大数据以及Hadoop相关概念介绍
一、大数据的基本概念
1.1、什么是大数据
大数据指的就是要处理的数据是TB级别以上的数据。大数据是以TB级别起步的。在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如:
文件占用的存储空间代表的就是该文件的大小,在计算机当中,文件的大小可以采用以下单位来表示,各个单位之间的转换关系如下:

平时我们在我们自己的电脑上面常见的就是Byte、KB、MB、GB这几种,那么究竟什么是大数据呢,大数据的起步是以TB级别开始的,1TB=1024GB,而我们处理的数据可能会到达PB级别,1PB=1024TB,那可想而知,数据量是多么庞大,所以大数据指的就是要处理的数据是TB级别以上的数据。而对于这些TB级别以上的数据,一般情况下,一台计算机的硬盘存储空间是无法存储那么大的数据,我们现在的普通电脑一般都是一块硬盘,而硬盘容量一般都是500GB左右,有的是1TB,假设现在有1PB的数据要存储,我们给每一台计算机配置10块硬盘,每一块硬盘都是1T的存储容量,那么也得要使用100多台电脑才能够存储得下1PB的数据。所以说,当我们的数据规模达到一定的程度的时候,我们以往的一些问题的解决办法在这种场景下已经变得不适用了。
1.2、大数据的特征
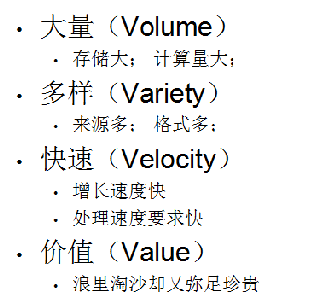
大数据,顾名思义,第一个特征就是数据量大,需要非常大的存储空间进行存储,而如果要处理这些海量的数据,那么计算量可想而知,所以计算量非常庞大。而这些数据的来源往往也是多样化的,数据的格式也是多样化的,在我们平时的应用系统开发中,我们要处理的数据来源大多数是存储在数据库中的数据又或者是存储在文件当中,而在大数据时代,我们一个系统要处理的数据来源是多种多样的,这些数据的来源可能是来自数据库,也可能是来自一些监控采集数据,或者是一些科研数据,而数据的格式可能有普通文本,图片、视频、音频、结构化的,非结构化的等等,反正什么样的数据都有。在大数据时代,数据的增长速度是非常快的,例如我们每天打电话,发短信,我们打出去的电话和发出去的短信在移动和联通公司都会有相应的记录,而这样的数据每天都会产生几亿条,数据量的增长速度可想而知,因此要求处理数据的应用系统的处理速度也要快,当我们想展示一些数据给用户看时,如果应用系统的处理速度不够快,那么给用户的体验是非常差的。另外,在大数据领域,我们从海里数据中能够提取到的相对有价值的数据也是非常有限的,我们处理几十个T的数据,从这些数据当中能够提取出来的有价值的信息也是非常少的,大数据分析要想得到一些有价值的结果,那么要求数据要比较全。比如,我们想分析一个用户的购物习惯,她平时喜欢在京东和天猫、淘宝这些电子商务网站上面进行购物,我们分析她在京东商城上面的购物行为时,我们不光要分析她最近一次的购买行为,还要分析她很长一段时间内的历史购买行为,以及在其他电商网站的购买行为,如果我们真的想一体地分析用户的生活习惯,那么不光是要分析她的购物行为,还要分析她的社交行为,比如在一些社交网站上面平时和哪些人联系最多,平时喜欢讨论一些什么话题,从事的职业,年龄,性别等,拿到的数据越全,我们分析的结果就会越准确,所以大数据不光是要求数据量要大,更重要要的是数据要全面,要多维度的,这样我们提取到的数据才是比较有价值,比较准确的。大数据处理领域在价值这一块是稀疏型的,从海量数据当中能够提取到的有价值的数据是非常稀少的。
1.3、存在有大数据的行业
放眼观世界,现在各行各业每天都会产生大量的数据,21世纪是一个互联网时代,一个信息化的时代,我们这一代人都不可避免地在一些IT系统当中留下我们的脚印,存在有大数据的典型的行业有以下几个行业:

互联网企业是最早收集大数据的行业,最典型的代表就是Google和百度,这两个公司是做搜索引擎的,数量都非常庞大,每天都要去把互联网上的各种各样的网页信息抓取下来存储到本地,然后进行分析,处理,当用户想通过搜索引擎搜索一些他们关心的信息时,Google和百度就从海量的数据当中提取出相对于对用户而言是有用的信息,然后将提取到的结果反馈给用户,据说Google存储的数据量已经到达了上百个PB,这个数据量是非常惊人的。类似于Fackbook这样的SNS(社交网站)因为用户量比较多,用户每天在网站上面分享一些文章,图片,视频,音频等信息,因此每天产生的数据量也是非常庞大的。
二、大数据技术要解决的技术难题
2.1、海量数据如何存储?
海量数据的存储问题也不是今天才有的,很早以前就出现了,一些行业或者部门因为历史的积累,数据量也达到了一定的级别,当一台电脑无法存储这么庞大的数据时,采用的解决方案是使用NFS(网络文件系统)将数据分开存储,NFS系统的架构如下图所示:
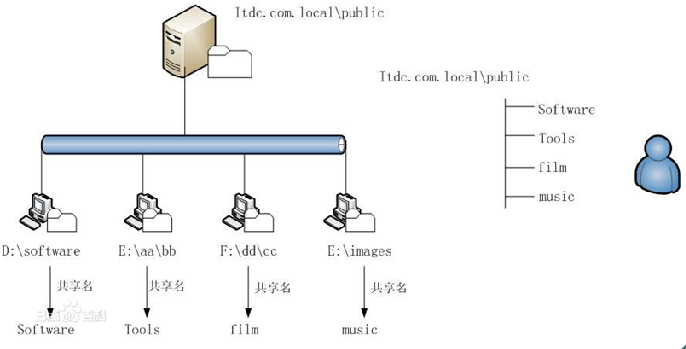
NFS这种解决方案就是同时架设多台文件服务器,如下图所示:
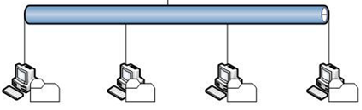
然后在文件服务器上面设置共享目录,例如图中显示的【D:\software、E:\aa\bb、F:\dd\cc、E:\images】
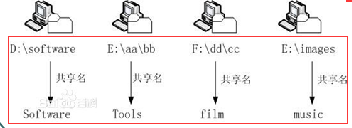
这样我们就可以把文件分类存放到各个文件服务器上面的共享目录当中,一台电脑的存储空间不够用,那么我们就将数据分散到多台电脑进行存储,而这些文件服务器上面的共享目录对于用户来说是透明的,用户会以为自己存放数据的【Software、Tools、film、music】这些目录都是属于【Itdc.com.local】这台文件服务器里面的【public】目录下的子目录,在NFS系统中,【Itdc.com.local】这台文件服务器只是起到一个中转站作用,将用户需要存放的海量数据分类存放到各个文件系统当中,这就解决了大数据的存储问题了。当用户需要访问分散在各个文件服务器中的文件资源时,它只需要访问【Itdc.com.local】这台文件服务器就可以了。
NFS虽然是解决了海量数据的存储问题,但是在大数据背景下,这种存储方案是不适用的,大数据不光是要解决数据存储问题,更重要的是海量数据的分析,而NFS在海量数据分析方面不能够充分利用多台计算机同时进行分析。
2.2、海量数据如何计算
一个实际的需求场景——日志分析
对日志中每一个用户的流量进行汇总就和,如下图所示:

对于这样的一个日志文件,如果只有这么几行数据,我们一般会采用这样的处理方式:
1、读取一行日志
2、抽取手机号和流量字段
3、累加到HashMap中
4、遍历输出结果
那么问题来了,如果数据量变得很大呢,比如一个日志文件里面有几个GB数据,
- 如果仍然一行一行去读,那么就会因为磁盘的IO瓶颈导致效率太低,速度太慢。
- 如果一次性加载到内存,那么就会因为单台计算机的内存空间有限而导致内存溢出。
- 如果将中间结果全部缓存到HashMap中,那么也会因为单台计算机的内存空间有限而导致内存溢出。
- 可以选择采用多线程处理,但是依然无法改变资源瓶颈的现实,因为一台计算器的CPU资源,内存资源,磁盘IO瓶颈是定,创建再多的线程也无法改变这个现实。
所以当一个日志文件里面存储了几个GB数据,那么这种情况下就不能采用这种传统的处理方式了。可以看到,在大数据背景下,我们一个简单的业务场景,比如这里的统计用户流量,在数据量变得很大的时候,原来不是问题的一些东西现在都成了问题。那么这些问题该如何解决呢?
解决思路一
纵向扩展,也就是升级硬件,提高单机性能(增加内存,增强CPU、用更高性能的磁盘(如固态硬盘)),比如可以购买IBM的高端服务器。

优点:
1、简单易行
缺点:
1、单台计算机的扩展空间有限,CPU、内存、磁盘再怎么扩展也是有限的,无法无限扩展。
2、成本高(高端服务器非常昂贵,几百万甚至上千万一台,一般的小公司承受不起这样高昂的成本)
解决思路二
横向扩展,用多台节点分布式集群处理 (通过增加节点数量提高处理能力,这里说的节点指的就是一台计算机)

核心思想:任务分摊,通过协作来实现单节点无法实现的任务。
优点:
1、成本相对低(可采用普通机器)
2、易于线性扩展
缺点:
系统复杂度增加,我们要将我们的web应用部署到每一个节点上面,而多个节点协同工作时就要考虑以下几个问题
1、如何调度资源
2、任务如何监控
3、中间结果如何调度
4、系统如何容错
5、如何实现众多节点间的协调
分布式计算的复杂性就体现在这样的5个问题里面。
三、Hadoop相关概念介绍
3.1、大数据行业的标准——Hadoop
Hadoop是一个开源的可运行于大规模集群上的分布式文件系统和运行处理基础框架
Hadoop擅长于在廉价机器搭建的集群上进行海量数据(结构化与非结构化)的存储与离线处理。
Hadoop就是一门用来处理大数据的技术,就是用来解决上述提到的分布式计算里面的5个技术难题的。
3.2、Hadoop的Logo图片

