hadoop 集群的配置
在经过几天折腾,终于将hadoop环境搭建成功,整个过程中遇到各种坑,反复了很多遍,光虚拟机就重新安装了4、5次,接下来就把搭建的过程详细叙述一下
0.相关工具:
1,系统环境说明:
我这边给出我的集群环境是由一台主节点master和2台从节点slave组成:
master 192.168.137.122
slave1 192.168.137.123
slave2 192.168.137.124
3个节点上均是CentOS7.0系统
2,虚拟机设置
这里用的是 VMware12.1,虚拟CentOS7环境,虚拟机环境配置如下:
系统配置: 虚拟机:一个master,slave1, slave2
网络设置:共享主机IP
内存:每个虚拟机配置1024M内存
分区:自动
软件选择:基础设施服务器
用户设置:密码都设置为:hadoophadoop, 不创建任何用户,操作时使用root直接进行
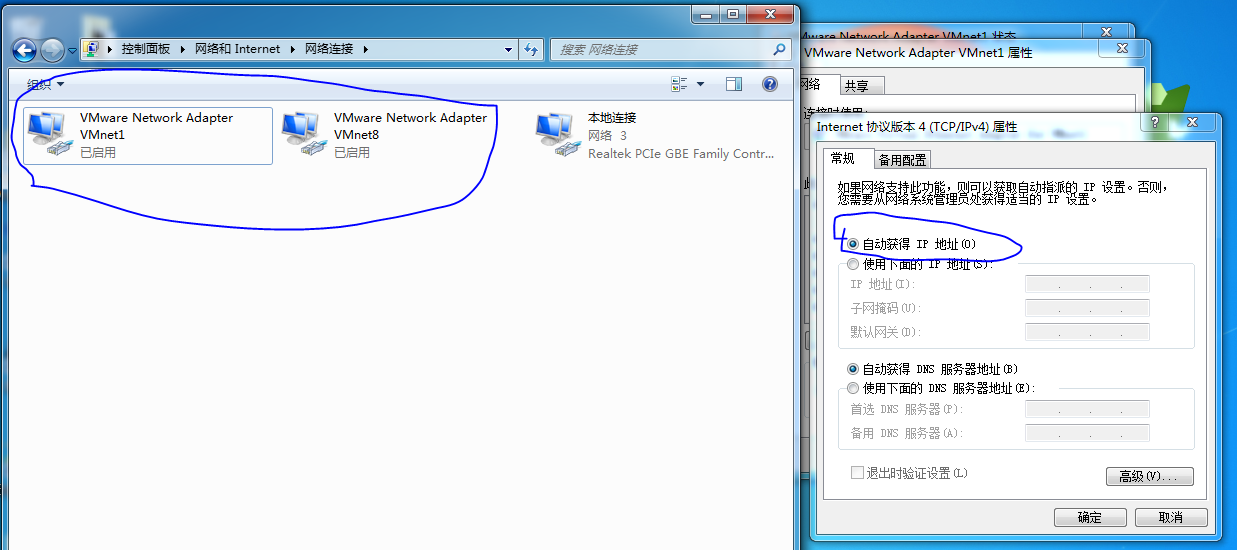
完成VMware安装后先设置,先在物理机中设置VMnet1、VMnet8 为自动获取IP 如下图所示:
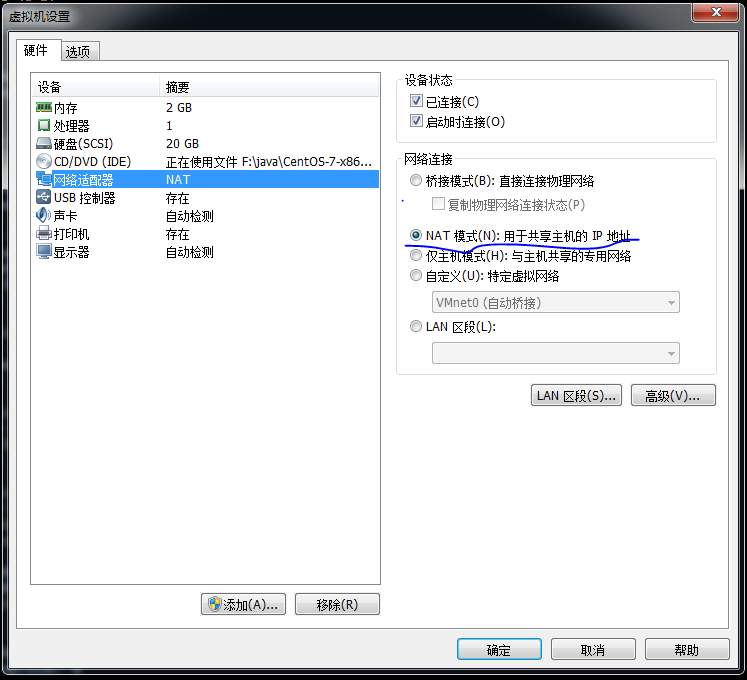
并将3台虚拟机网络连接方式都设置为:NAT模式,否则虚拟无法上网
3,环境安装
插入CentOS7系统盘,选择第一项进入系统安装,稍后会弹出设置界面:
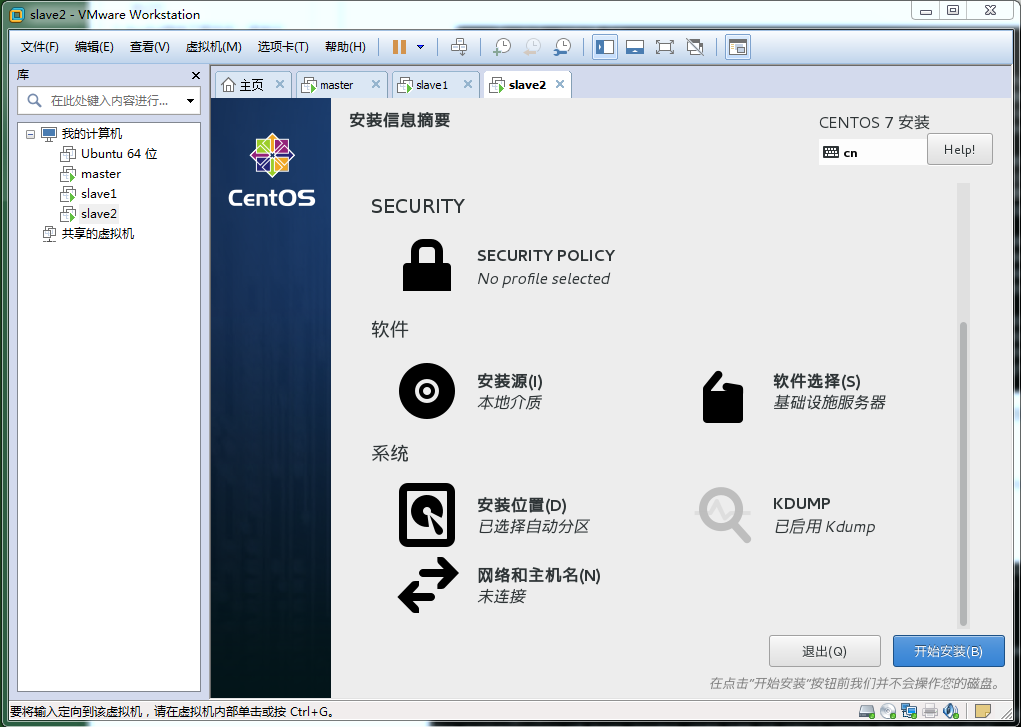
这里我们把环境设置为:基础设施服务器,否则会各种 "command not found..."他提供了,hadoop服务的基础环境
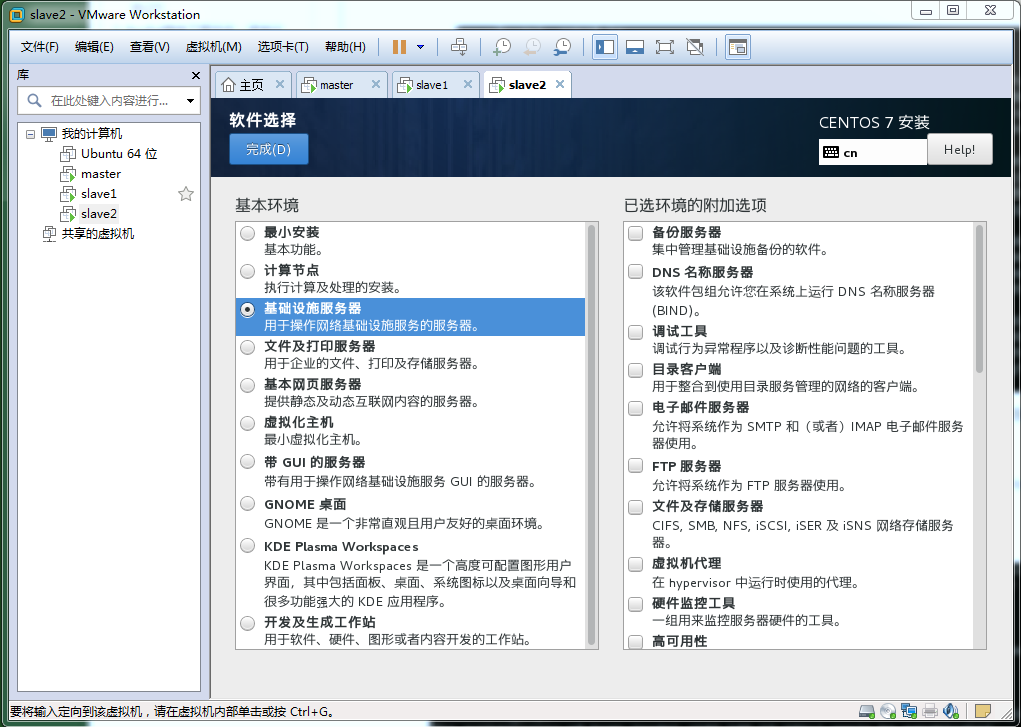
下面是选择"安装位置",这里我直接默认了,接下来很重要,设置网路和主机名,折腾好了,就不用安装完系统后在使用命令设置了
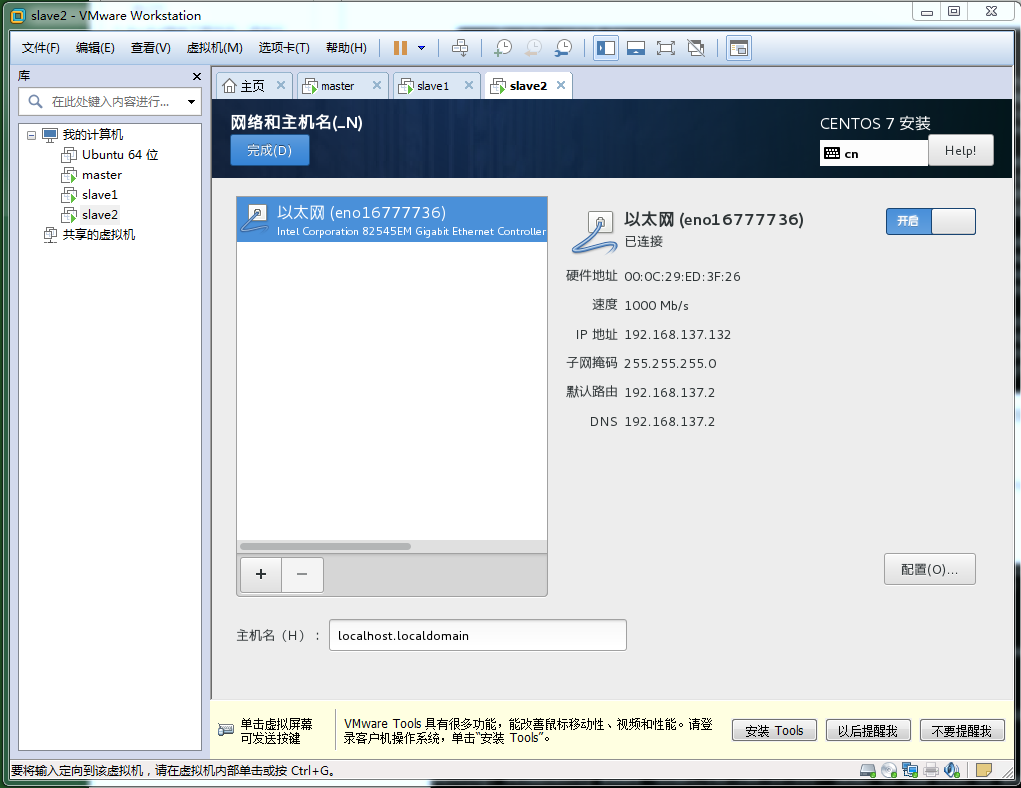
主机名的位置,添写"master",点击右侧"配置",在出现的网络设置中选择"IPv4设置",在出现的"方法"中选择手动,点击添加,设置"master"对应的IP,出现如下界面:
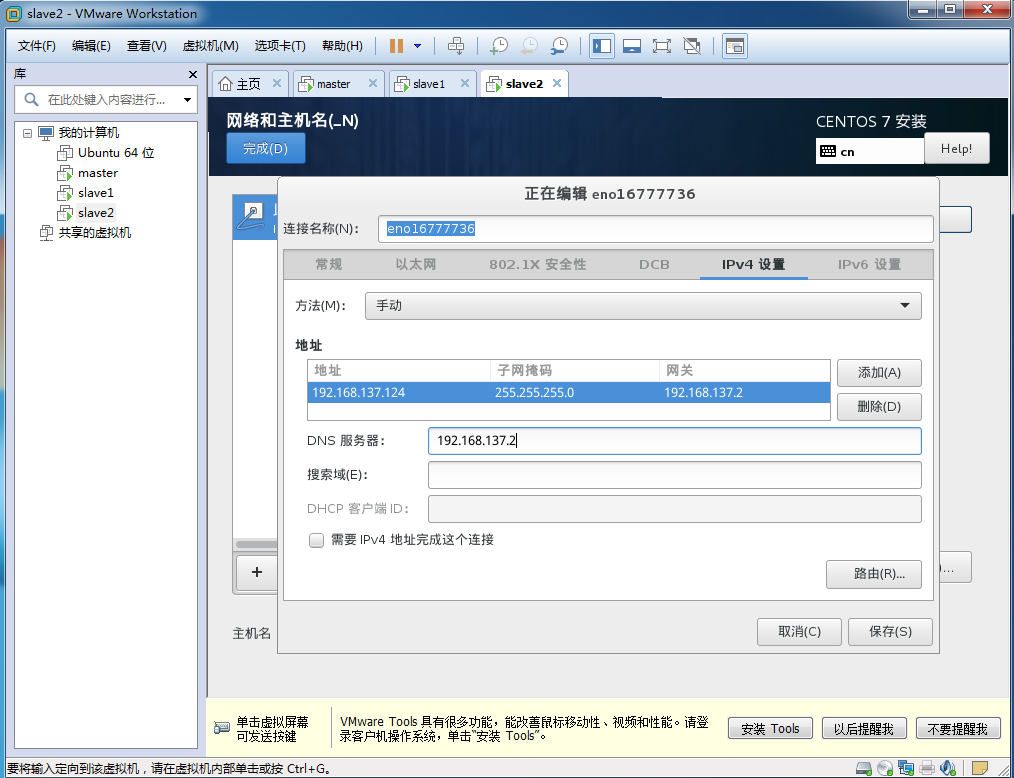
其余两台slave,设置一致,如果虚拟直接拷贝的,可以使用下列命令方法设置
