ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
本文进行操作的虚拟机是在伪分布式配置的基础上进行的,具体配置本文不再赘述,请参考本人博文:ubuntu14.04搭建Hadoop2.9.0伪分布式环境
本文主要参考 给力星的博文——Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS,以及《Hadoop应用开发技术详解(作者:刘刚)》
本文主要用3台虚拟机来搭建Hadoop分布式环境,三台虚拟机的拓扑图如下图所示
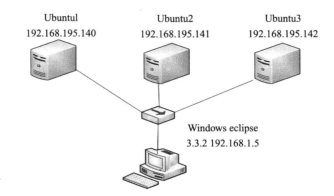
Hadoop集群中每个节点的角色如下表所示
| 主机名 | Hadoop角色 | IP地址 | Hadoop jps命令结果 | Hadoop用户 | Hadoop安装目录 |
| Master |
master slave |
192.168.8.210 |
Jps NameNode SecondaryNameNode ResourceManager JobHistoryServer |
hadoop | /usr/local/hadoop |
| Slave1 | slave | 192.168.8.211 |
Jps NameNode DataNode |
||
| Slave2 | slave | 192.168.8.212 |
Jps NameNode DataNode |
||
| Windows | 开发环境 | 192.168.0.169 | |||
一、网络设置
1. 虚拟机设为桥接模式
网络配置方法见博文:http://blog.csdn.net/zhongyoubing/article/details/71081464
2. 修改主机名
按照上表修改对应主机名,配置文件/etc/hostname
3. 设置IP映射
配置文件/etc/hosts, 所有节点的配置均相同
127.0.0.1 localhost
192.168.8.210 Master
192.168.8.211 Slave1
192.168.8.212 Slave2
4. 测试
重启,测试是否相互 ping 得通
$ ping Master -c
$ ping Slave1 -c
$ ping Slave2 -c
二、SSH无密码登录节点
Master:
$ rm ~/.ssh
$ ssh Master
$ cd ~/.ssh
$ ssh-keygen -t rsa
$ cat ./id_rsa.pub >> ./authorized_keys
$ scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
$ scp ~/.ssh/id_rsa.pub hadoop@Slave2:/home/hadoop/
Slave1 & Slave2:
$ rm ~/.ssh
$ mkdir ~/.ssh
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
$ rm ~/id_rsa.pub
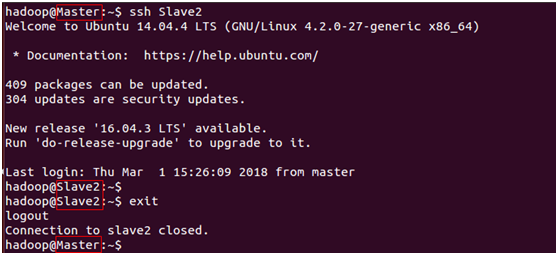
Master端测试:
登录节点Slave2
$ ssh Slave2
退出
$ exit
三、Master节点配置分布式环境
配置文件在目录/usr/local/hadoop/etc/hadoop/下
slaves
Slave1
Slave2
core-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-common/core-default.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Hadoop重要临时文件存放目录</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
<description>一种方案和权限决定文件系统实现的URI</description>
</property>
</configuration>
hdfs-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>复制的块(即数据节点)的数量</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
<description>辅助管理节点HTTP服务器地址和端口</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
<description>DFS管理节点的本地存储路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
<description>DFS数据节点的本地存储路径</description>
</property>
</configuration>
mapred-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>执行MapReduce作业时运行的框架</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
<description>MapReduce jobhistory服务器的进程间通信地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
<description>MapReduce jobhistory服务器的用户界面地址</description>
</property>
</configuration>
yarn-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
<description>ResourceManager的主机名</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager的辅助服务</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>启用日志聚合,默认值为False,即禁用</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${yarn.log.dir}/userlogs</value>
<description>应用程序的本地化的日志目录</description>
</property>
</configuration>
关于日志的查看问题,请见本人另一篇博文:
四、其他节点配置分布式环境
Master:
$ cd /usr/local/
$ sudo rm -r ./hadoop/tmp
$ sudo rm -r ./hadoop/logs
$ tar -zcf ~/hadoop.master.tar.gz ./hadoop
$ scp ~/hadoop.master.tar.gz Slave1:/home/hadoop
$ scp ~/hadoop.master.tar.gz Slave2:/home/hadoop
$ rm ~/hadoop.master.tar.gz
Slave1 & Slave2:
$ sudo rm -r /usr/local/hadoop
$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
$ sudo chown -R hadoop /usr/local/hadoop
$ rm ~/hadoop.master.tar.gz
五、启动Hadoop
Master:
0. 格式化NameNode(更改配置后才执行这一步)
$ hdfs namenode -format
1. 启动NameNode和DataNode守护进程,以及YARN
$ start-all.sh

