基于tomcat的solr环境搭建(Linux)
♥♥ solr是基于lucene的一个全文检索服务器,提供了一些类似webservice的API接口,用户可以通过http请求solr服务器,进行索引的建立和索引的搜索。
索引建立的过程:用户提交的文本会经过分词器进行分词,分词后的关键字会存到索引库里,索引库是关键字和目标文档的映射集。
索引搜索的过程:用户提交的搜索文本也是会经过分析器,得到的关键字会去索引库查询对应的目标文档并返回给客户端,采用的是权重排序算法。
solr和lucene的区别:lucene是一些搜索工具包,任何应用可以引进这些jar包实现自己的搜索引擎系统,而solr是基于lucene的,封装好的搜索引擎系统。lucene需要自己维护索引文件。
solr几个重要的配置文件:solrconfig、schema.xml数据库配置文件、data-config(自定义,用于数据从数据库导入到solr)
Lucene专注于搜索底层的建设,而Solr专注于企业应用。
1.solr的安装

2.中文分词器的安装
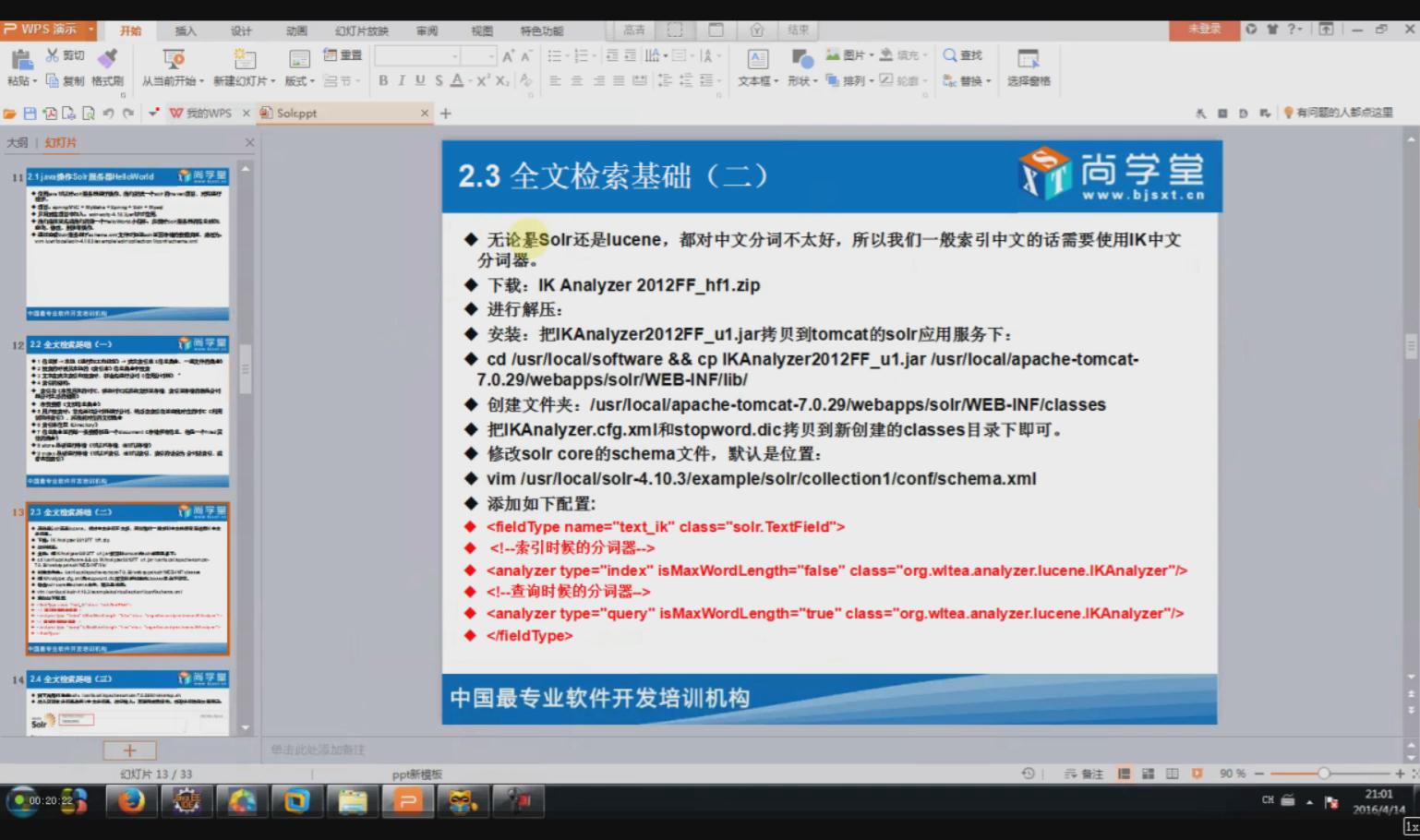
配置信息:
<!--中文分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
3.1 DIH全量同步
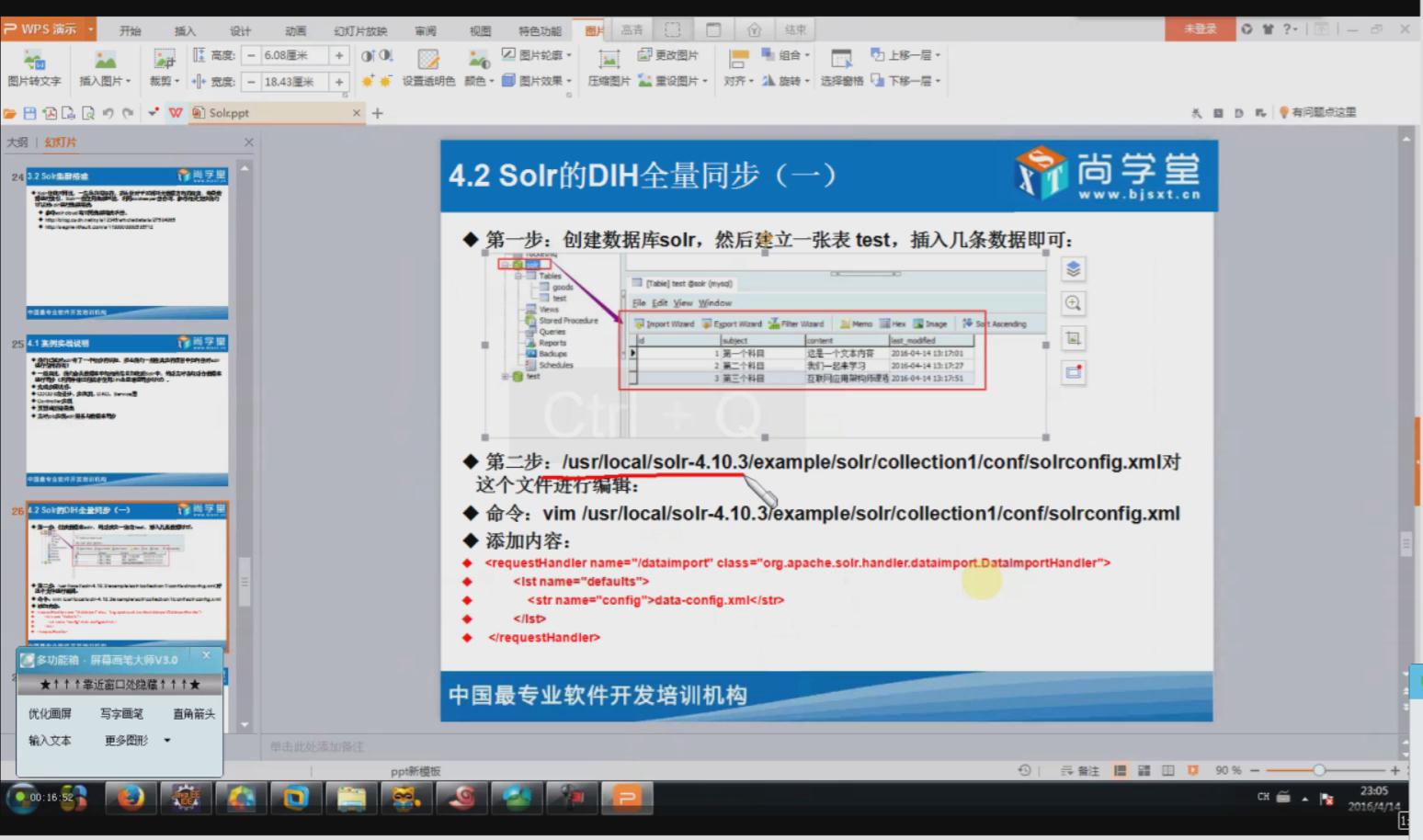
相关配置信息:
<!-- 数据导入配置 -->
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
3.2

相关配置信息:
3.3 schema.xml同步字段配置
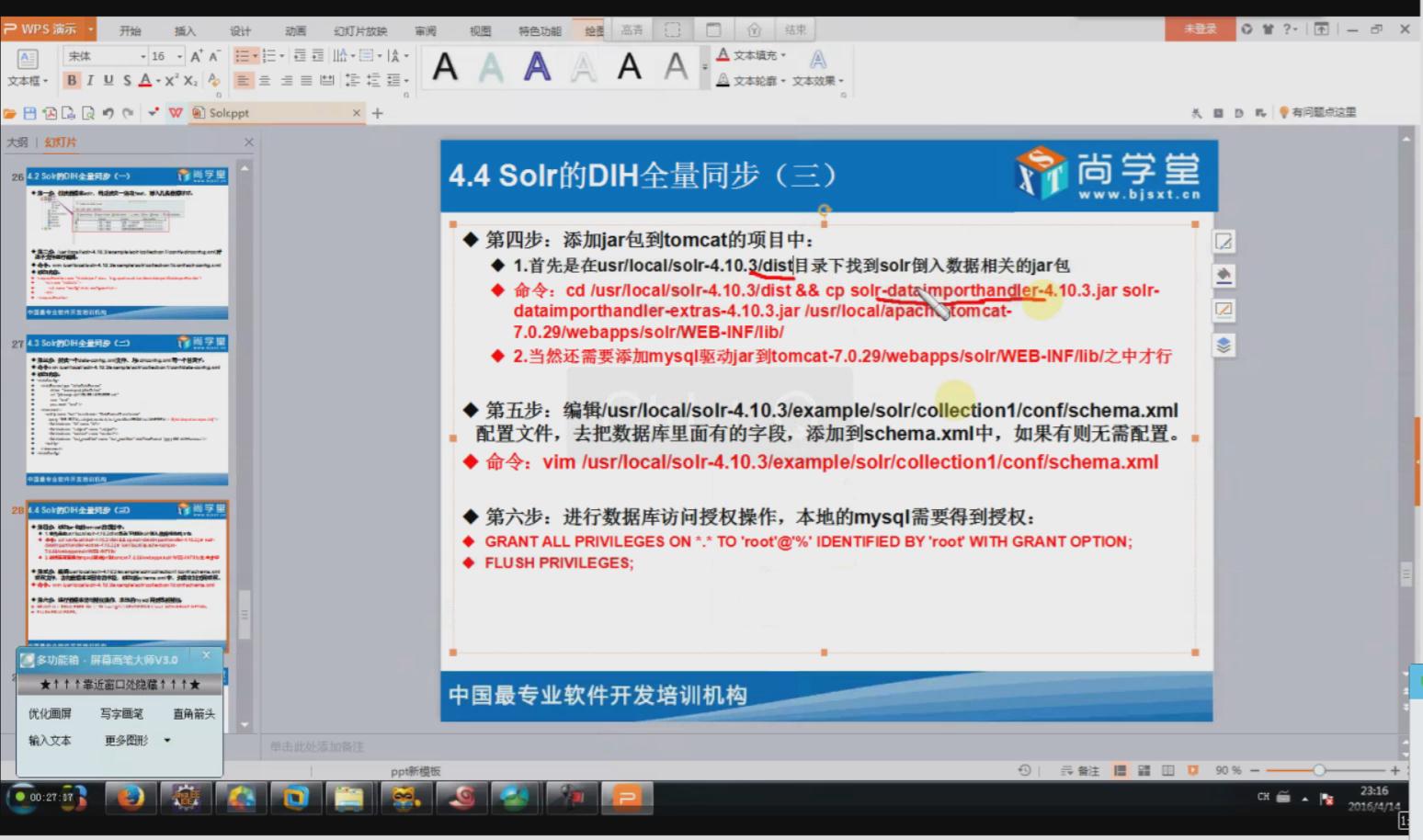
相关配置信息:
<!-- 同步mysql爬虫表的字段 -->
<field name="create_date" type="date" indexed="true" stored="true"/>
<field name="update_date" type="date" indexed="true" stored="true"/>
<field name="news_url" type="text_general" indexed="true" stored="true"/>
<field name="news_origin" type="text_general" indexed="true" stored="true"/>
