IDEA 创建HDFS项目 JAVA api
1.创建quickMaven
1.在properties中写hadoop 的版本号并且通过EL表达式的方式映射到dependency中
2.写一个repostory将依赖加载到本地仓库中
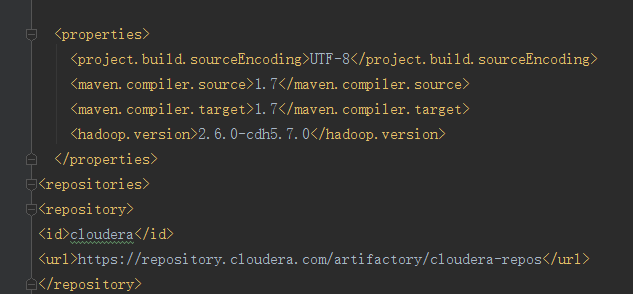
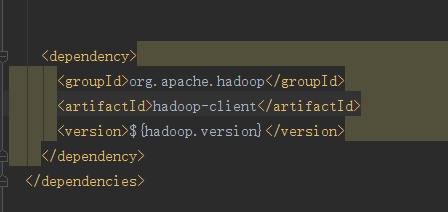
这是加载完成的页面

这是开发代码
package com.kevin.hadoop; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import org.junit.After;
import org.junit.Before;
import org.junit.Test; import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.net.URI; /**
* Created by Administrator on 2018/7/21 0021.
* Hadoop HDFS java API 操作
*/
public class HDFSApp {
public static final String HDFS_PATH = "hdfs://hadoop000:8020";
//文件系统
FileSystem fileSystem = null;
//配置类
Configuration configuration = null; //Before适用于类加载之前
@Test
/**
* 创建HDFS系统
*/
public void mkdir() throws Exception {
fileSystem.mkdirs(new Path("/hdfsapi/test"));
} @Test
public void create() throws Exception {
FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/a.txt"));
output.write("hello hadoop".getBytes());
output.flush();
output.close();
} @Test
/**
* 查看HDFS文件上的内容
*/
public void cat() throws Exception {
FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test/a.txt"));
IOUtils.copyBytes(in, System.out, 1024);
in.close();
} @Before
public void setUp() throws Exception {
System.out.printf("HDFSapp.setup");
configuration = new Configuration();
//拿到文件系统
fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "hadoop");
} //关闭资源用的这个
@After
public void tearDown() throws Exception {
//释放资源
configuration = null;
fileSystem = null;
System.out.printf("HDFSAPP.tearDown");
} /**
* 重命名文件
*/
@Test
public void rename() throws Exception {
Path oldPath = new Path("/hdfsapi/test/a.txt");
Path newPath = new Path("/hdfsapi/test/b.txt");
fileSystem.rename(oldPath, newPath);
} /**
* 上传一个文件
*
* @throws Exception
*/
@Test
public void copyFromLocalFile() throws Exception {
Path localPath = new Path(" //c//hello.txt");
Path hdfsPath = new Path("/hdfsapi/test");
fileSystem.copyFromLocalFile(localPath, hdfsPath);
} /**
* 上传一个大文件
*
* @throws Exception
*/
@Test
public void copyFromLocalBigFile() throws Exception {
InputStream in = new BufferedInputStream(
new FileInputStream(
new File("C:\\mmall-fe\\all.zip"))); FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/all.zip"),
new Progressable() {
public void progress() {
System.out.print("."); //带进度提醒信息
}
}); IOUtils.copyBytes(in, output, 4096);
}
/**
* 下载HDFS文件
*/
@Test
public void copyTOLocalFile() throws Exception{
Path localPath = new Path("C:\\test\\b.txt");
Path hdfsPath = new Path("/hdfsapi/test/hello.txt");
fileSystem.copyToLocalFile(false,hdfsPath,localPath,true);
}
@Test
public void listFiles() throws Exception {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hdfsapi/test")); for (FileStatus fileStatus : fileStatuses) {
String isDir = fileStatus.isDirectory() ? "文件夹" : "文件";
//副本
short replication = fileStatus.getReplication();
//大小
long len = fileStatus.getLen();
//路径
String path = fileStatus.getPath().toString(); System.out.println(isDir + "\t" + replication + "\t" + len + "\t" + path);
}
}
@Test
public void delete() throws Exception{
fileSystem.delete(new Path("hdfsapi/test/"),true);
}
} 注意在查询文件的副本系数时如果是通过hadoop sell put上去的文件副本系数在伪分布式中是1,如果说是通过java api put上去的则副本系数是1,因为我们并没有在本地设置自己的副本系数,所以hadoop采用自己的副本系数
IDEA 创建HDFS项目 JAVA api的更多相关文章
- HDFS中JAVA API的使用
HDFS中JAVA API的使用 HDFS是一个分布式文件系统,既然是文件系统,就可以对其文件进行操作,比如说新建文件.删除文件.读取文件内容等操作.下面记录一下使用JAVA API对HDFS中的 ...
