Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead
Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead

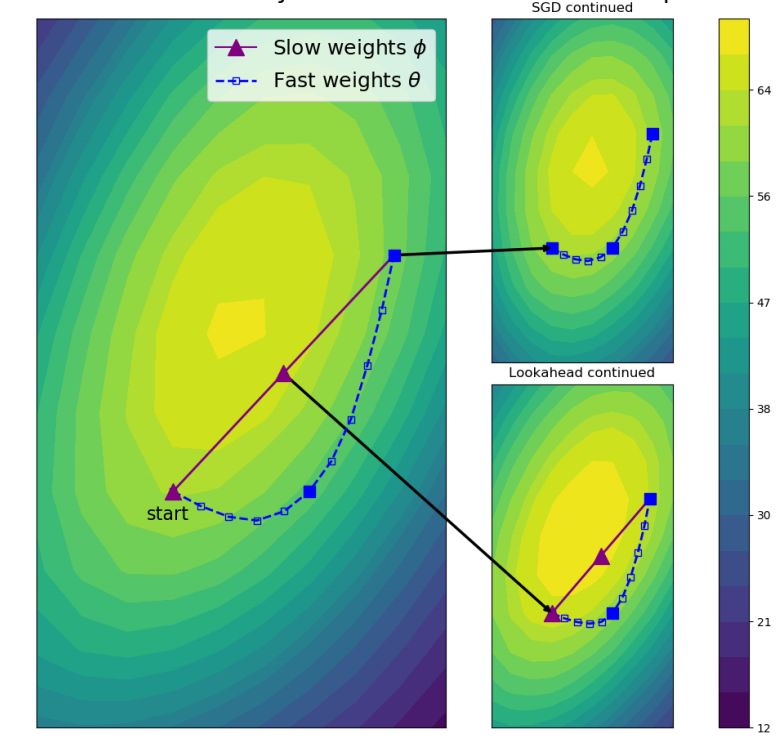


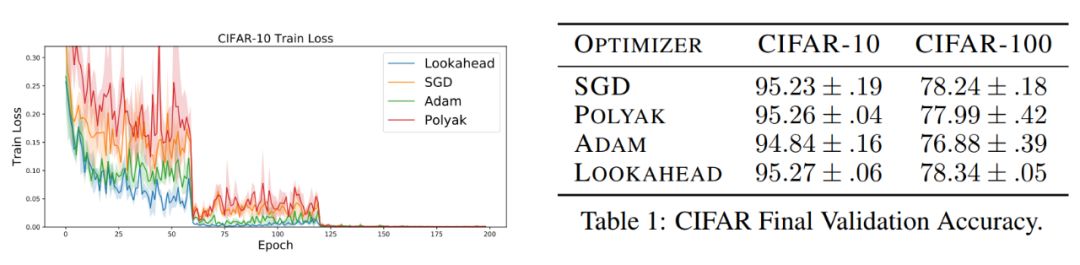


Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead的更多相关文章
- DevExpress ChartControl大数据加载时有哪些性能优化方法
DevExpress ChartControl加载大数据量数据时的性能优化方法有哪些? 关于图表优化,可从以下几个方面解决: 1.关闭不需要的可视化的元素(如LineMarkers, Labels等) ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
- Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用?
Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用? 2019年07月06日 19:30:55 AI科技大本营 阅读数 675 版权声明:本文为博主原创文章,遵循CC 4.0 B ...
- Hinton等人新研究:如何更好地测量神经网络表示相似性
Hinton等人新研究:如何更好地测量神经网络表示相似性 2019年05月22日 08:39:15 喜欢打酱油的老鸟 阅读数 177更多 分类专栏: 人工智能 https://www.toutia ...
- 光环国际联合阿里云推出“AI智客计划”
2018阿里巴巴云栖大会深圳峰会3月28日.29日在大中华喜来登酒店举行,阿里云全面展示智能城市.智能汽车.智能生活.智能制造等产业创新. 3月28日下午,以"深化产教融合,科技赋能育人才& ...
- 移动终于hold不住了 联合微信正式推出流量红包业务
微信的迅猛发展终于让中移动hold不住了,今日移动广东分公司联合微信正式推出流量红包业务,流量红包分为1元10M(10个整售).3元50M(5个整售)两种.广东的微信朋友有福了,赶紧去抢红包吧!微信& ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
随机推荐
- 一步一步实现一个Promise A+规范的 Promise
2015年6月,ES2015(即ES6)正式发布后受到了非常多的关注.其中很重要的一点是 Promise 被列为了正式规范. 在此之前很多库都对异步编程/回调地狱实现了类 Promise 的应对方案, ...
- C++入门经典-例7.9-对象数组,批量化生产
1:在数组内容中我们了解到,数组是通过指针分配到的一段额定大小的内容.同样,数组也可以包含对象.声明对象数组的形式如下: box boxArray[5]; box boxArray2[2]={box( ...
- LeetCode 199. 二叉树的右视图(Binary Tree Right Side View)
题目描述 给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值. 示例: 输入: [1,2,3,null,5,null,4] 输出: [1, 3, 4] 解释: 1 ...
- laravel where orwhere的写法
orWhere如果不用闭包的形式写很容易写成分开的查询条件 要写成一组查询条件需要这样闭包写(就相当于把这两个条件放在一个小括号里,是一组查询条件“(xxx or xxx)”): if (!empty ...
- Centos7 yum install chrome
一.配置 yun 源 vim /etc/yum.repos.d/google-chrome.repo [google-chrome] name=google-chrome baseurl=http:/ ...
- C# 防火墙操作之开启与关闭
通过代码操作防火墙的方式有两种:一是代码操作修改注册表启用或关闭防火墙:二是直接操作防火墙对象来启用或关闭防火墙.不论哪一种方式,都需要使用管理员权限,所以操作前需要判断程序是否具有管理员权限. 1. ...
- JS中在当前日期上追加一天或者获取上一个月和下一个月
/** * 获取上一个月 * * @date 格式为yyyy-mm-dd的日期,如:2014-01-25 */ function getPreMonth(date) { var arr = date. ...
- 使用EasyPrint实现不预览直接打印功能_非JS打印
插件地址 github 下载插件,安装后将在注册表中添加EasyPrint的协议 随后可以在开始->运行中输入EasyPrint://1&test 进行测试 参数分为两部分使用[&am ...
- 手动部署 Ceph Mimic 三节点
目录 文章目录 目录 前文列表 部署拓扑 存储设备拓扑 网络拓扑 基础系统环境 安装 ceph-deploy 半自动化部署工具 部署 MON 部署 Manager 部署 OSD 部署 MDS 部署 R ...
- linux性能监控 + Sendmail 发邮件
sendmail安装 #!/bin/bash#控制发邮件的阈值是在rate,rate1和FF值(三个同样的用途,仅仅是名字不同)##注:该博文中的变量不规范,我是随意定义的,请注意##定义时间倒计时函 ...