<field name="key_word" type="text_general" indexed="true" stored="true"/>
<field name="news_html" type="text_ik" indexed="true" stored="true"/>
<field name="is_publish" type="int" indexed="true" stored="true"/>
<field name="is_del" type="int" indexed="true" stored="true"/>
<field name="flag_number" type="text_general" indexed="true" stored="true"/>
<field name="out_line" type="text_ik" indexed="true" stored="true"/>
<field name="state" type="int" indexed="true" stored="true"/>
<!-- 同步mysql爬虫表的字段end -->
4.1DIH的增量同步(其实就是修改data-config.xml配置文件)
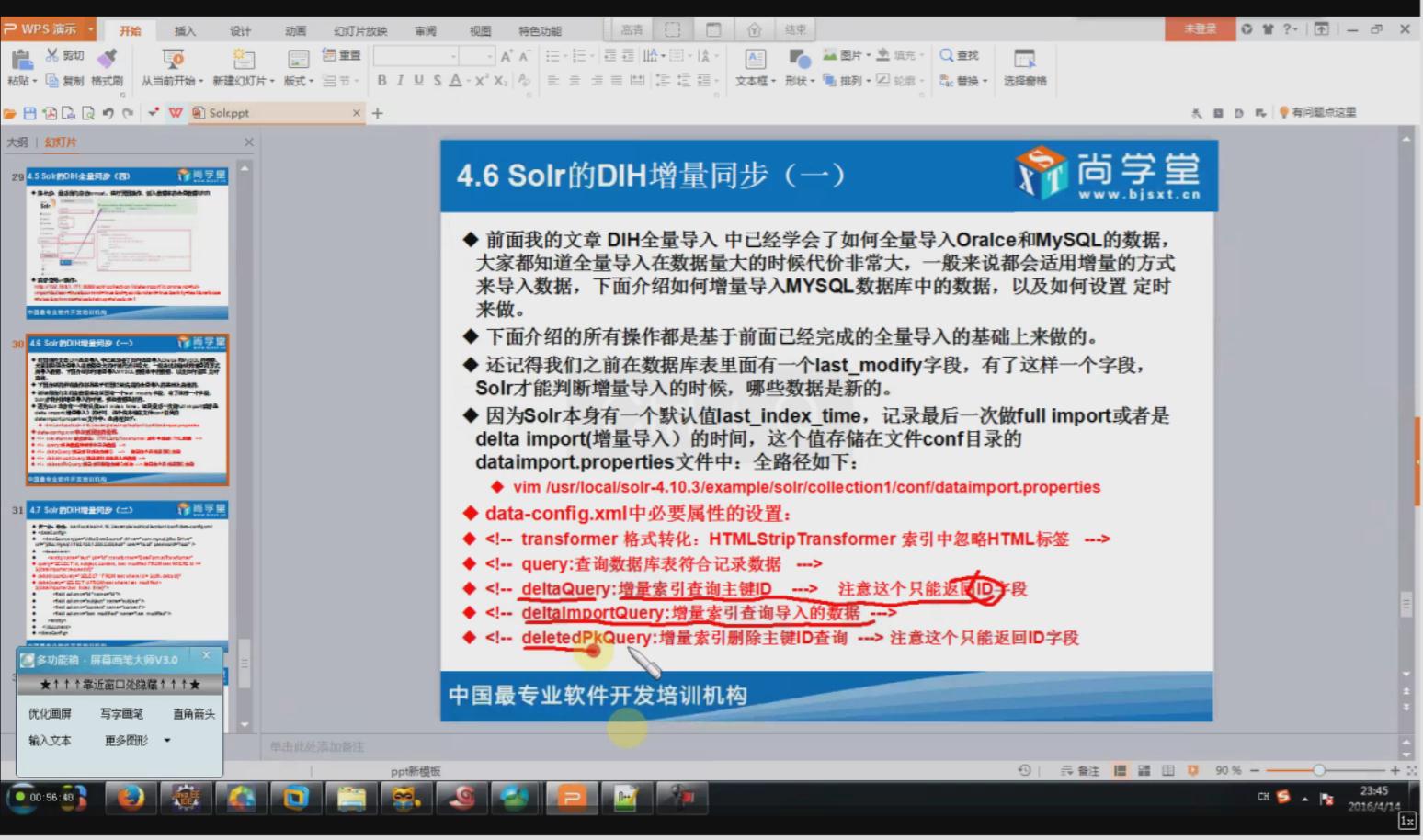
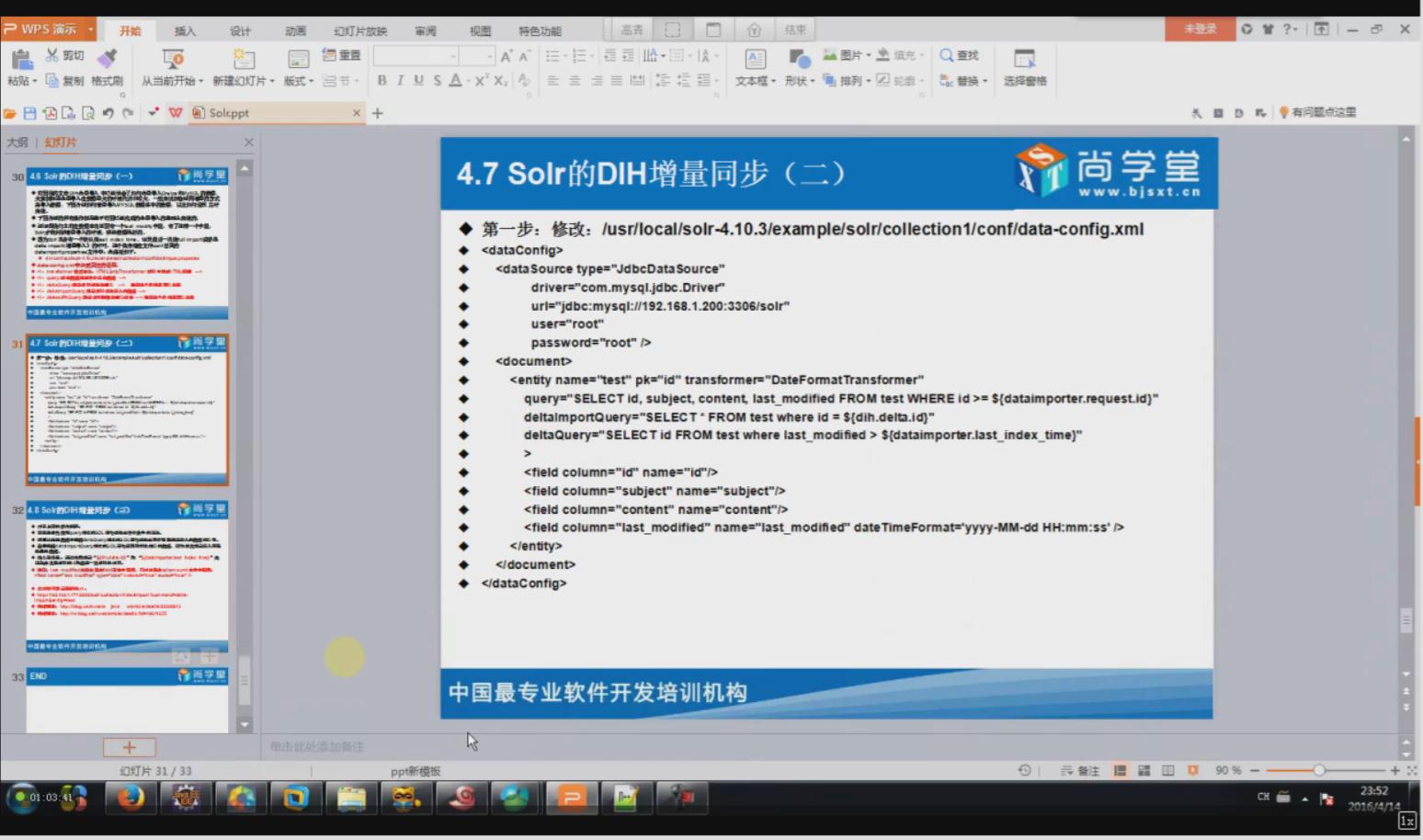
相关配置信息:
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.40.1:3306/shanghang" user="root" password="root" />
<document>
<entity name="consensus_data2" pk="id" transformer="DateFormatTransformer" query="select * from consensus_data2 where id >= '${dataimporter.request.id}'"
deltaImportQuery="select * from consensus_data2 where id = '${dih.delta.id}'"
deltaQuery="select id from consensus_data2 where create_date > '${dataimporter.last_index_time}'">
