oracle分区表原理学习
1.创建普通表
create table normal_shp(id number,day date,city_number number,note varchar2(100)) tablespace p;
插入10000条记录
insert into normal_shp(id,day,city_number,note) select rownum,to_date(to_char(sysdate-180,'J')+trunc(dbms_random.value(0,180)),'J'),ceil(dbms_random.value(1,7)),rpad('a',100,'a') from dual connect by rownum <=100000;
2.创建范围分区表
create table range_shp(id number,day date,city_number number,note varchar2(100))
partition by range(day)
(
partition p1 values less than (to_date('2019-02-01','YYYY-MM-DD')) tablespace p1,
partition p2 values less than (to_date('2019-03-01','YYYY-MM-DD')) tablespace p2,
partition p3 values less than (to_date('2019-04-01','YYYY-MM-DD')) tablespace p3,
partition p4 values less than (to_date('2019-05-01','YYYY-MM-DD')) tablespace p4,
partition p5 values less than (to_date('2019-06-01','YYYY-MM-DD')) tablespace p5,
partition p6 values less than (to_date('2019-07-01','YYYY-MM-DD')) tablespace p6,
partition p_max values less than (maxvalue) tablespace p
)
;
插入100000条记录
insert into range_shp(id,day,city_number,note)
select rownum,to_date(to_char(sysdate-180,'J')+trunc(dbms_random.value(0,180)),'J'),
ceil(dbms_random.value(1,7)),
rpad('a',100,'a')
from dual
connect by rownum <=100000;
3.性能对比
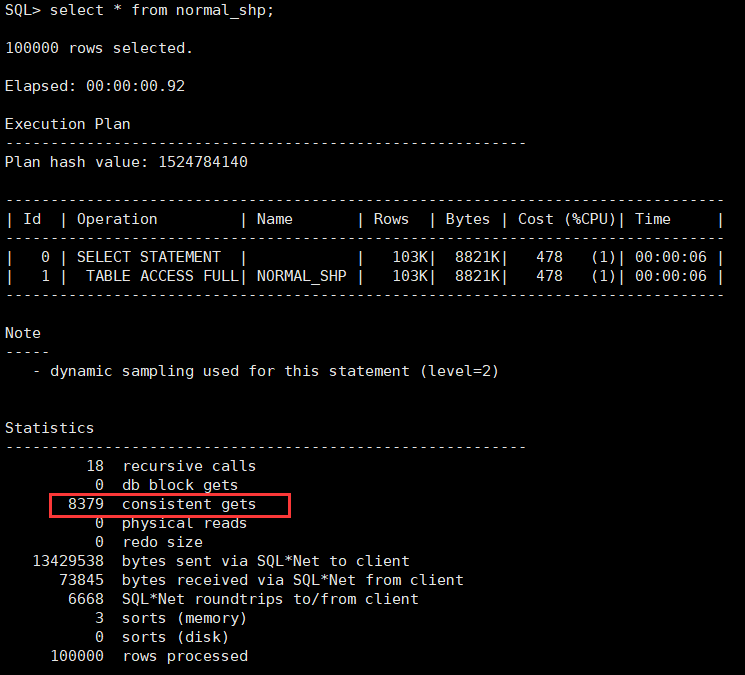
select * from normal_shp; --普通表
select * from range_shp; --范围分区表
|
普通表 |
范围分区表 |
 |
|
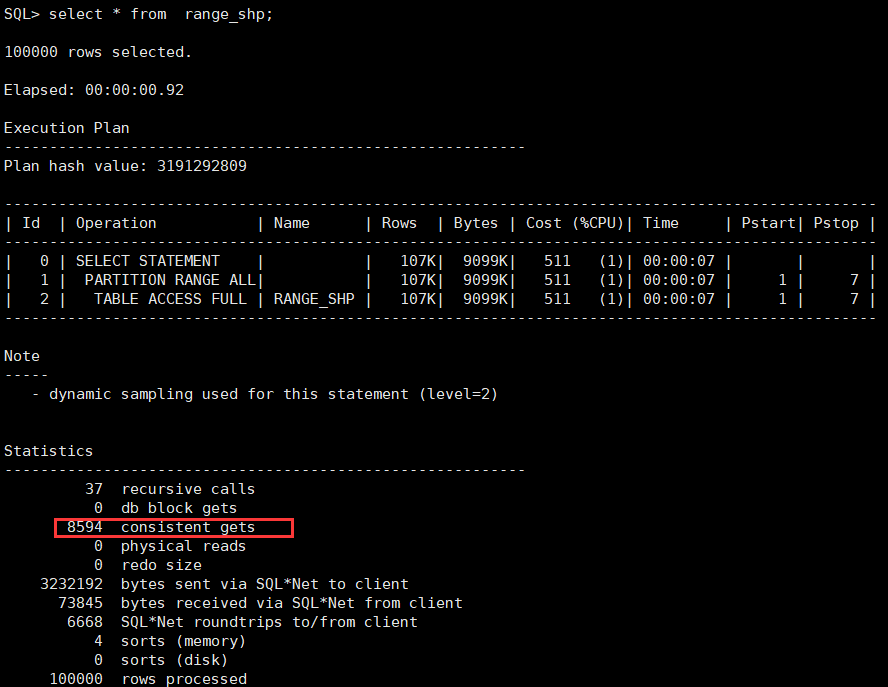
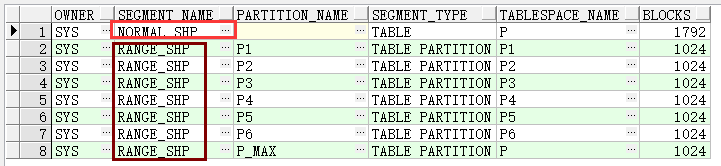
