MyCat分片集群
数据库集群会产生的问题:
自增ID问题
数据关联查询问题(水平拆分)
数据同步问题
数据库集群 自动增长id产生重复的话,解决: UUID形式 (没有排序 不是自增) 设置数据库步长
其他方案: redis 或者雪花算法
数据库分库分表的策略:
数据库分表分库策略
数据库分表分库原则遵循 垂直拆分与水平拆分
垂直拆分就是根据不同的业务,分为不同的数据库,比如会员数据库、订单数据库、支付数据库等,垂直拆分在大型电商系统中用的非常常见。
优点:
拆分后业务清晰,拆分规则明确,系统之间整合或扩展容易。
缺点:
部分业务表无法join,只能通过接口方式解决,提高了系统复杂度存在分布式事务问题。
数据库分表分库原则遵循 垂直拆分与水平拆分
垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式
该方式提高了系统的稳定性跟负载能力,但是跨库join性能较差。
在数据库分库分表原则中,遵循两个设计理论 垂直拆分 水平拆分
垂直拆分就是根据不同的业务,拆分成不同的数据库,比如会员数据库,订单数据库,支付数据库,消息数据库等。
垂直拆分缺点:
跨数据查询 必须采用接口形式通讯、分布式事务问题
垂直拆分把不容的表拆到不同的数据库中,而水平拆分是把同一个表拆分到不同的数据库中,或者把一张表的数据拆分n多个小表
如果一张表6条数据:
变成三个库 每个库中存放两条数据,一共三张表,三张表的结构是完全相同的。三个库进行均摊存放
在存的时候根据ID取模存放
在查询时候依然根据取模算法进行获取
拆分的好处: 如果数据量大的情况下,就算用索引也就那样。但是进行水平拆分就好了很多

水平分片策略:
MyCat支持10种分片策略
1、求模算法
2、分片枚举
3、范围约定
4、日期指定
5、固定分片hash算法
6、通配取模
7、ASCII码求模通配
8、编程指定
9、字符串拆分hash解析
详细:http://www.mycat.io/document/mycat-definitive-guide.pdf
关于分片枚举:
分片枚举这种规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国的省份区县固定的,这类业务使用这一规则。配置如下
1.案例步骤:
创建数据库userdb_1 、 userdb_2、userdb_3
2.修改partition-hash-int.txt 规则
wuhan=0
shanghai=1
suzhou=2
详细配置请参考文档
根据地区进行分库 湖北数据库、江苏数据库 山东数据库 (三张表)
分片枚举算法就是根据不同的枚举(常量),进行分类存储。
可以使用分片枚举实现根据地区分类存储到不同数据库进行存放
环境搭建:
定义枚举(地区) 每个地区指定数据库存放位置
schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- mycat_testdb 是mycat的逻辑库名称,链接需要用的 -->
<schema name="mycat_testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<!-- 逻辑库里面的表 order_info 并且有三台节点做集群 规则文件是role2 -->
<table name="order_info" dataNode="dn1,dn2,dn3" rule="role2" /> </schema>
<!-- database 是MySQL数据库的库名 三台节点 分别对应真实的数据库 user_dbn -->
<dataNode name="dn1" dataHost="localhost1" database="user_db1" />
<dataNode name="dn2" dataHost="localhost1" database="user_db2" />
<dataNode name="dn3" dataHost="localhost1" database="user_db3" />
<!--
dataNode节点中各属性说明:
name:指定逻辑数据节点名称;
dataHost:指定逻辑数据节点物理主机节点名称;
database:指定物理主机节点上。如果一个节点上有多个库,可使用表达式db$0-99, 表示指定0-99这100个数据库; dataHost 节点中各属性说明:
name:物理主机节点名称;
maxCon:指定物理主机服务最大支持1000个连接;
minCon:指定物理主机服务最小保持10个连接;
writeType:指定写入类型;
0,只在writeHost节点写入;
1,在所有节点都写入。慎重开启,多节点写入顺序为默认写入根据配置顺序,第一个挂掉切换另一个;
dbType:指定数据库类型;
dbDriver:指定数据库驱动;
balance:指定物理主机服务的负载模式。
0,不开启读写分离机制;
1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡;