1)修改主机名(分别在3台虚拟机修改为:master、slave1、slave2):
vi /etc/hostname
进入编辑状态后按"Insert"直接修改主机名,完成后,按"ESC",然后按住Shift 按两次Z保存退出
2)修改IP地址(分别在3台虚拟机修改为:192.168.137.122,192.168.137.123,192.168.137.124):
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736(虚拟机的网卡一般默认都是ifcfg-eno16777736)
增加以下内容:
BOOTPROTO=static #设置为静态IP
ONBOOT=yes #打开网卡
IPADDR=192.168.137.122 #设置IP,对应上面给出的四个IP地址,这里是master的IP
NETMASK=255.255.255.0 #设置子网掩码
GATEWAY=192.138.137.2 #设置网关
系统安装完成后需要设置root账号密码,这里我没有添加新用户,所以后续设置均通过root账号完成。
4,配置host
通过下列命令打开hosts文件,修改hosts配置,3台机器都需要
vi /etc/hosts
加入下列代码
192.168.137.122 master
192.168.137.123 slave1
192.168.137.124 slave2
在完成以上步骤后reboot重启3台虚拟机:reboot
5,SSH无密码验证配置
每台机器可以生成自己的一对公司钥,私钥自己保存。将本机作为服务器,要通过无密钥SSH访问本机的机器作为客户端,首先将服务器的公钥放到客户端,客户端将此公钥放到authorized_keys中,可以将authorized_keys认为是公钥的字典文件,因为可以放多个服务器的公钥进去,即可实现无密钥SSH访问。
Hadoop运行过程中,需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
在各节点上生成各自SSH秘钥对(这里秘钥类型为rsa,也可以设置为安全性更高的dsa),以master为例。
创建秘钥文件使用下列命令
ssh-keygen -t rsa
截图说明如下:
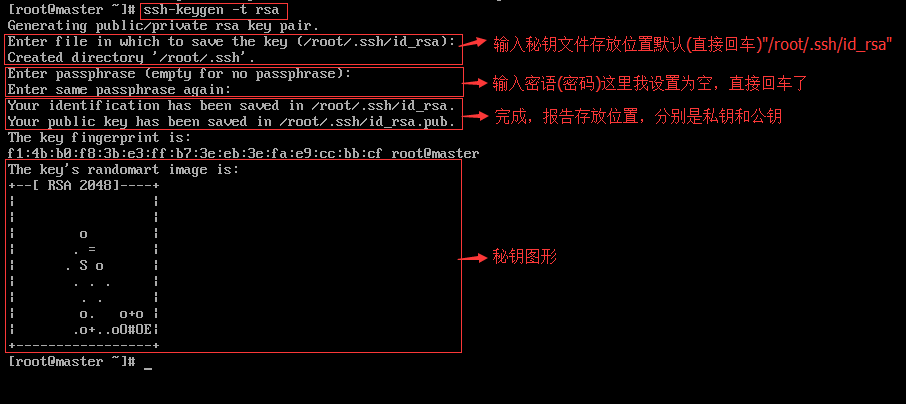