3.3、Hadoop的由来
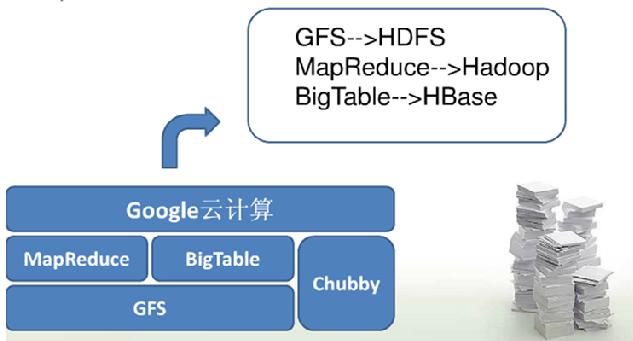
3.4、Hadoop的核心组件
3.4.1、海量存储——HDFS(Hadoop分布式文件系统,Hadoop Distributed File System)
- 分布式易扩展
- 廉价易得
- 高吞吐量
- 高可靠性
3.4.2、分布式并行计算——资源调度(Yarn)+编程模型(MapReduce)
- 大容量高并发
- 封装分布式实现细节
- 大大提高分析效率
3.5、Hadoop的学习路线
- Linux系统基本操作能力
- java开发语言
- Hadoop核心组件
- MapReduce或Spark等编程模型
- Zookeeper-Sqoop-Flume等工具组件
- NoSQL技术,Hbase
- 数据分析挖掘、机器学习、Mahout
3.6、学习Hadoop技术的书籍推荐
1、Hadoop权威指南第三版
2、Hadoop技术内幕
3、Hadoop实战
大数据以及Hadoop相关概念介绍的更多相关文章
- 【转】大数据以及Hadoop相关概念介绍
原博文出自于: http://www.cnblogs.com/xdp-gacl/p/4230220.html 感谢! 一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以 ...
- Hadoop学习总结(1)——大数据以及Hadoop相关概念介绍
一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以上的数据.大数据是以TB级别起步的.在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如: 文件占用的存储空 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- [Hadoop 周边] 浅谈大数据(hadoop)和移动开发(Android、IOS)开发前景【转】
原文链接:http://www.d1net.com/bigdata/news/345893.html 先简单的做个自我介绍,我是云6期的,黑马相比其它培训机构的好偶就不在这里说,想比大家都比我清楚: ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 细细品味大数据--初识hadoop
初识hadoop 前言 之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心 ...
随机推荐
- 深入理解java虚拟机-01 走进java
第一章是对java的产生,历史的整体介绍 java的使用很广泛,安装jdk的时候会看到一句广告语runs in 10 billions machines.使用java的设备多达几十亿台 1.概述 优点 ...
- jdk678910新特性地址
jdk678910新特性地址 https://blog.csdn.net/f641385712/article/details/81289401 每篇一句:每个人受到的尊重从来都不是应得的,而是赢得的 ...
- InnoDB Lock浅谈
数据库使用锁是为了支持更好的并发,提供数据的完整性和一致性.InnoDB是一个支持行锁的存储引擎,锁的类型有:共享锁(S).排他锁(X).意向共享(IS).意向排他(IX).为了提供更好的并发,Inn ...
- nodejs查询数据库后,获取result结果集并赋值返回
nodejs获取了查询结果,但不能返回出去, 情形如下: var query = function (path,id,param,sqlWhere,res){ var aa = 111;var sql ...
- 算法之DP
一般DP 都是有模板的,先初始化,然后找到不同状态下数值的关系,使得某个状态可用另一个状态由一个固定的方式转移而来,列出状态转移方程,这就是DP: 例题 P1216 [USACO1.5]数字三角形 N ...
- 查看浏览器中Cookie信息
一般在浏览器的设置中能找到Cookie的相关设置和查看信息 在js中使用 alert(document.cookie) 也能查看到当前页面的 Cookie 信息实现方式1.若是自己开发的页面 直接在j ...
- 025 Spark中的广播变量原理以及测试(共享变量是spark中第二个抽象)
一:来源 1.说明 为啥要有这个广播变量呢. 一些常亮在Driver中定义,然后Task在Executor上执行. 如果,有多个任务在执行,每个任务需要,就会造成浪费. 二:共享变量的官网 1.官网 ...
- 附001.etcd配置文件详解
一 示例yml配置文件 # This is the configuration file for the etcd server. # Human-readable name for this m ...
- maven自定义脚手架(快速生成项目)
Maven之自定义archetype生成项目骨架 利用脚手架生成 新项目 命令行方式 mvn archetype:generate \ -DarchetypeGroupId=com.xxx \ -Da ...
- Android-Window(一)——初识Window
Android-Window(一)--初识Window 学习自 <Android开发艺术探索> https://blog.csdn.net/qian520ao/article/detail ...