<field column="id" name="id" />
<field column="create_date" name="create_date" dateTimeFormat='yyyy-MM-dd HH:mm:ss'/>
<field column="update_date" name="update_date" dateTimeFormat='yyyy-MM-dd HH:mm:ss' />
<field column="news_url" name="news_url" />
<field column="news_origin" name="news_origin" />
<field column="keyWord" name="key_word" />
<field column="news_html" name="news_html" />
<field column="is_publish" name="is_publish" />
<field column="is_del" name="is_del" />
<field column="flag_number" name="flag_number" />
<field column="out_line" name="out_line" />
<field column="state" name="state" />
</entity>
</document>
</dataConfig>

基于tomcat的solr环境搭建(Linux)的更多相关文章
- jdk、tomcat、solr环境搭建
环境概述 1)操作系统:windows7旗舰版(64位) 2)jdk:jdk-8u131-windows-x64: 3)tomcat:apache-tomcat-9.0.0.M21 4)solr:so ...
- solr环境搭建
介绍摘自百度百科:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过 ...
- Ubuntu 基于Docker的TensorFlow 环境搭建
基于Docker的TensorFlow 环境搭建 基于(ubuntu 16.04LTS/ubuntu 14.04LTS) 一.docker环境安装 1)更新.安装依赖包 sudo apt-get up ...