在不加任何条件时,进行查询发现,两者的逻辑读数量大致相同,花费大致相同;其中范围分区表的逻辑读和花费甚至略高于范围分区表。这是因为分区数量较多,oracle需要管理的段更多(见下图),在进行操作时会引发大量内部的递归调用(recursive calls),因而小表不建议建分区。
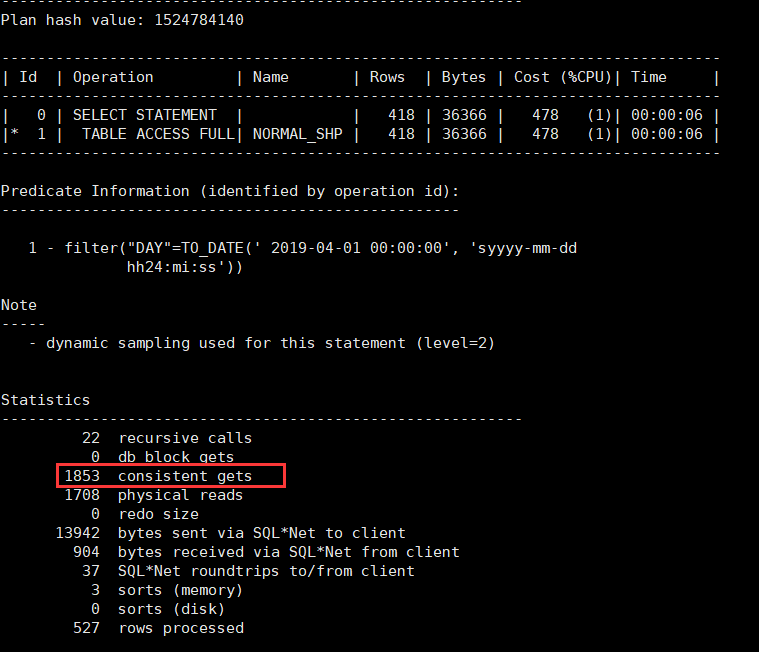
对指定时间进行查询:
select * from normal_shp where day=to_date(‘2019-04-01’,’YYYY-MM-DD’);
select * from range_shp where day=to_date(‘2019-04-01’,’YYYY-MM-DD’);
|
普通表 |
范围分区表 |
 |
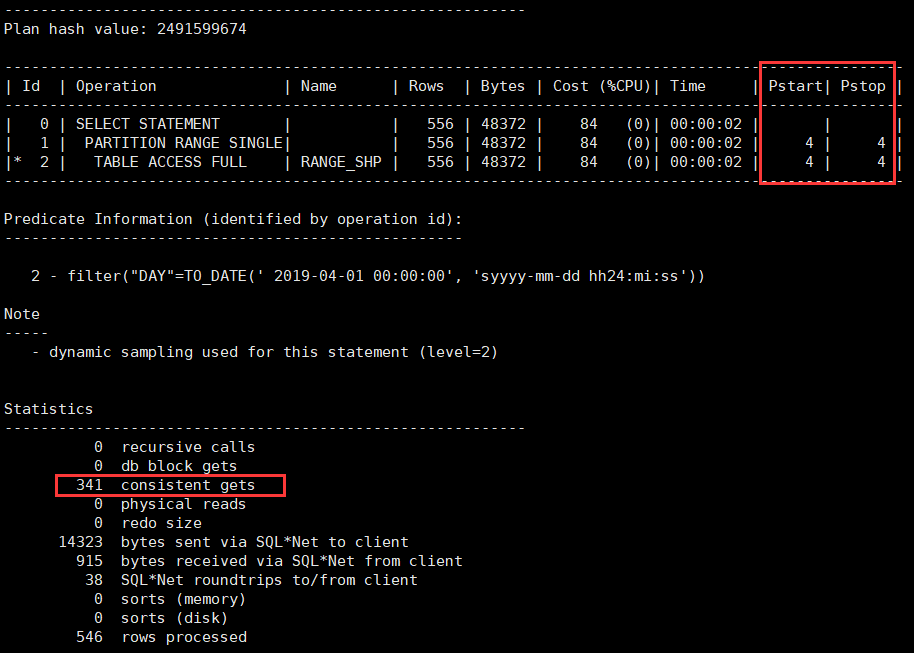 |
由上图可知,在对指定时间做查询时,对时间做范围分区表的查询更加高效,逻辑读从1853降到了341,花费也更加低。由执行计划仔细观察得,pstart和pstop均为4,代表范围分区表进行查询时,只对于第4个分区进行了全表扫描。
4.创建列表分区表
create table list_shp(id number,day date,city_number number,note varchar2(100))
partition by list(city_number)
(
partition p1 values (1) tablespace p1,
partition p2 values (2) tablespace p2,
partition p3 values (3) tablespace p3,
partition p4 values (4) tablespace p4,
partition p5 values (5) tablespace p5,
partition p6 values (6) tablespace p6,
partition p_other values (default) tablespace p
)
;
5.创建hash分区表
create table hash_shp(id number,day date,city_number number,note varchar2(100))
partition by hash(day)
partitions 6
store in (p1,p2,p3,p4,p5,p6)
;
注:如果表空间数量大于分区数量,则会采用前几个;如果表空间数量小于分区数量,表空间按序循环使用。散列分区的个数尽量使用偶数个。
或者:
-- Create table
create table SYS.HASH_SHP
(
id NUMBER,
day DATE,
city_number NUMBER,
note VARCHAR2(100)
)
partition by hash (DAY)
(
partition SYS_P41 tablespace P1,
partition SYS_P42 tablespace P2,
partition SYS_P43 tablespace P3,
partition SYS_P44 tablespace P4,
partition SYS_P45 tablespace P5,
partition SYS_P46 tablespace P6
);
6.创建组合分区表
常用的:范围-列表分区