(参数说明参考:http://killer-jok.iteye.com/blog/1853451)
在本机上生成authorized_keys,并验证能否对本机进行SSH无密码登陆

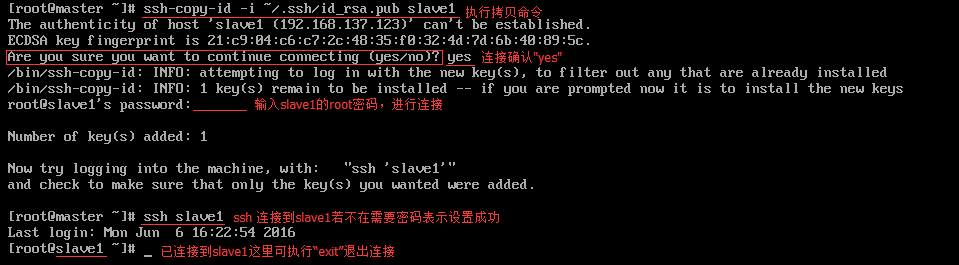
在其余所有节点都生成自己的authorized_keys之后,通过ssh-copy-id命令拷贝各自的公钥到其他节点,公钥会加入到对方机器的authorized_keys文件中,可以将authorized_keys认为是公钥的字典文件,因为可以放多个服务器的公钥进去,即可实现无密钥SSH访问。下面以slave1节点为例,将master节点的公钥复制到slave1节点中并加入到授权的key中,并验证是否配置成功。
在slave1中生成秘钥文件
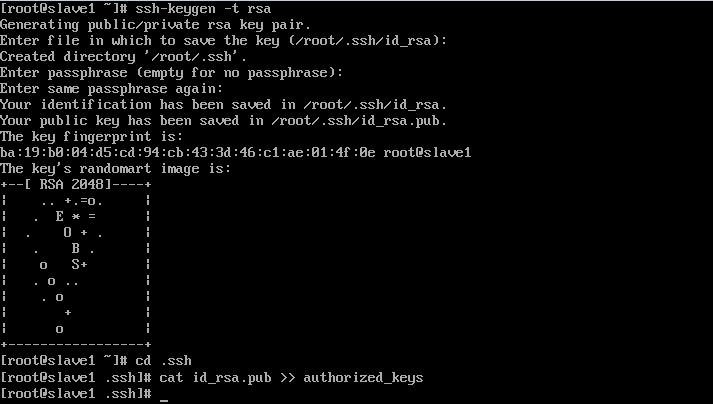
将master节点的公钥复制到slave1节点中并测试连接
在slave中使用 more 查看完成公钥复制后的文件

6,安装jdk环境设置
WinSCP是一个很好用的工具可以在windows物理机与虚拟之间传递文件
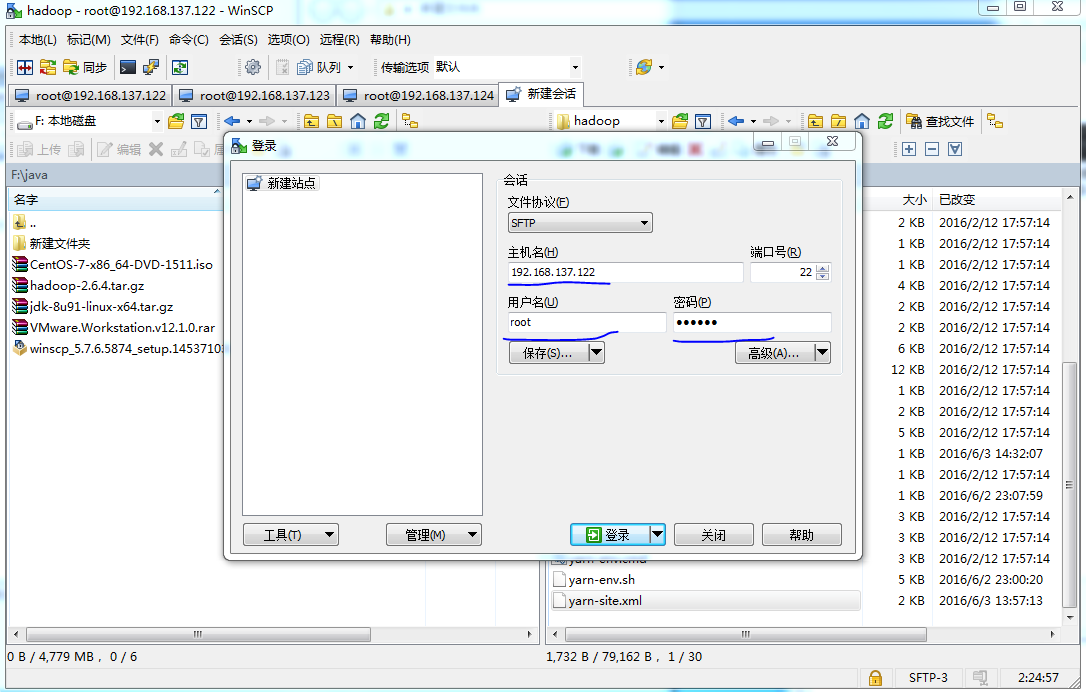
输入连接虚拟机机的IP,用户名,密码,链接成功后,上传jdk与hadoop到"/usr/local"目录下(这里目录可随意指定,稍后会登陆到虚拟机解压安装)
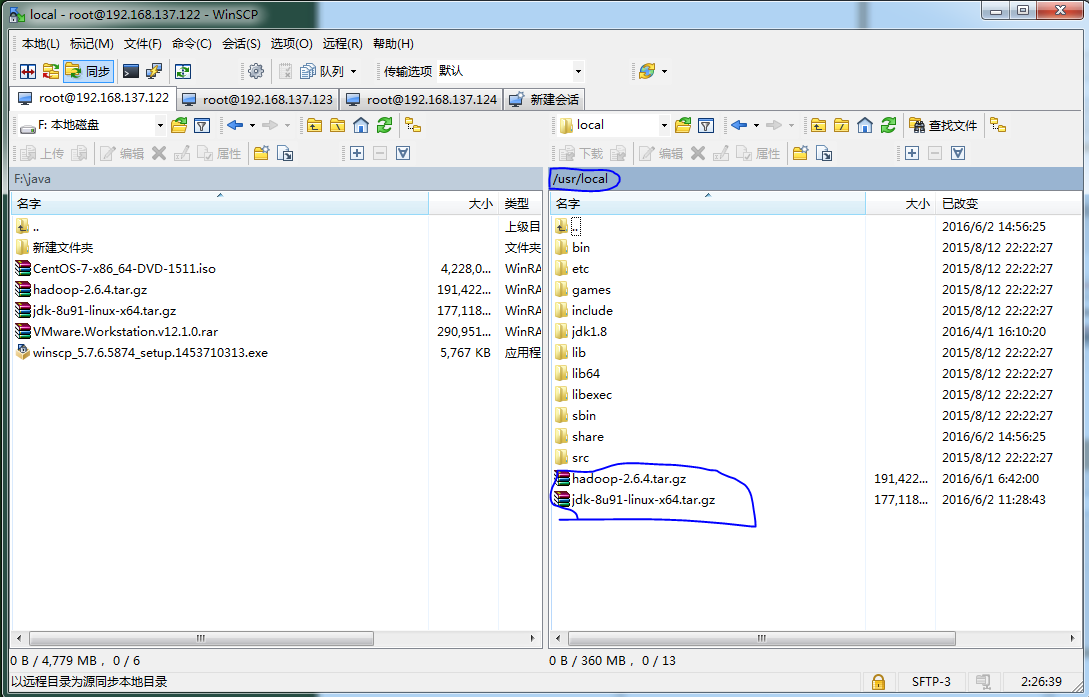
使用 tar -zvxf jdk-8u91-lunux-x64.tar.gz 解压

通过mv修改文件夹名称

配置jdk环境变量
vi /etc/profile
在尾部,加入下面内容:
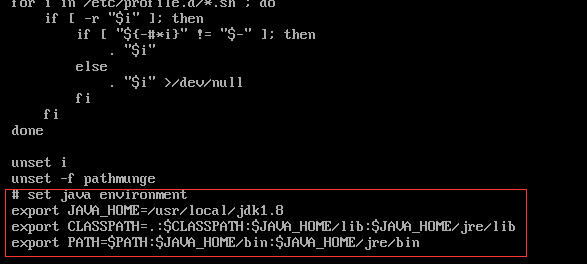
(当然这里也可以使用WinSCP在windows 中修改。)
保存退出后,执行下列命令 让更改及时生效
source /etc/profile
然后,执行下列命令验证安装成功
java -version

如果显示的版本与我们安装的版本一致,即安装成功
7,安装hadoop环境设置
使用 tar -zvxf hadoop-2.7.2.tar.gz 解压

移动到安装目录,我这里是"home/hadoop",可自定义

