图像处理中kmeans聚类算法C++实现
Kmeans聚类算法是十分常用的聚类算法,给定聚类的数目N,Kmeans会自动在样本数据中寻找N个质心,从而将样本数据分为N个类别。下面简要介绍Kmeans聚类原理,并附上自己写的Kmeans聚类算法实现。
一、Kmeans原理
1. 输入:一组数据data,设定需要聚类的类别数目ClusterCnt,设定迭代次数IterCnt,以及迭代截止精度eps
输出:数据data对应的标签label,每一个数据都会对应一个label(范围0 ~ ClusterCnt-1),表示该数据属于哪一类。
2. 首先,选取初始ClusterCnt个质心位置,选取初始质心位置很重要。一般原则是这ClusterCnt个质心在数值上相互差别越远越好(距离越大越好)。偷懒的做法就是随机选取,或者是选取前面ClusterCnt个数据作为初始质心。但是前提是初始质心数值不能存在重复或者相等的情况。
3. 开始聚类,这是一个迭代过程。先针对每一个数据,计算其与每个质心之间的距离(差别),选取距离最小的对应的质心,将其归为一类(设置为同一个标签值),依次遍历所有数据。这样第一次迭代后,所有数据都有一个标签值。
4. 计算新的质心。每一次迭代完成后,计算每个类别中数据中的均值,将此均值作为新的质心,进行下一轮的迭代。这样每一轮迭代后都会重新计算依次质心。直到满足5中的条件。
5. 每次迭代后,计算每个类别中数值的方差值,然后求出所有类别方差值得均值var,将var作为一个判别准则,当本次var与上次var之间的变化小于eps时,或者迭代次数大于iterCnt时,停止迭代,聚类完成。
6. 输出数据的标签。相同标签值得被kmeans聚为一类,这样所有数据就被聚类为设定的ClusterCnt个类别。
二、图像中的应用
简单的将kmeans算法应用于图像中像素点的分类,每个像素点的RGB值作为输入数据,计算像素点与质心之间的距离,不断迭代,直到所有像素点都有一个标签值。根据标签图像将原图像中同一类别设定相同颜色,不同类别设定不同颜色。可用于图像分割等。
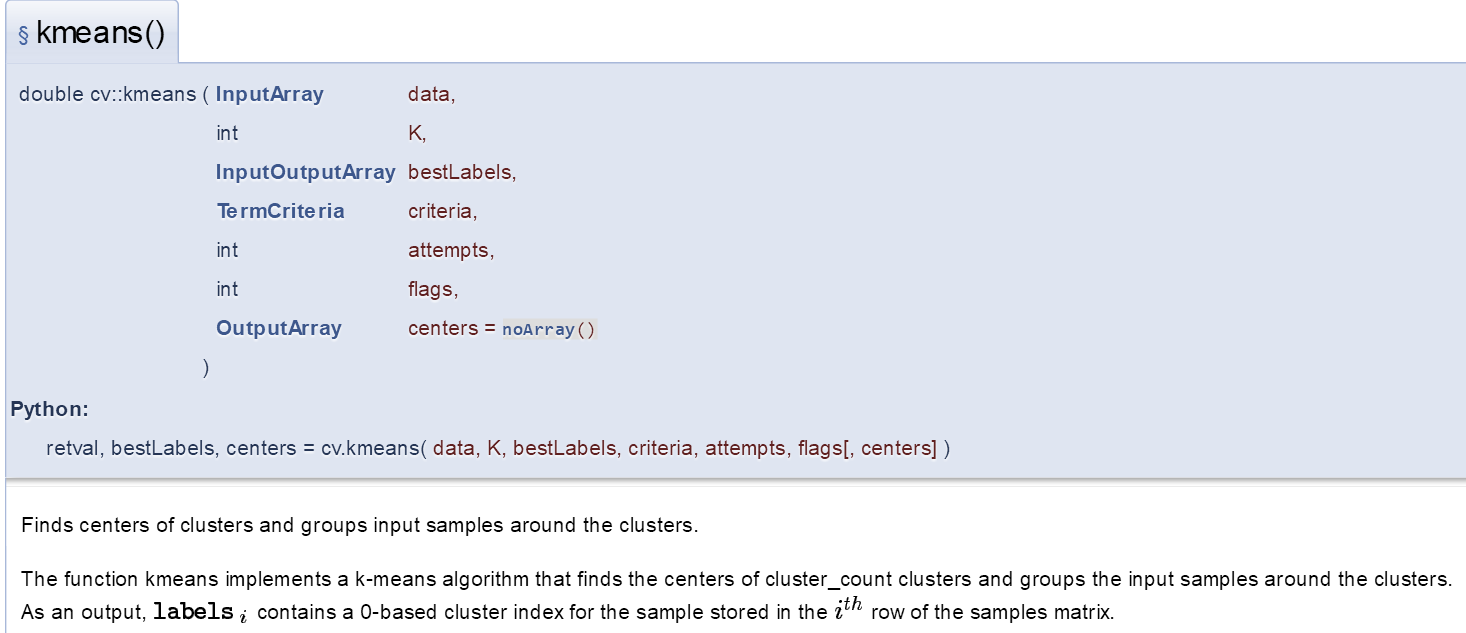
OpenCV中也集成有Kmeans算法的API,如下图,其选取初始质心有三种flag可以设置,随机选取、某种算法选取、用户设定。具体使用方法请参考OpenCV文档。
三、示例
原图 kmeans聚类 (10类)


四、代码
见我的码云code:https://gitee.com/rxdj/myKmeans.git
图像处理中kmeans聚类算法C++实现的更多相关文章
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只 ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- OpenCV图像处理中“投影技术”的使用
本文区分"问题引出"."概念抽象"."算法实现"三个部分由表及里具体讲解OpenCV图像处理中"投影技术" ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
