4-8”的字串,我们就把它当作一种简写,输出时,用连续递增的字母或数 ...
- [No0000173]97 条 Linux 常用命令总结
1.ls [选项] [目录名 | 列出相关目录下的所有目录和文件 -a 列出包括.a开头的隐藏文件的所有文件-A 通-a,但不列出"."和".."-l 列 ...
- 2017年蓝桥杯省赛A组c++第5题(递归算法填空)
/* 由 A,B,C 这3个字母就可以组成许多串. 比如:"A","AB","ABC","ABA","AACB ...
- nslookup dig iptables,sudoer,jenkins
[NSLOOKUPm]http://roclinux.cn/?p=2441 nslookup media.ucampus.unipus.cn [DIG]http://roclinux.cn/?p=24 ...
- [math][mathematica] mathematica入门
快速入门手册: 只找到了个中文的快速入门: https://www.wolfram.com/language/fast-introduction-for-programmers/zh/?source= ...
- 最大似然估计(Maximum likelihood estimation)(通过例子理解)
似然与概率 https://blog.csdn.net/u014182497/article/details/82252456 在统计学中,似然函数(likelihood function,通常简写为 ...
- LeetCode 868 Binary Gap 解题报告
题目要求 Given a positive integer N, find and return the longest distance between two consecutive 1's in ...
- Java之旅_面向对象_包(Package)
http://www.runoob.com/java/java-package.html 包的作用: 1.把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用. 2.如同文件夹一样,包也采用 ...
- 根据xml配置使用反射动态生成对象
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="htt ...