- EOS Dapp开发(1)-基于Docker的开发环境搭建
随着EOS主网的上线,相信基于EOS的Dapp开发会越来越多,查阅了很多资料相关的开发资料都不是很多,只能自己摸索,按照网上仅有的几篇教程,先git clonehttps://github.com/E ...
- centos LAMP第一部分-环境搭建 Linux软件删除方式,mysql安装,apache,PHP,apache和php结合,phpinfo页面,ldd命令 第十九节课
centos LAMP第一部分-环境搭建 Linux软件删除方式,mysql安装,apache,PHP,apache和php结合,phpinfo页面,ldd命令 第十九节课 打命令之后可以输入: e ...
- 基于Python的Appium环境搭建合集
自动化一直是测试圈中的热聊,也是大家追求的技术方向.在测试中,往往回归测试也是测试人员的“痛点”.对于迭代慢.变更少的功能,就能用上自动化来替代人工回归,减轻工作量. 问题 在分享环境搭建之前,先抛出 ...
- [精华]Hadoop,HBase分布式集群和solr环境搭建
1. 机器准备(这里做測试用,目的准备5台CentOS的linux系统) 1.1 准备了2台机器,安装win7系统(64位) 两台windows物理主机: 192.168.131.44 adminis ...
- Solr环境搭建过程中遇到的问题
Solr下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/6.3.0 Solr搭建步骤转自:http://blog.csdn.net/wbcg ...
- Java部署环境搭建(Linux)
环境搭建必须jdk.tomcat.mysql(基础) 额外的软件包项目中可能用到 jdk:它包含jre和开发所需完整类库. tomcat:它是一个web容器,项目通常往webapps下扔,便于外界访问 ...
随机推荐
- Python基础之逻辑运算
逻辑运算 概念: 优先级() > not > and > or print(2 > 1 and 1 < 4 or 2 < 3 and 9 > 6 or 2 & ...
- GsonFormat的使用 (转)
一.Android Studio快速添加Gson 具体操作: 1.File->Project Structure: 2.app->Dependencies->&qu ...
- 打印低头思故乡 java
public static void main(String args[][){ char poet[] = str.tocharArray(); int pos = 18; while(true){ ...
- JS中取得<asp:TextBox中的值
var s = document.getElementById("<%=txt_DaShen.ClientID %>").value; 注:txt_DaShen 为as ...
- white-space和word-wrap和word-break所表示的换行和不换行的区别
一.前言 使得文本换行有很多方式, <br/>标签元素,能够强制使得所在位置文本换行 <p>元素,<div>设定宽度,都可以对文本内容实现自适应换行 对于长单词或者 ...
- vue的双向数据绑定实现原理
在目前的前端面试中,vue的双向数据绑定已经成为了一个非常容易考到的点,即使不能当场写出来,至少也要能说出原理.本篇文章中我将会仿照vue写一个双向数据绑定的实例,名字就叫myVue吧.结合注释,希望 ...
- f5主备切换演练
1.准备工作: 1)保证主备机同步 2)备份主备机配置 2.切换:所有操作均在主机 方法1:shutdown主机上联的核心交换机的端口: 此方法在主备切换过程中会丢1个包 方法2:命令行下reboot ...
- 《基于Nginx的中间件架构》学习笔记---4.nginx编译参数详细介绍
通过nginx -V查看编译时参数: 在nginx安装目录下,通过./configure --help,查看对应版本ngnix编译时支持的所有参数: Nginx编译参数详细介绍: --help 显示本 ...
- Django的rest_framework的视图之Mixin类编写视图源码解析
Mixin类编写视图 我们这里用auther表来做演示,先为auther和autherdetail写2个url url(r'^autherdetail/(?P<id>\d+)', view ...
- centos更换yum源为aliyun源
国外的yum源由于众所周知的GFW原因,有的被墙,有的很慢,阿里云依靠强大的技术优势建立了国内的开源镜像.阿里云Linux安装镜像源地址:http://mirrors.aliyun.com/ 第一步: ...