配置hadoop环境变量,还是修改刚刚配置jdk环境变量的文件
vi /etc/profile
在尾部,加入下面内容:
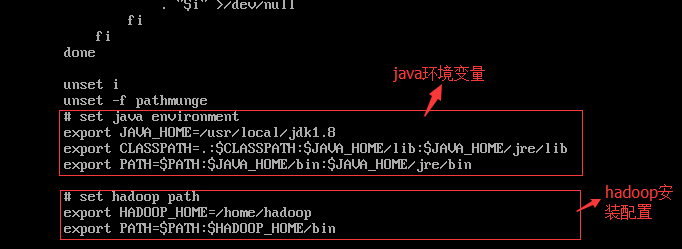
保存退出后,执行下列命令 让更改及时生效
source /etc/profile
然后,执行下列命令验证安装成功
hadoop version
正常会显示版本信息

配置 ~/hadoop/etc/hadoop下的hadoop-env.sh、yarn-env.sh、mapred-env.sh
使用命令:
vi /home/hadoop/etc/hadoop/hadoop-env.sh
修改JAVA_HOME

使用命令:
vi /home/hadoop/etc/hadoop/yarn-env.sh
修改JAVA_HOME
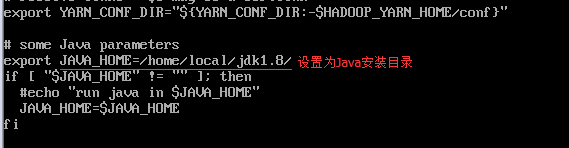
使用命令:
vi /home/hadoop/etc/hadoop/mapred-env.sh
修改JAVA_HOME
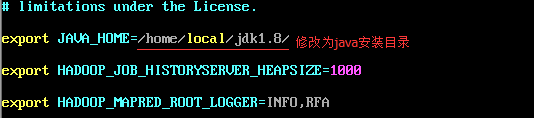
配置系统目录:Hadoop程序存放目录为/home/hadoop/,可以将程序和数据目录分开,可以更加方便的进行配置的同步,具体目录的配置如下所示:
l 在每个节点上创建程序存储目录/home/hadoop/,用来存放Hadoop程序文件。
l 在每个节点上创建数据存储目录/home/hadoop/hdfs,用来存放集群数据。
l 在主节点node上创建目录/home/hadoop/hdfs/name,用来存放文件系统元数据。
l 在每个从节点上创建目录/home/hadoop/hdfs/data,用来存放真正的数据。
l 所有节点上的日志目录为/home/hadoop/logs。
l 所有节点上的临时目录为/home/hadoop/tmp。
执行命令mkdir -p /home/hadoop/logs,为还没有的目录创建,后面以此类推
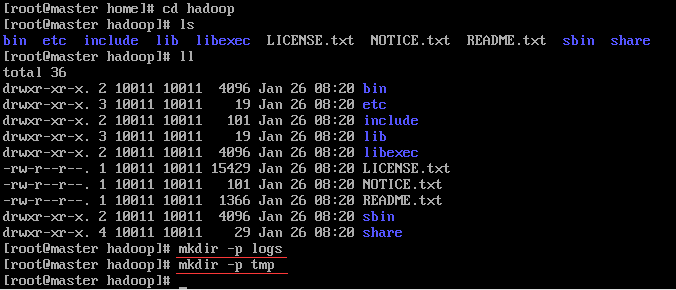
8, 修改hadoop配置文件
Hadoop2.7.2配置文件在hadoop/etc/hadoop目录下,配置文件也被分成了4个主要的配置文件需要配置其中包含:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
