Kmeans原理与实现
原理
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
实现
http://www.cnblogs.com/zjutzz/p/5924762.html
无监督学习之K-均值算法分析与MATLAB代码实现
前言
K-均值是一种无监督的聚类算法。首先我们要知道什么是无监督,无监督就是说在数据集中,数据是没有标签的。在有监督的数据集中,数据的形式可能是这样:{(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}{(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}。而在无监督的数据集中,数据的形式是:{x(1),x(2),...,x(m)}{x(1),x(2),...,x(m)}。所谓的标签,就是有没有y。
无监督学习一般用来做什么呢?比如市场分割,也许在你的数据库中有很多用户的数据,你希望将用户分成不同的客户群,这样对不同类型的客户你可以分别提供更合适的服务。再比如图片压缩,假如图片有256种颜色,我们想用16种来表示,那么我们也可以用聚类的方式来将256种颜色分成16类。
K-均值算法
而K-均值是一个很普遍的聚类算法。这个算法接受一个未标记的数据集,然后将数据集聚类成不同的组。
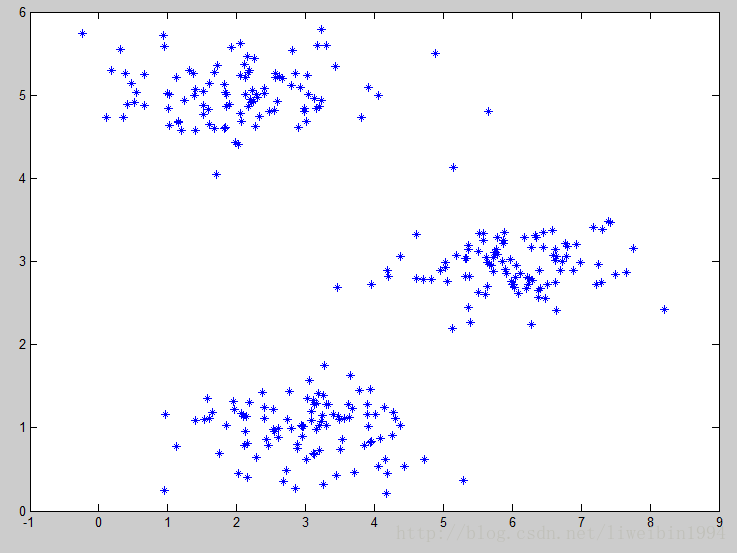
如上图所示,我们可以很直观地看出数据集大致可以分成三类,K-均值算法的思想就是选择三个随机的点(当然,分成K类就K个随机的点),称为聚类中心(cluster centroids)。
然后对于数据集中的每一个数据,按照距离三个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。如下图:
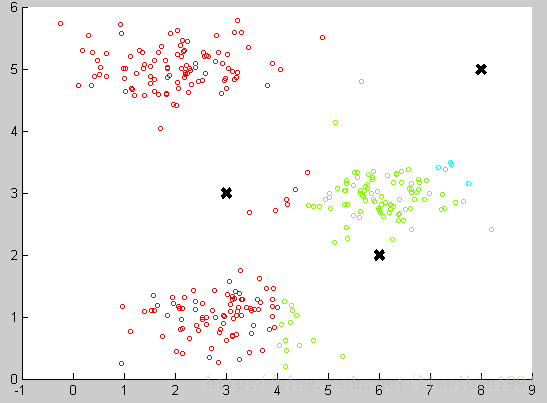
图中三个黑色的点就是三个聚类中心,数据集也根据与聚类中心的远近分成三组。可以看出,此时的分类还是不好的。那么我们接下来应该怎么做才能让这个分类效果更好呢?
