Python爬虫教程-06-爬虫实现百度翻译(requests)
使用python爬虫实现百度翻译(requests)
python爬虫
- 上一篇介绍了怎么使用浏览器的【开发者工具】获取请求的【地址、状态、参数】以及使用python爬虫实现百度翻译功能【urllib】版
- 上一篇链接:https://blog.csdn.net/qq_40147863/article/details/81590849
- 本篇介绍使用python爬虫实现百度翻译功能【requests】版
使用requests,必须先添加requests包
- 安装requests
- 如果使用Anaconda环境,使用下面命令:
conda install requests
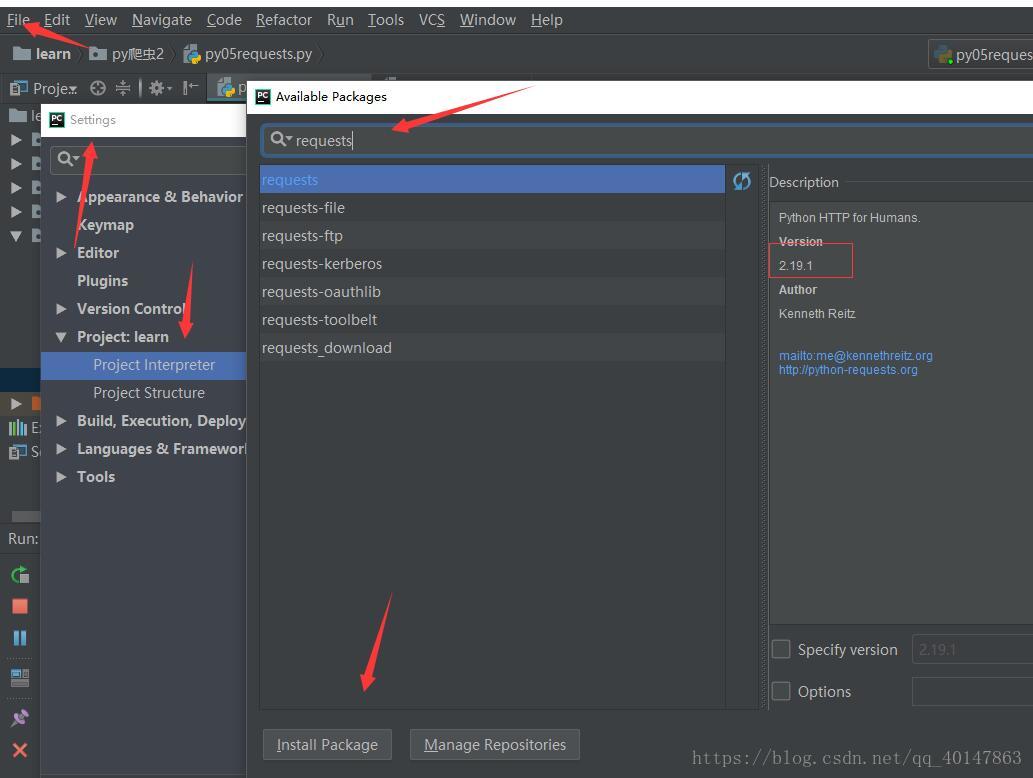
如果不是,就自己手动在【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】>【requests】>【install】
具体操作截图:
这里写图片描述
直接献上代码
- py05requests.py文件:https://xpwi.github.io/py/py爬虫/py05requests.py
# 百度翻译
# 添加包的方法在上面
import requests
import json
def fanyi(keyword):
url = 'http://fanyi.baidu.com/sug'
# 定义请求参数
data = {
'kw': keyword
}
# 发送请求,抓取信息
res = requests.post(url,data=data)
# 解析结果并输出
str_json = res.text
myjson = json.loads(str_json)
info = myjson['data'][0]['v']
print(info)
if __name__=='__main__':
while True:
keyword = input('请输入翻译的单词:')
if keyword == 'q':
break
fanyi(keyword)
运行结果
没错,requests版就是这么简洁,只不过需要加载requests包
使用python爬虫实现百度翻译功能(requests)版就介绍到这里了

更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-06-爬虫实现百度翻译(requests)的更多相关文章
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-05-python爬虫实现百度翻译
使用python爬虫实现百度翻译功能 python爬虫实现百度翻译: python解释器[模拟浏览器],发送[post请求],传入待[翻译的内容]作为参数,获取[百度翻译的结果] 通过开发者工具,获取 ...
- Python 基础教程 —— 网络爬虫入门篇
前言 Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言,它由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年.自面世以后,Pytho ...
- Python爬虫【实战篇】百度翻译
先看代码 import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
随机推荐
- shell (三) 文件压缩
查看压缩文件 #tar tvf tar.tar.gz -rw-r--r-- root/root 290 2019-03-22 14:38 README.md -rw-r--r-- root/root ...
- Python3 print()函数sep,end,file参数用法练习
来自builtins.py:def print(self, *args, sep=' ', end='\n', file=None): # known special case of print &q ...
- Spring Boot Starter列表
转自:http://blog.sina.com.cn/s/blog_798f713f0102wiy5.html Spring Boot Starter 基本的一共有43种,具体如下: 1)spring ...
- 什么是O/RMapping?为什么要用O/R Mapping?
什么是O/R Mapping ? O/R Mapping 就是有一大堆的类库,我们调用它的时候用面向对象的方式来调,它帮我们翻译成为面向关系的方式. 为什么要用O/R Mapping? 我们编程会更加 ...
- Java Servelet
1.服务器端运行的程序 2.Servelet三个方法 init service 抽象方法 destory 这三个方法构成了servelet的生命周期 3.步骤 1.在web.xml中 描述了servl ...
- mysql 递归查询 主要是对于层级关系的查询
最近遇到了一个问题,在mysql中如何完成节点下的所有节点或节点上的所有父节点的查询?在Oracle中我们知道有一个Hierarchical Queries可以通过CONNECT BY来查询,但是,在 ...
- SQL注入原理讲解
1.1.1 摘要 日前,国内最大的程序员社区CSDN网站的用户数据库被黑客公开发布,600万用户的登录名及密码被公开泄露,随后又有多家网站的用户密码被流传于网络,连日来引发众多网民对自己账号.密码等互 ...
- CentOS7下Rsync+sersync实现数据实时同步
近期公司要上线新项目,后台框架选型我选择当前较为流行的laravel,运行环境使用lnmp. 之前我这边项目tp32+apache,开发工具使用phpstorm. 新建/编辑文件通过phpstorm配 ...
- 每天一道leetcode141-环形链表
考试结束,班级平均分只拿到了年级第二,班主任于是问道:大家都知道世界第一高峰珠穆朗玛峰,有人知道世界第二高峰是什么吗?正当班主任要继续发话,只听到角落默默想起来一个声音:”乔戈里峰” 前言 2018. ...
- JAVA泛型——基本使用
Java1.5版本推出了泛型,虽然这层语法糖给开发人员带来了代码复用性方面的提升,但是这不过是编译器所做的一层语法糖,在真正生成的字节码中,这类信息却被擦除了.笔者发现很多几年开发经验的程序员,依然不 ...