<description> 设定 namenode 的 主机名 及 端口 </description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description> 设置缓存大小 </description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description> 存放临时文件的目录 </description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
<description> namenode 用来持续存放命名空间和交换日志的本地文件系统路径 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
<description> DataNode 在本地存放块文件的目录列表,用逗号分隔 </description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description> 设定 HDFS 存储文件的副本个数,默认为3 </description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
9,设置hadoop集群
master上配置好的hadoop所在文件夹"/home/hadoop"复制到所有的Slave的"/home"目录下,而不必每台机器都要安装设置,用下面命令格式进行。
例如:从"master"到"slave1"复制配置Hadoop的文件:
scp –r /home/hadoop root@slave1:/home/
复制完成后在master上配置节点信息(其余节点不需要),使用下列命令
vi /home/hadoop/etc/hadoop/slaves
去掉"localhost",每行只添加一个主机名或者IP地址
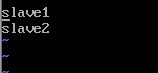
10,格式化HDFS文件系统
输入命令:
cd /home/hadoop
hadoop namenode -format
如果不出错大致会显示如下信息:
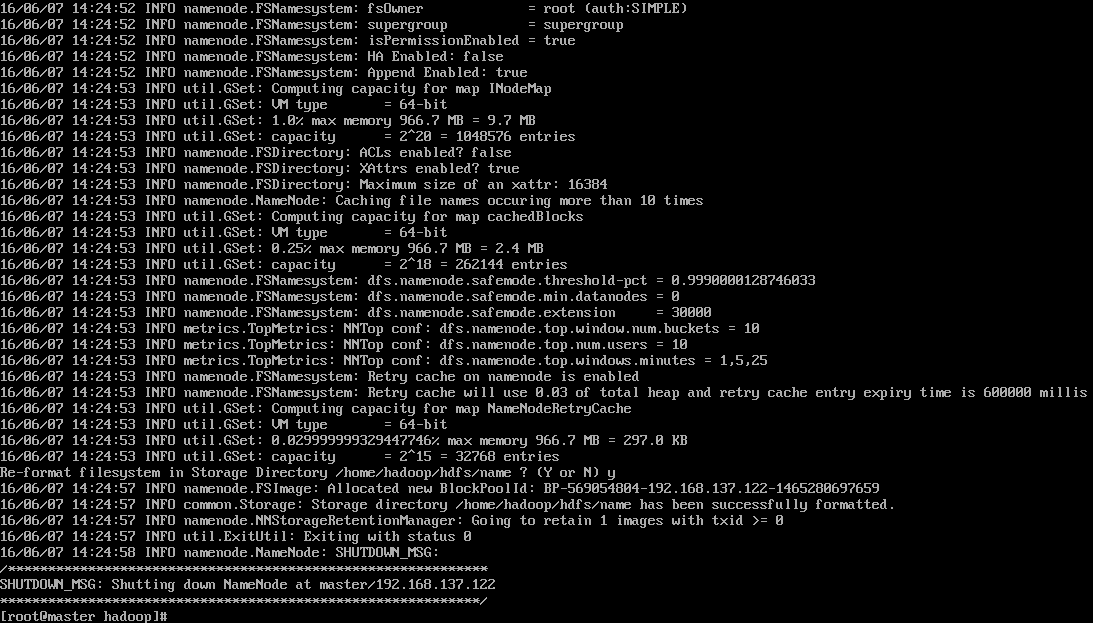
次数如产生错误,基本都是配置文件的问题,诸如不识别中文,配置文件中指定的路径不存在,等等,请认真检查配置文件
11,启动hadoop服务
cd /home/hadoop
sbin/start-all.sh
如无异常显示如下内容
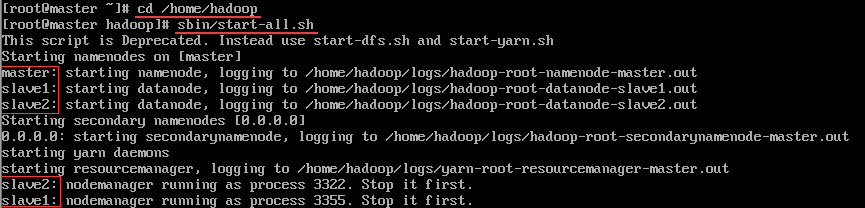
命令“sbin/stop-all.sh”停止hadoop服务
12,服务验证
- java自带的小工具jps查看进程
在master应该输出以下信息(端口号仅供参考)
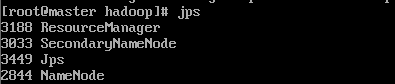
在slave应该输出以下信息(端口号仅供参考)

若不显示DataNode进程,表示DataNode节点启动失败,这里可以在slave节点中查看日子中的错误
more /home/hadoop/logs/hadoop-root-datanode-slave2.log

根据日志得知 datanode的clusterID 和 namenode的clusterID 不匹配将slave节点中/home/hadoop/hdfs/data/current/VERSION文件中的clusterID 修改为与master中的一致重新启动服务即可。
- 通过网页查看
先使用下面命令关闭防火墙
systemctl stop firewalld
输入以下网页, http://192.168.137.122:50070/dfshealth.html#tab-overview 进入hadoop管理首页
PS:参考文献
http://www.cnblogs.com/baiboy/p/4639474.html
http://www.tuicool.com/articles/mQfInyZ
http://www.centoscn.com/image-text/install/2014/1121/4158.html
http://blog.csdn.net/circyo/article/details/46724335
http://www.cbdio.com/BigData/2016-08/04/content_5156440.htm
http://blog.csdn.net/xw13106209/article/details/6855294
