java爬虫学习
java尝试爬取一些简单的数据,比python复杂点
示例:爬取网站中的所有古风网名:http://www.oicq88.com/gufeng/,并储存入数据库(mysql)
jdk版本:jdk1.8
编辑器:idea
项目构建:maven
所需jar包:http://jsoup.org/packages/jsoup-1.8.1.jar
或maven依赖如下:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>
具体代码如下:
package com.ssm.web.timed; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import com.ssm.commons.JsonResp;
import com.ssm.utils.ExportExcel;
import org.apache.log4j.Logger;
import org.jsoup.*;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; import javax.servlet.http.HttpServletResponse; @RequestMapping
@RestController
public class TestCrawlerTime {
private Logger log = Logger.getLogger(this.getClass()); //根据url从网络获取网页文本
public static Document getHtmlTextByUrl(String url, String page) {
Document doc = null;
try {
//doc = Jsoup.connect(url).timeout(5000000).get();
int i = (int) (Math.random() * 1000); //做一个随机延时,防止网站屏蔽
while (i != 0) {
i--;
}
doc = Jsoup.connect(url + page).data("query", "Java")
.userAgent("Mozilla").cookie("auth", "token")
.timeout(300000).get();
} catch (IOException e) {
/*try {
doc = Jsoup.connect(url).timeout(5000000).get();
} catch (IOException e1) {
e1.printStackTrace();
}*/
System.out.println("error: 第一次获取出错");
}
return doc;
} //递归查找所有的名字
public static List getAllNames(List<String> names, String url, String page){
Document doc = getHtmlTextByUrl(url, page);
Elements nameTags = doc.select("div[class=listfix] li p"); //名字标签
for (Element name : nameTags){
names.add(name.text());
}
Elements aTags = doc.select("div[class=page] a[class=next]"); //页数跳转标签
for (Element aTag : aTags){
if ("下一页".equals(aTag.text())){ //是下一页则继续爬取
String newUrl = aTag.attr("href");
getAllNames(names, url, newUrl);
}
}
return names;
} /**
* @Description: 导出爬取到的所有网名
* @Param:
* @return:
* @Author: mufeng
* @Date: 2018/12/11
*/
@RequestMapping(value = "/exportNames")
public JsonResp export(HttpServletResponse response){
log.info("导出爬取到的所有网名");
String target = "http://www.oicq88.com/";
String page = "/gufeng/1.htm";
List names = new ArrayList();
getAllNames(names, target, page);
System.out.println(names.size());
List<Object[]> lists = new ArrayList<>();
Integer i = 1;
for (Object name : names){
lists.add(new Object[]{i, name});
i ++;
}
String[] rowName = new String[]{ "", "网名"};
ExportExcel exportExcel = new ExportExcel("古风网名大全", rowName, lists);
try {
exportExcel.export(response);
} catch (Exception e) {
e.printStackTrace();
}
return JsonResp.ok();
} public static void main(String[] args) {
String target = "http://www.oicq88.com/";
String page = "/gufeng/1.htm";
List names = new ArrayList();
getAllNames(names, target, page);
System.out.println(names.size());
System.out.println(names.get(0));
System.out.println(names.get(names.size()-1));
} }
运行结果如下:
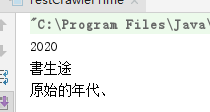

参考教程:https://www.cnblogs.com/Jims2016/p/5877300.html
https://www.cnblogs.com/qdhxhz/p/9338834.html
https://www.cnblogs.com/sanmubird/p/7857474.html
java爬虫学习的更多相关文章
- Java 爬虫学习
Java爬虫领域最强大的框架是JSoup:可直接解析具体的URL地址(即解析对应的HTML),提供了一套强大的API,包括可以通过DOM.CSS选择器,即类似jQuery方式来取出和操作数据.主要功能 ...
- 半途而废的Java爬虫学习经历
最近在面试,发现Java爬虫对于小数据量数据的爬取的应用还是比较广,抽空周末学习一手,留下学习笔记 Java网络爬虫 简单介绍 爬虫我相信大家都应该知道什么,有什么用,主要的用途就是通过程序自动的去获 ...
- Java爬虫学习(3)之用对象保存新浪微博博文
package com.mieba; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.c ...
- Java爬虫学习(1)之爬取新浪微博博文
本次学习采用了webmagic框架,完成的是一个简单的小demo package com.mieba.spiader; import us.codecraft.webmagic.Page; impor ...
- Java爬虫学习(2)之用对象保存文件demo(1)
package com.mieba.spider; import java.util.ArrayList; import java.util.List; import java.util.Vector ...
- java爬虫案例学习
最近几天很无聊,学习了一下java的爬虫,写一些自己在做这个案例的过程中遇到的问题和一些体会1.学习目标 练习爬取京东的数据,图片+价格+标题等等 2.学习过程 1·开发工具 ...
- (java)Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页
Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页,输出 职位名称*****公司名称*****职位月薪*****工作地点*****发布日期 import java.io.I ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- 学习Java爬虫文档的学习顺序整理
1.认识正则表达式(Java语言基础) https://www.toutiao.com/i6796233686455943693/ 2.正则表达式学习之简单手机号和邮箱练习 https://www.t ...
随机推荐
- ubuntu安装vmare tools
在vm中安装vm tools, 点击安装 vmware tools cp VMwareTools-10.0.10-4301679.tar.gz /home/YOURNAME/ //因为cd ...
- mysql之零碎知识
一 视图 什么是视图:视图就是一张虚拟表.方便查看. 创建视图:create view 起名 as sql语句 #两张有关系的表 mysql> select * from course; +-- ...
- shell脚本清空redis库缓存
前提: 现在做的一个业务系统,用了redis做缓存. 系统做了缓存,通常在系统正常使用的过程中,可以节省很多系统资源,特别是数据库资源. 但是,在开发.测试或者系统遇到问题的时候,也有很麻烦的事情. ...
- Servlet中(Session、cookies、servletcontext)的基本用法
/req: 用于获得客户端(浏览器)的信息 //res: 用于向客户端(浏览器)返回信息 1.session的设置: //得到和req相关联的session,如果没有就创建ses ...
- MES制造执行系统
mes : Manufacturing Execution System 制造执行系统 起因:ERP系统和底层设备之间出现了断层. 包括资源管理,生产调度,单元分配,生产跟踪,性能分析,文档管理,人 ...
- Java EE JAR包的说明
在java ee的开发中,jar文件是工程的基础,下面转载了网上兄弟一篇文章,简单介绍了一下,java ee中常用的jar文件的说明: activation.jar 与javaMail有关的jar包, ...
- CentOS和Ubuntu哪个好?
CentOS(Community ENTerprise Operating System)是Linux发行版之一,它是来自于Red Hat Enterprise Linux依照开放源代码规定释出的源代 ...
- bzoj3262(cdq分治模板)
裸的cdq,注意去重: #include<iostream> #include<cstdio> #include<cmath> #include<cstrin ...
- _杂谈_C语言历史
早期的操作系统软件主要是用汇编语言(包括UNIX操作系统在内)编写的.由于汇编语言依赖于计算机硬件,所以程序的可读性和可移植性都比较差,所以呢,为了提高操作系统软件的可读性和可移植性,最好改用高级语言 ...
- 用 gdb 调试 GCC 程序
Linux 包含了一个叫 gdb 的 GNU 调试程序. gdb 是一个用来调试 C 和 C++ 程序的强力调试器. 它使你能在程序运行时观察程序的内部结构和内存的使用情况. 以下是 gdb 所提供的 ...