create table range_list_shp(id number,day date,city_number number,note varchar2(100))
partition by range(day)
subpartition by list(city_number)
subpartition template
(
subpartition p1 values (1) tablespace p1,
subpartition p2 values (2) tablespace p2,
subpartition p3 values (3) tablespace p3,
subpartition p4 values (4) tablespace p4,
subpartition p5 values (5) tablespace p5,
subpartition p6 values (6) tablespace p6,
subpartition p_other values (default) tablespace p)
(
partition p1 values less than (to_date('2019-02-01','YYYY-MM-DD')) tablespace p1,
partition p2 values less than (to_date('2019-03-01','YYYY-MM-DD')) tablespace p2,
partition p3 values less than (to_date('2019-04-01','YYYY-MM-DD')) tablespace p3,
partition p4 values less than (to_date('2019-05-01','YYYY-MM-DD')) tablespace p4,
partition p5 values less than (to_date('2019-06-01','YYYY-MM-DD')) tablespace p5,
partition p6 values less than (to_date('2019-07-01','YYYY-MM-DD')) tablespace p6,
partition p_max values less than (maxvalue) tablespace p
)
;
7.分区数据交换
分区表的某个分区与普通表进行分区数据交换
alter table range_shp exchange partition p1 with table normal_shp1;
alter table range_list_shp subpartition p1_p1 with table normal_shp1;
(普通表的表结构要和分区一致)
8.分区表的管理
(1)清理分区
alter table range_shp truncate partition p1;
alter table range_list_shp truncate subpartition p1_p1;
(2) 增加表分区
当分区表存在默认条件分区,range中的maxvalue分区,list分区表中的default分区:
① 先删除原默认分区,增加分区后再添加默认分区
alter table range_shp drop partition p_max; --删除maxvalue分区