- HDFS的Java API
HDFS Java API 可以用于任何Java程序与HDFS交互,该API使我们能够从其他Java程序中利用到存储在HDFS中的数据,也能够使用其他非Hadoop的计算框架处理该数据 为了以编程方式 ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- Hadoop(五):HDFS的JAVA API基本操作
HDFS的JAVA API操作 HDFS在生产应用中主要是客户端的开发,其核心步骤是从HDFS提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件. 主 ...
- HDFS的java api操作
hdfs在生产应用中主要是针对客户端的开发,从hdfs提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件. 搭建开发环境 方式一(windows环境下 ...
- [转]HDFS中JAVA API的使用
HDFS是一个分布式文件系统,既然是文件系统,就可以对其文件进行操作,比如说新建文件.删除文件.读取文件内容等操作.下面记录一下使用JAVA API对HDFS中的文件进行操作的过程. 对分HDFS中的 ...
- 熟练掌握HDFS的Java API接口访问
HDFS设计的主要目的是对海量数据进行存储,也就是说在其上能够存储很大量文件(可以存储TB级的文件).HDFS将这些文件分割之后,存储在不同的DataNode上, HDFS 提供了两种访问接口:She ...
- 掌握HDFS的Java API接口访问
HDFS设计的主要目的是对海量数据进行存储,也就是说在其上能够存储很大量文件(可以存储TB级的文件).HDFS将这些文件分割之后,存储在不同的DataNode上, HDFS 提供了两种访问接口:She ...
- Sample: Write And Read data from HDFS with java API
HDFS: hadoop distributed file system 它抽象了整个集群的存储资源,可以存放大文件. 文件采用分块存储复制的设计.块的默认大小是64M. 流式数据访问,一次写入(现支 ...
随机推荐
- synchronized 和 lock 的区别
1.Lock不是Java语言内置的,synchronized是Java语言的关键字,因此是内置特性.Lock是一个类,通过这个类可以实现同步访问: 2.Lock和synchronized有一点非常大的 ...
- Group by与 having
注意:select 后的字段,必须要么包含在group by中,要么包含在having 后的聚合函数里. 1. GROUP BY 是分组查询, 一般 GROUP BY 是和聚合函数配合使用 group ...
- putty登录显示IP
登陆服务器 cd vi .bashrc 在尾部加入如下代码 if [ "$SSH_CONNECTION" != '' -a "$TERM" != 'linux' ...
- Visual Studio配置C/C++-PostgreSQL(9.6.3)开发环境(ZT)
https://www.2cto.com/database/201707/658910.html 开发环境 Visual Studio 2017[15.2(26430.16)] PostgreSQL ...
- Haskell语言学习笔记(75)Conduit
安装 conduit $ cabal install conduit Installed conduit-1.3.0.3 Prelude> import Conduit Prelude Cond ...
- 转: python requests的安装与简单运用
requests是Python的一个HTTP客户端库,跟urllib,urllib2类似,那为什么要用requests而不用urllib2呢? 官方文档中是这样说明的: python的标准库urlli ...
- Android 开发进入Linux系统执行命令 2018-5-25 Fri.
/** * 进入linux cmd执行命令 * * @param command * @return */ private boolean runRootCommand(String command) ...
- Android EditText 操作。。。
EditText请求焦点三连击... editText.setFocusable(true); editText.setFocusableInTouchMode(true); editText.req ...
- Hibernate 再接触 Hello world 模拟Hibernate
没有Hibernate以前 Cilent 客户端 new出一个对象 然后执行JDBC 然后这样的访问数据库并不是面向对象语言 使用Hibernate以后 Cilent new 出一个对象后 访问配置文 ...
- supervisord 进程管家
s supervisor supervisor管理进程,是通过fork/exec的方式将这些被管理的进程当作supervisor的子进程来启动,所以我们只需要将要管理进程的可执行文件的路径添加到sup ...