2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.91.8:3306" user="root" password="root">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.91.9:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
rule.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/"> <tableRule name="role2">
<rule>
< !-- 表示根据name字段进行分片存储的 -->
<columns>name</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<!-- 与上面的hash-int对应 -->
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<!-- 指定枚举文件 -->
<property name="mapFile">partition-hash-int.txt</property>
<!-- 枚举文件非数值类型要写1 -->
<property name="type">1</property>
<!-- 默认存放的位置 在第一个的位置存放 -->
<property name="defaultNode">1</property>
</function> </mycat:rule>
注意在实际应用时候 把rule.xml的注释去除掉
server.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/"> <!-- 读写都可用的用户 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">mycat_testdb</property> <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user> <!-- 只读用户 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">mycat_testdb</property>
<property name="readOnly">true</property>
</user> </mycat:server>
查询端口号被哪个进程占用:
netstat -tunlp | grep 8080
kill -9 666
分片规则:
wuhan=0
shanghai=1
suzhou=2
启动mycat
然后navicat工具连接之:
往mycat表的虚拟表里面写数据:会映射到实际物理数据库的表里面
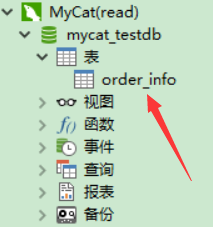
映射的物理数据库:
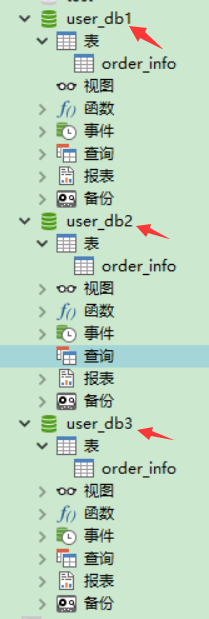
如果分片枚举没有的 根据配置会存储到 db2中!

结构图:
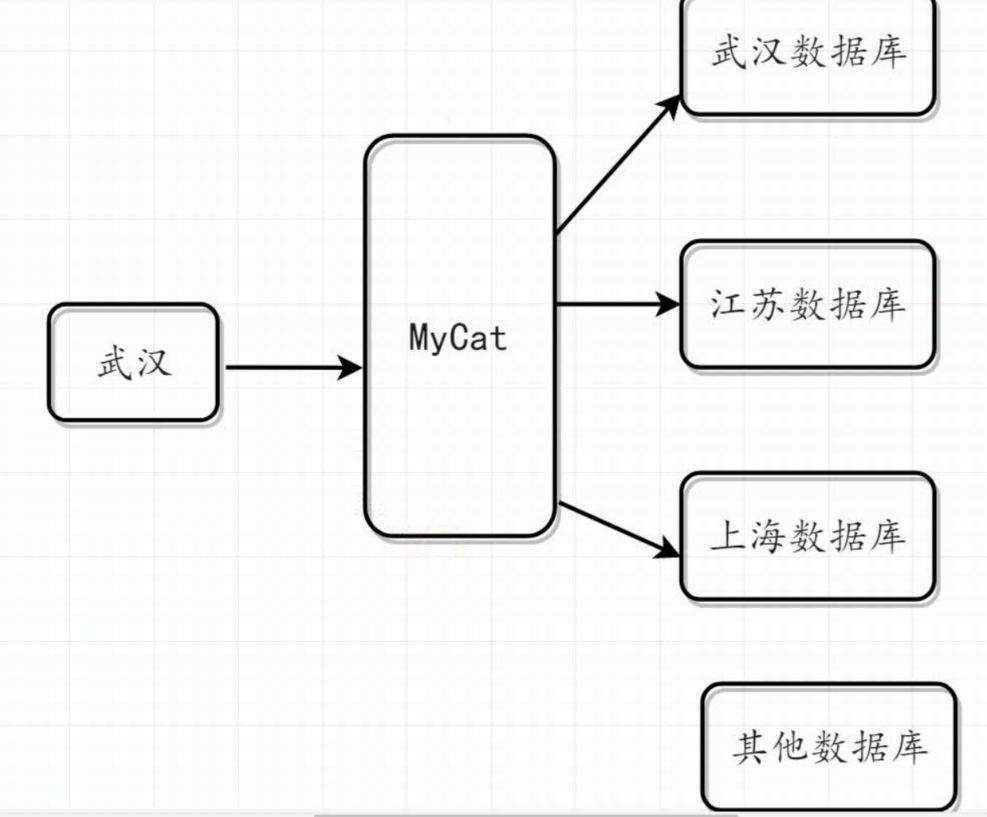
求模算法:根据ID去进行十进制求模运算,运算结果为分区索引
注意:数据库节点分片数量无法更改 (和ES集群非常类似)
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- TESTDB1 是mycat的逻辑库名称,链接需要用的 -->
<schema name="mycat_testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<!-- 分片的算法是role1 -->
<table name="user_info" dataNode="dn1,dn2,dn3" rule="role1"/> </schema>
<!-- database 是MySQL数据库的库名 -->
<dataNode name="dn1" dataHost="localhost1" database="user_db1" />
<dataNode name="dn2" dataHost="localhost1" database="user_db2" />
<dataNode name="dn3" dataHost="localhost1" database="user_db3" />
<!--
dataNode节点中各属性说明:
name:指定逻辑数据节点名称;
dataHost:指定逻辑数据节点物理主机节点名称;
database:指定物理主机节点上。如果一个节点上有多个库,可使用表达式db$0-99, 表示指定0-99这100个数据库; dataHost 节点中各属性说明:
name:物理主机节点名称;
maxCon:指定物理主机服务最大支持1000个连接;
minCon:指定物理主机服务最小保持10个连接;
writeType:指定写入类型;
0,只在writeHost节点写入;