alter table range_shp add partition p_7 values less than (to_date('2019-08-01','YYYY-MM-DD')) tablespace p7; --增加分区
alter table range_shp add partition p_max values less than (maxvalue) tablespace p; --增加maxvalue分区
尤其注意,删除默认分区会将数据一并删除,不会分布到其他分区!!!
② 使用拆分分区split的方式进行增加
在目标分区拆分后,被拆分的分区会按照拆分规则将数据重新分布
alter table list_shp split partition p_other values(7) into (partition p_7 tablespace p7,partition p_other);
alter table range_shp split partition p_max at(to_date('2019-08-01','YYYY-MM-DD')) into (partition p_7 tablespace p6,partition p_other);
对于不存在默认条件分区的分区表,直接增加即可;
(3)合并表分区
对于列表分区,合并的分区无要求;
对于范围分区,合并的分区需相邻;
对于散列分区,无法合并
语法:alter table range_shp merge partitions p1,p2 into partition p0;
(4)收缩分区
只能在散列分区或者组合分区的hash子分区上进行使用
alter table hash_shp coalesce partition;
9.分区表索引的维护
全局索引:create index index1 on list_shp(day);
局部索引:create index index2 on range_shp(day) local;
N/A表示局部索引
截断一个分区会将全局索引失效,而局部索引不会失效
加参数可以避免全局索引失效:update global indexes;
Alter table range_shp truncate p1 update global indexes;
oracle分区表原理学习的更多相关文章
- 深入学习Oracle分区表及分区索引
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: • Range(范围)分区 • Has ...
- 【三思笔记】 全面学习Oracle分区表及分区索引
[三思笔记]全面学习Oracle分区表及分区索引 2008-04-15 关于分区表和分区索引(About PartitionedTables and Indexes) 对于 10gR2 而言,基本上可 ...
- oracle 分区表和分区索引
很复杂的样子,自己都没有看完,以备后用 http://hi.baidu.com/jsshm/item/cbfed8491d3863ee1e19bc3e ORACLE分区表.分区索引ORACLE对于分区 ...
- ORACLE分区表、分区索引详解
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt160 ORACLE分区表.分区索引ORACLE对于分区表方式其实就是将表分段 ...