我们可以计算每个组(数据集被分成红绿蓝这三个组)的数据的平均值,将该组所关联的中心点移动到平均值的位置。 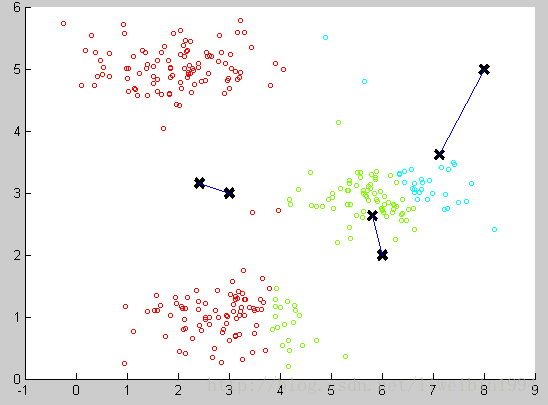
通过计算平均值,将聚类中心移动到平均值所在的位置,然后我们重复这个过程,直到中心点不再变化。最后就可以得到下面的效果:
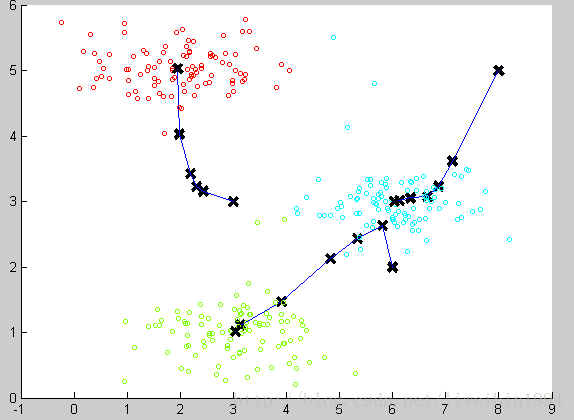
可以看到聚类的效果还不错。
算法步骤与伪代码
根据上面的分析,算法的步骤可以归结为:
第一步,随机选择三个点,假设为A,B,C;
第二步:计算数据集中的每个数据x(i)x(i)分别到A,B,C的距离,这样每个数据就能计算出三个距离,哪个距离小,该数据就属于哪个聚类中心。最后就会得到三组类别的数据。
第三步,计算三组类别的数据的均值,分别作为A,B,C的新位置。
第四步,重复第二步和第三步直到迭代结束或者A,B,C的位置不再移动。
K-均值的伪代码如下:
用μ1,μ2,...,μKμ1,μ2,...,μK来表示聚类中心,用c(1),c(2),...,c(m)c(1),c(2),...,c(m)来存储于第i个训练数据最近的聚类中心的索引(即从1到K的某一个数),
Repeat{
for i=1 to m
c(i)c(i) := index(from 1 to K )of cluster centroid closest to x(i)x(i)
for k = 1 to K
μkμk := average(mean) of points assigned to cluster k
}
优化目标(代价函数)
K-均值最小化问题,是要最小化所有的数据点与其关联的聚类中心之间的距离之和。因此,K-均值的代价函数:
其中,μc(i)μc(i)代表与x(i)x(i)最近的聚类中心点。我们的优化目标就是要找到使得代价函数最小的c(1),c(2),...,c(m)c(1),c(2),...,c(m)和μ1,μ2,...,μKμ1,μ2,...,μK。
上面的伪代码中,第一个for循环就是用于减少c(i)c(i)引起的代价,因为在第一个循环中,聚类中心是不变的,所以要求数据都去找最近的聚类中心,这样总的距离才是最小的。
第二个循环则是用于减小μiμi引起的代价,因为这里改变的是聚类中心的位置,而数据的类别不变,所以要求聚类中心尽可能在其所属数据的中心。
初始化问题
在上面的步骤分析中,运行K-均值算法之前,我们首先要随机初始化所有的聚类中心。如何初始化比较好呢?
- 首先,应该选择K < m,也就是聚类中心的个数要小于所有训练集实例的数量。
- 随机选择K个训练样本,然后令K个聚类中心分别与这K个训练样本相等。
上面一开始说随机取K个点这种做法其实不推荐。K-均值的一个问题就在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
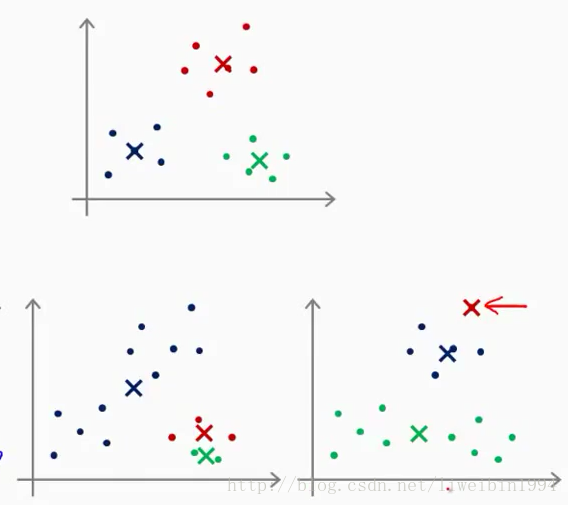
图中上面一个坐标系是分类正常,下面两个都是分类不好的情况。为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。这种方法在K较小的时候(2~10)还是可行的,但是如果K较大,这么做也可能不会有明显的效果。
K的选择
其实没有所谓的最好的选择聚类数K的方法,通常是根据不同的问题,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的的聚类数。
肘部法则
一般来说,人们可能会用肘部法则来选择K。这个法则的做法就是改变K值,然后每次改变之后我们运行一下算法,得到代价函数J的值,然后画图像:
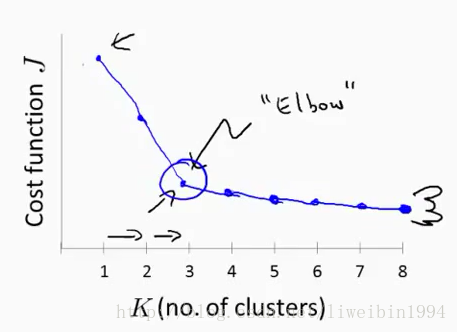
横坐标是K的数量,纵坐标是代价J。经过上面的做法我们可能会得到图中所示的曲线。这条曲线像人的肘部,所以叫肘部法则。在这种模式下(曲线下),随着K的增加,代价函数的值会迅速减小,然后趋于平缓。所以我们一般就会选择拐点对应的K值来作为聚类数。
