025 Spark中的广播变量原理以及测试(共享变量是spark中第二个抽象)
一:来源
1.说明
为啥要有这个广播变量呢。
一些常亮在Driver中定义,然后Task在Executor上执行。
如果,有多个任务在执行,每个任务需要,就会造成浪费。
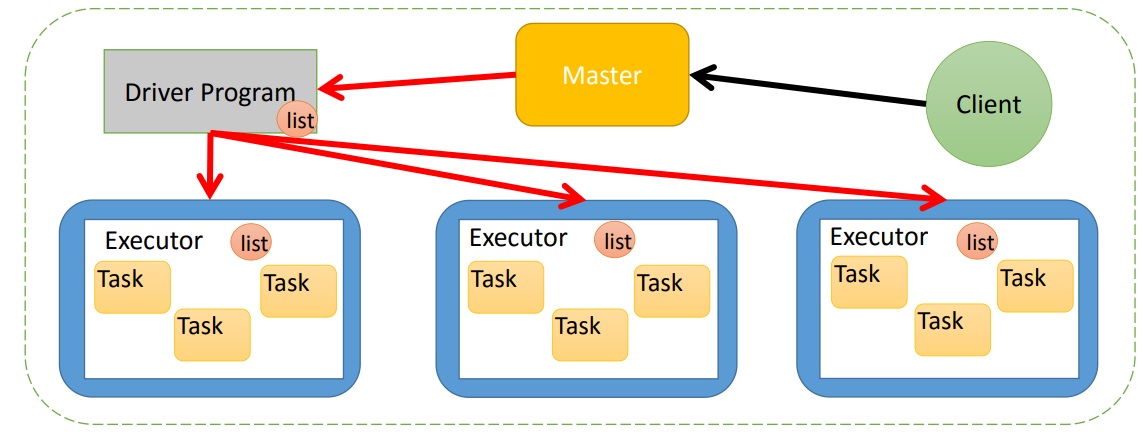
二:共享变量的官网
1.官网
有两种方式。

三:程序实现
1.Accumulators
类似于mapreduce中的用于累加数据的共享变量
这是一个官方的案例。

2.官网上的程序

3.广播变量程序实现
作用:
可以减少网络传输量
可以解决大表join小表的问题(将小表的数据广播出去)
注意:
不能广播RDD,可以广播RDD中的数据。

025 Spark中的广播变量原理以及测试(共享变量是spark中第二个抽象)的更多相关文章
- spark中的广播变量broadcast
Spark中的Broadcast处理 首先先来看一看broadcast的使用代码: val values = List[Int](1,2,3) val broadcastValues = sparkC ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- Spark大师之路:广播变量(Broadcast)源代码分析
概述 近期工作上忙死了--广播变量这一块事实上早就看过了,一直没有贴出来. 本文基于Spark 1.0源代码分析,主要探讨广播变量的初始化.创建.读取以及清除. 类关系 BroadcastManage ...
- Spark大师之路:广播变量(Broadcast)源码分析
概述 最近工作上忙死了……广播变量这一块其实早就看过了,一直没有贴出来. 本文基于Spark 1.0源码分析,主要探讨广播变量的初始化.创建.读取以及清除. 类关系 BroadcastManager类 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- C++晋升之std中vector的实现原理(标准模板动态库中矢量的实现原理)
我们实现的数据结构是为了解决在执行过程中动态的开辟空间使用(比如我们不停的输入,输入的多少我们不确定) 假设当你看到这篇文章的话,就当作是零食咀嚼,营养没有有BUG,能够直接看我博客中文章:CPU对内 ...
- spark 广播变量
Spark广播变量 使用广播变量来优化,广播变量的原理是: 在每一个Executor中保存一份全局变量,task在执行的时候需要使用和这一份变量就可以,极大的减少了Executor的内存开销. Exe ...
- Spark学习之路(六)—— 累加器与广播变量
一.简介 在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: 广播变量 ...
随机推荐
- ASP.NET MVC学习之Log4Net配置(日志记录)
Log4Net配置笔记---- 首先,添加对log4net.dll的引用. 在Web.config文件下的Configuration节点下添加Log4Net的配置信息: <!--Log4Net配 ...
- AIO + ByteBufferQueue + allocateDirect 终于可以与NIO的并发性能达到一致。
看到这个标题,你可能会惊讶,相比NIO,AIO不就是为了在高并发的情况下代替NIO的吗? 是的,没错,但是在并发不高的情况下,AIO的性能表现很多时候还不如NIO. 在一台机子上用ab进行并发压力测试 ...
- 各种蕴含算法思想的DP - 3
内容中包含 base64string 图片造成字符过多,拒绝显示
- 21天实战caffe笔记_第三天
1 深度学习工具汇总 (1) caffe : 由BVLC开发的基于C++/CUDA/Python实现的卷积神经网络,提供了面向命令行.Matlab和Python的绑定接口.特性如下: A 实现了前馈 ...
- centos7下设置opencv环境变量
最近要装YOLO,但是MAKE的时候总是找不到OPENCV的路径, 原因是:我以前卸载过一次OPENCV,然后自己重新安装了opencv2.4.10, 因为当时只在QT 中用,所以编译完也没有设置环 ...
- 【leetcode】Path Sum2
Given a binary tree and a sum, find all root-to-leaf paths where each path's sum equals the given su ...
- Sql数据库不能频繁连接
这个问题怎么说呢,我频繁的读一个json文件,所以就频繁的去连接了数据库.所以导致了数据库后来就不工作了(罢工?O(∩_∩)O哈哈~) 解决办法是加一个判断语句,如果是空的就连接,否则就别一直连接了. ...
- [转载]CSS Tools: Reset CSS
http://meyerweb.com/eric/tools/css/reset/ The goal of a reset stylesheet is to reduce browser incons ...
- Javascript - 操作符
操作符(Operator) void 如果void后是数字,就返回NAN,否则返回Undefined. alert(void "hello");//跟的字符 print undef ...
- Web安全测试-WebScarab
[功能] WebScarab是一个用来分析使用HTTP和HTTPS协议的应用程序框架.其原理很简单,WebScarab可以记录它检测到的会话内容(请求和应答),并允许使用者可以通过多种形式来查看记录. ...