- 谈一下如何设计Oracle 分区表
在谈设计Oracle分区表之间先区分一下分区表和表空间的个概念: 表空间:表空间是一个或多个数据文件的集合,所有数据对象都存放在指定的表空间中,但主要存放表,故称表空间. 分区表:分区致力于解决支持极 ...
- ORACLE工作原理小结
ORACLE工作原理1-连接 我们从一个用户请求开始讲,ORACLE的完整的工作机制是怎样的,首先一个用户进程发出一个连接请求,如果使用的是主机命名或者是本地服务命中的主机名使用的是机器名(非IP地址 ...
- IIS原理学习
IIS 原理学习 首先声明以下内容是我在网上搜索后整理的,在此只是进行记录,以备往后查阅只用. IIS 5.x介绍 IIS 5.x一个显著的特征就是Web Server和真正的ASP.NET Appl ...
- 谈一下怎样设计Oracle 分区表
在谈设计Oracle分区表之间先区分一下分区表和表空间的个概念: 表空间:表空间是一个或多个数据文件的集合,全部数据对象都存放在指定的表空间中,但主要存放表,故称表空间. 分区表:分区致力于解决支持极 ...
- Oracle教程之学习笔记
Oracle教程之学习笔记... ----------------------------------- Oracle教程:---学习笔记: ============================= ...
随机推荐
- 带发送FIFO缓冲的RX232串口发送以及把众多文件变成“黑匣子”用于其它工程的调用
如果需要发送端不断地接收新的数据,而发送端的数据传输率低就需要一个缓冲器FIFO来缓冲数据.当你为别人做项目只是想实现功能而不想让自己的代码让别人看到,想保护自己的算法时,你可以用以下的方法.我使用的 ...
- slf4j、jcl、jul、log4j1、log4j2、logback大总结[转]
#1 系列目录 jdk-logging.log4j.logback日志介绍及原理 commons-logging与jdk-logging.log4j1.log4j2.logback的集成原理 slf4 ...
- GoEasy实现websocket 推送消息通知到客户端
最近在实现一个推送功能,用户扫描二维码签到,后台及时将签到成功信息推送到浏览器端.排除了前端ajax轮询的方式,决定采用websocket及时推送. 于是发现了第三方websocket推送库GoEas ...
- windows游戏编程X86 (内存)寄存器相关的基本概念
本系列文章由jadeshu编写,转载请注明出处.http://blog.csdn.net/jadeshu/article/details/22446971 作者:jadeshu 邮箱: jades ...
- Git基础命令学习
Git是项目代码管理软件 主要管理逻辑如下: 所有代码保存在远程,本地获取远程代码保存在本地仓库,并于本地工作目录修改代码 修改完成后,提交到本地暂存区,添加必要注释,再尝试提交到远程仓库 若发生冲突 ...
- MySQL inodb cluster部署
innodb cluster是基于组复制来实现的. 搭建一套MySQL的高可用集群innodb. 实验环境: IP 主机名 系统 软件 192.168.91.46 master RHEL7.4 mys ...
- csp-s模拟90
T1: 每格的不透明度相当与一个边权,转化为从起点到终点所有路径的最大值.实现最长路,最好用$dijk$. T2: 对于$N=100$,$M=8$,考虑状压$dp$.要用一种状态表示某一行的矩形覆盖情 ...
- Sublime 添加∕删除右键菜单.bat
Sublime 添加∕删除右键菜单.bat @ECHO OFF & PUSHD %~DP0 & TITLE >NUL 2>&1 REG.exe query &quo ...
- Ubuntu 18.04系统下arm-linux-gcc交叉编译器安装
Ubuntu 18.04系统: arm-linux-gcc 4.4.3版本. 安装arm-linux-gcc将压缩包arm-linux-gcc.tar.gz解压到arm-linux-gcc文件夹tar ...
- 50行代码写的一个插件,破解一个H5小游戏
小游戏链接:测测你的眼睛对色差的辨识度http://www.webhek.com/post/color-test.html?from=timeline 废话不多说,先放代码: window.onloa ...