MATLAB代码
Kmeans原理与实现的更多相关文章
- 1. K-Means原理解析
1. K-Means原理解析 2. K-Means的优化 3. sklearn的K-Means的使用 4. K-Means和K-Means++实现 1. 前言 我们在一开始的时候应该就说过,机器学习按 ...
- 11 K-Means 原理及案例
11 K-Means 原理及案例 非监督学习 unsupervised learning (非监督学习) ,只有特征值,没有目标值 聚类: 主要方法 - k-means (K - 需要分成的类别数) ...
- 机器学习——KMeans聚类,KMeans原理,参数详解
0.聚类 聚类就是对大量的未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,聚类属于无监督的学习方法. 1.内在相似性的度量 聚类是根据数据 ...
- Matalab之模糊KMeans原理
对Kmeans方法相信大家都会不陌生,这是一种广泛被应用的基于划分的聚类算法.首先对它的核心思想做一个简单的介绍: 算法把n个向量xj(1,2…,n)分为c个组Gi(i=1,2,…,c),并求每组的聚 ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- 使用k-means对3D网格模型进行分割
使用k-means对3D网格模型进行分割 由于一些原因,最近在做网格分割的相关工作.网格分割的方法有很多,如Easy mesh cutting.K-means.谱分割.基于SDF的分割等.根据对分割要 ...
- 【机器学习】--Kmeans从初识到应用
一.前述 Kmeans算法一般在数据分析前期使用,选取适当的k,将数据分类后,然后分类研究不同聚类下数据的特点. Kmeans算法是一种无监督的算法. 常用于分组,比如用户偏好. 二.概念及原理 Km ...
- 图像处理中kmeans聚类算法C++实现
Kmeans聚类算法是十分常用的聚类算法,给定聚类的数目N,Kmeans会自动在样本数据中寻找N个质心,从而将样本数据分为N个类别.下面简要介绍Kmeans聚类原理,并附上自己写的Kmeans聚类算法 ...
- 机器学习 之k-means和DBSCAN的区别
目录 1.定义和区别(优缺点对比) 2.kmeans原理 3.DBSCAN原理 1.定义和区别(优缺点对比) 聚类分为:基于划分.层次.密度.图形和模型五大类: 均值聚类k-means是基于划分的聚类 ...
随机推荐
- [LeetCode][Java] Substring with Concatenation of All Words
题目: You are given a string, s, and a list of words, words, that are all of the same length. Find all ...
- SurfaceView绘制录音波形图
本文简单记录由View绘制转为SurfaceView绘制的波形图问题. 上代码: public class VoiceLineView extends View { private final int ...
- Rxjava2.0 链式请求异常处理
使用Rxjava2.0的过程中,难免会遇到链式请求,而链式请求一般都是第一个抛异常,那么后面的请求都是不会走的.现在来讨论一下链式请求的一种异常处理方法.例如: 一个登录-->通过登录返回的to ...
- Android 事件分发
引言 项目中涉及到的触摸事件分发较多,例如:歌词模式下,上下滑动滚动歌词,左右滑动切换歌曲.此时,理解事件分发机制显得尤为重要 , 既要保证下方的ViewPager能接收到,又要确保上层View能响应 ...
- 关于iOS上使用WWW引起的内存泄漏的临时解决方案
原地址:http://www.unity蛮牛.com/thread-16493-1-1.html 目前,在的4.3.3.和4.3.4版本中存在一个iOS平台上的内存泄漏问题,即当使用WWW来下载和加载 ...
- ES6常用对象操作整理
const 简单类型数据常量 // const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址不得改动.对于简单类型的数据(数值.字符串.布尔值),值就保存在变量指向的那个内存地址,因 ...
- ant-design表单处理和常用方法及自定义验证
首先要说一下antdesign这个框架API和demo丰富,而且开发环境提供对应的warning来纠正用户的错误.是一个很好的组件库. 关于表单验证方面是依赖于 async-validator 库. ...
- Android出现“Read-only file system”解决办法
操作设备文件系统上的文件结果遇到"... Read-only file system". 解决办法: 1. 最简单的,adb remount 2. 不行的话,adb shell s ...
- 如何实现 Copying derived entities using only base class pointer
#include <iostream> struct CloneableBase { ; }; template<class Derived> struct Cloneable ...
- 【Windows】免费图片提取文字的方法
今天意外的看到一个可以提取图片中文字的网站,自己试了下,提取效果还不错 网址为: https://zhcn.109876543210.com/ 现在有图片如下 我想从中提取的文字 1.打开网址,上传图 ...