查看进程
$ jps
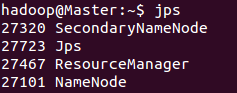
由于在配置文件/usr/local/hadoop/etc/hadoop/slaves中,未添加"Master",所以Master只作为管理节点,不作为数据节点,所以没有进程DataNode和进程NodeManager。
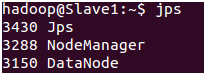
Slave1 & Slave2:
查看进程
$ jps
Master:
2. 启动JobHistoryServer进程
$ mr-jobhistory-daemon.sh start historyserver
查看进程
$ jps
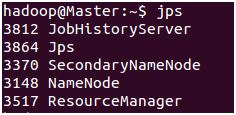
查看DataNode
$ hdfs dfsadmin -report


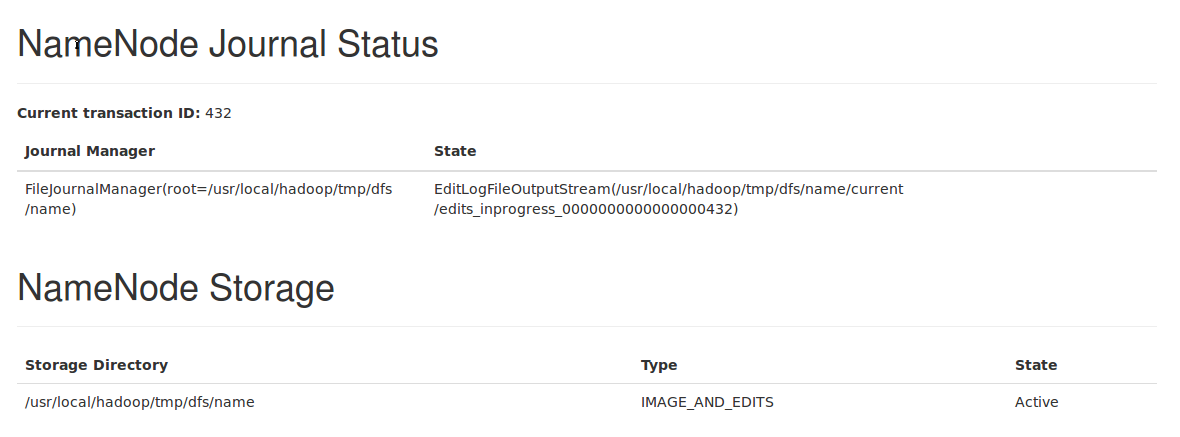
可以访问Web页面http://master:50070/查看DataNode和NameNode的状态,如下图所示:

六、关闭Hadoop
Master:
1. 关闭NameNode和DataNode守护进程,以及YARN
$ stop-all.sh

查看进程
$ jps

Slave1 & Slave2:
查看进程
$ jps

可以看到,在Master端执行stop-all.sh脚本时,将节点的相应进程也关闭了。但是Master端还有一个JobHistoryServer进程未关闭。
Master:
2. 关闭JobHistoryServer进程
$ mr-jobhistory-daemon.sh stop historyserver
查看进程
$ jps

七、分布式实例
1. 创建文件test.txt(目录没有要求)
Hello world
Hello world
Hello world
Hello world
Hello world
2. 在HDFS中创建用户目录
$ hdfs dfs -mkdir -p /user/hadoop
3. 创建input目录
$ hdfs dfs -mkdir input
4. 将本地文件上传到input里
$ hdfs dfs -put ./test.txt input
5. 查看是否上传成功
$ hdfs dfs -ls /user/hadoop/input
6. 操作(统计词频)
$ hdfs dfs -rm -r output #Hadoop运行程序时,输出目录不能存在,否则会提示错误
$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/hadoop/input/test.txt /user/hadoop/output
7. 查看运行结果
$ hdfs dfs -cat output/*

可以访问Web界面http://master:8088/cluster/查看任务进度,在Web界面点击“Tracking UI”这一列的History连接,可以看到任务的运行信息,如下图所示:

8. 将运行结果取回本地
$ rm -r ./output #如果本地存在output目录
$ hdfs dfs -get output ./output
$ cat ./output/*

9. 删除output目录
$ hdfs dfs -rm -r output
$ rm -r ./output
八、更改配置或初始化工作环境
如果要初始化工作环境,或者更改了配置文件,请执行以下步骤:
四 → 五 → 七-2 → 七-3
以上
ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境的更多相关文章
- hadoop-2.6.0集群开发环境配置
hadoop-2.6.0集群开发环境配置 一.环境说明 1.1安装环境说明 本例中,操作系统为CentOS 6.6, JDK版本号为JDK 1.7,Hadoop版本号为Apache Hadoop 2. ...
- CentOS6.4上搭建hadoop-2.4.0集群
公司Commerce Cloud平台上提供申请主机的服务.昨天试了下,申请了3台机器,搭了个hadoop环境.以下是机器的一些配置: emi-centos-6.4-x86_64medium | 6GB ...
- 第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群
安装配置jdk,SSH 一.首先,先搭建三台小集群,虚拟机的话,创建三个 下面为这三台机器分别分配IP地址及相应的角色:集群有个特点,三台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去 ...
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- ubuntu14.04搭建Hadoop2.9.0伪分布式环境
本文主要参考 给力星的博文——Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04 一些准备工作的基本步骤和步骤具体说明本文不再列出,文章中提到的“见参考”均指以上 ...
- 搭建hadoop2.6.0集群环境
一.规划 (一)硬件资源 10.171.29.191 master 10.171.94.155 slave1 10.251.0.197 slave3 (二)基本资料 用户: jediael 目录: ...
- 搭建hadoop2.6.0集群环境 分类: A1_HADOOP 2015-04-20 07:21 459人阅读 评论(0) 收藏
一.规划 (一)硬件资源 10.171.29.191 master 10.171.94.155 slave1 10.251.0.197 slave3 (二)基本资料 用户: jediael 目录: ...
- Hadoop入门(五) Hadoop2.7.5集群分布式环境搭建
本文接上文内容继续: server01 192.168.8.118 jdk.www.fengshen157.com/ hadoop NameNode.DFSZKFailoverController(z ...
随机推荐
- 面试常见的selenium问题
1.如何切换iframe 问题:如果你在一个default content中查找一个在iframe中的元素,那肯定是找不到的.反之你在一个iframe中查找另一个iframe元素或default co ...
- Python获取指定路径下所有文件的绝对路径
需求 给出制定目录(路径),获取该目录下所有文件的绝对路径: 实现 方式一: import os def get_file_path_by_name(file_dir): ''' 获取指定路径下所有文 ...
- gophercloud openstack networking 源码分析
1.network 部分 // Package networks contains functionality for working with Neutron network resources. ...
- mysql与sql server参照对比学习mysql
mysql与sql server参照对比学习mysql 关键词:mysql语法.mysql基础 转自桦仔系列:http://www.cnblogs.com/lyhabc/p/3691555.html ...
- node.js---sails项目开发(4)---配置MongoDB数据库连接
1.安装sails对mongo的依赖 npm install sails-mongo --save 2. 配置mongo连接 修改config/connections.js: module.expor ...
- C# 调用win api获取chrome浏览器中地址
//FindWindow 查找窗口 //FindWindowEx查找子窗口 //EnumWindows列举屏幕上的所有顶层窗口,如果回调函数成功则返回非零,失败则返回零 //GetWindowText ...
- Codeforces Round #303 (Div. 2)
A.Toy Cars 题意:给出n辆玩具车两两碰撞的结果,找出没有翻车过的玩具车. 思路:简单题.遍历即可. #include<iostream> #include<cstdio&g ...
- IE调试页面总结
随着IE版本的升级,IE变的越来越强大,随之带来的问题也是越来越明显,如:如何调试在低版本的浏览器中 的情况 IE9的方法: 出于未知需求,用户在安装了较高版本IE浏览器(IE9)之后,又需要使用低版 ...
- rabbitmq的发布确认和事务
摘要: 介绍confirm的工作机制.使用spring-amqp介绍事务以及发布确认的使用方式.因为事务以及发布确认是针对channel来讲,所以在一个连接中两个channel,一个channel可以 ...
- vue-scroller的使用
一 安装 使用npm 安装 npm install vue-scroller -S 二 引入 https://www.jianshu.com/p/a39f5276ff0b https://www.np ...