hadoop 集群的配置的更多相关文章
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- 【Big Data】HADOOP集群的配置(二)
Hadoop集群的配置(二) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop的学习前奏(二)——Hadoop集群的配置
前言: Hadoop集群的配置即全然分布式Hadoop配置. 笔者的环境: Linux: CentOS 6.6(Final) x64 JDK: java version "1.7 ...
- Hadoop集群的配置(一)
摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题.但是网上一些文档大多互相抄 ...
- hadoop集群默认配置和常用配置【转】
转自http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xm ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群默认配置和常用配置
http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xml, ...
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
http://blog.csdn.net/whaoxysh/article/details/17755555 虚拟机安装 我安装的虚拟机版本是VMware Workstation 8.04,自己电脑上 ...
- hadoop集群单点配置
=================== =============================== ----------------hadoop集群搭建 --------------------- ...
随机推荐
- sql复习第五次
1.在数据库范围内,关系的每一个属性值是不可分解的 关系中不允许出现重复元组 由于关系是一个集合,因此不考虑元组的顺序 2.笛卡儿积是两个关系的所有元组组合而成的,而等值联接是由笛卡儿积和选择运算组合 ...
- Utility3:Understand Dashboard Report
To see data in the SQL Server Utility dashboard, select the top node in the Utility Explorer tree - ...
- WaitType:SOS_SCHEDULER_YIELD
今天遇到一个query,处于SOS_SCHEDULER_YIELD 状态,physical IO 不增加,CPU的使用一直在增长.当一个sql query长时间处于SOS_SCHEDULER_YIEL ...
- 外接程序“VMDebugger”未能加载或者导致了异常。是否希望移除该外接程序?
收工~
- SQL Server 复制:事务发布
一.背景 在复制的运用场景中,事务发布是使用最为广泛的,我遇到这样一个场景:在Task数据库中有Basic与Group两个表,需要提供这两个表的部分字段给其它程序读取放入缓存,程序需要比较及时的获取到 ...
- OpenCascade Eigenvalues and Eigenvectors of Square Matrix
OpenCascade Eigenvalues and Eigenvectors of Square Matrix eryar@163.com Abstract. OpenCascade use th ...
- 【转】Linux C动态内存泄漏追踪方法
原文:http://www.cnblogs.com/san-fu-su/p/5737984.html C里面没有垃圾回收机制,有时候你申请了动态内存却忘记释放,这就尴尬了(你的程序扮演了强盗角色,有借 ...
- Unity3D知识框架
美术部分: 3d模型,材质,纹理,shader,Animator,Animation,天空盒,灯光效果,烘焙 程序部分: 基本组成: ...
- git与svn, tfs等源代码管理器的协同
简单地说,这三个都是业界知名的源代码管理器.他们是有区别的,根本的区别在于git是分布式源代码管理器(每个本地都有完整的代码,及历史),而svn和tfs是集中式源代码管理器(只有服务器才有完整的历史, ...
- 用PHP抓取页面并分析
在做抓取前,记得把php.ini中的max_execution_time设置的大点,不然会报错的.