随机推荐
- python 根据字符串内数字排序
当我们使用python给一个由字符串组成的列表排序时,常常会排成这样 [‘10a’, ‘11b’, ‘1c’, ‘20d’, ‘21e’, ‘2f’] 这样的形式 ,然而我们想要 [ ‘1c’,‘2f ...
- 64位版本为什么叫amd64,而不是intel64
64位版本为什么叫amd64,而不是intel64? 首先了解下常见的几个架构: X86是一个指令集,是刚有个人电脑时候的什么8086,286,386的那个兼容的指令集. “x86-64”,有时会 ...
- 达里奥:典型的去杠杆化过程是怎么进行的zz
猛人RayDalio的“三部曲”之三:关于去杠杆化的深入理解 作者系统地阐述了去杆杠化过程并深入探讨去杆杠化的运作机理,对我们理解当前全球乃至中国.即将或者已经面临的去杠杆化过程,应当能够带来一些帮助 ...
- VIP之CSC
Color Space Converter II(CSC) 不同的色彩空间用于不同的设备.如RGB一般用于电脑显示器,YCbCr一般用于数字电视,IP还支持最小和最大的保护带[个人理解,这里的保护 ...
- Maths | 离散K-L变换/ 主成分分析法
目录 1. 概述 2. K-L变换方法和原理推导 2.1. 向量分解 2.2. 向量估计及其误差 2.3. 寻找最小误差对应的正交向量系 3. K-L变换高效率的本质 4. PCA在编.解码应用上的进 ...
- visual studio 2017使用技巧
visual studio 2017使用技巧 批量删除代码中的空白行 Ctrl + H, 查找: ^(?([^\r\n])\s)*\r?$\r?\n 替换: 使用正则表达式 当前文档 常用快捷键 注释 ...
- 第 1 篇 Scrum 冲刺博客
各个成员在 Alpha 阶段认领的任务 姓名 Alpha 阶段认领的任务 徐婉萍 创建服务器.域名,环境搭建查询界面及页面的设计,查询方法的编写 谭燕 支出.收入添加界面及设计,收入.支出的方法编写, ...
- Android开发 - 解决DialogFragment在全屏时View被状态栏遮住的问题
我的上一篇文章:设置DialogFragment全屏显示 可以设置对话框的内容全屏显示,但是存在在某些机型上顶部的View被状态栏遮住的问题.经过测试,发现了一种解决办法,在DialogFragmen ...
- 项目Alpha冲刺(团队5/10)
项目Alpha冲刺(团队5/10) 团队名称: 云打印 作业要求: 项目Alpha冲刺(团队) 作业目标: 完成项目Alpha版本 团队队员 队员学号 队员姓名 个人博客地址 备注 221600412 ...
- 如何正确的使用Ubuntu以及安装常用的渗透工具集.
文章来源i春秋 入坑Ubuntu半年多了 记得一开始学的时候基本一星期重装三四次=-= 尴尬了 觉得自己差不多可以的时候 就吧Windows10干掉了 c盘装Ubuntu 专心学习. 这里主要来 ...