1,在所有节点都写入。慎重开启,多节点写入顺序为默认写入根据配置顺序,第一个挂掉切换另一个;
dbType:指定数据库类型;
dbDriver:指定数据库驱动;
balance:指定物理主机服务的负载模式。
0,不开启读写分离机制;
1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡;
2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.91.8:3306" user="root" password="root">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.91.9:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/"> <tableRule name="role1">
<rule>
<!-- 指定分片规则要玩儿的列名 -->
<columns>id</columns>
<!-- 指定下面的分片算法 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!--指定分片数量,不可以被更改 count数据库的分配数量一共三台 一旦定了就不能修改了! -->
<property name="count">3</property>
</function> </mycat:rule>
server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/"> <!-- 读写都可用的用户 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">mycat_testdb</property> <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user> <!-- 只读用户 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">mycat_testdb</property>
<property name="readOnly">true</property>
</user> </mycat:server>
mycat连接到读的虚拟数据库
然后在真实物理数据库上面创建 user_db1 user_db2 user_db3
在Myca的写权限的虚拟数据库创建表:
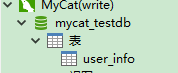
此时的其他的物理数据库里面也会刷新数同样的表
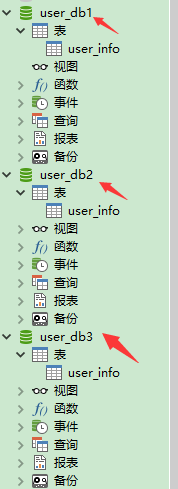
然后在write里面写入数据
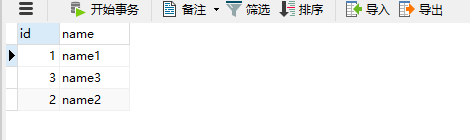
会根据ID取模,分片到不同的物理数据库里面
MyCat分片集群的更多相关文章
- MongoDB 搭建分片集群
在MongoDB(版本 3.2.9)中,分片是指将collection分散存储到不同的Server中,每个Server只存储collection的一部分,服务分片的所有服务器组成分片集群.分片集群(S ...
- MongoDB之分片集群与复制集
分片集群 1.1.概念 分片集群是将数据存储在多台机器上的操作,主要由查询路由mongos.分片.配置服务器组成. ●查询路由根据配置服务器上的元数据将请求分发到相应的分片上,本身不存储集群的元数据, ...
- mongoDB研究笔记:分片集群的工作机制
上面的(http://www.cnblogs.com/guoyuanwei/p/3565088.html)介绍了部署了一个默认的分片集群,对mongoDB的分片集群有了大概的认识,到目前为止我们还没有 ...
- mongoDB研究笔记:分片集群部署
前面几篇文章的分析复制集解决了数据库的备份与自动故障转移,但是围绕数据库的业务中当前还有两个方面的问题变得越来越重要.一是海量数据如何存储?二是如何高效的读写海量数据?尽管复制集也可以实现读写分析,如 ...
- MongoDB分片集群还原
从mongodb 3.0开始,mongorestore还原的时候,需要一个运行着的实例.早期的版本没有这个要求. 1.为每个分片部署一个复制集 (1)复制集中的每个成员启动一个mongod mongo ...
- 【MongoDB】在windows平台下mongodb的分片集群(五)
本篇接着上面的四篇继续讲述在window平台下mongodb的分片集群搭建. 在分片集群中也照样能够创建索引,创建索引的方式与在单独数据库中创建索引的方式一样.因此这不再多说.本篇主要聚焦在分片键的选 ...
- 【MongoDB】在windows平台下搭建mongodb的分片集群(二)
在上一片博客中我们讲了Mongodb数据库中分片集群的主要原理. 在本篇博客中我们主要讲描写叙述分片集群的搭建过程.配置分片集群主要有两个步骤.第一启动全部须要的mongod和mongos进程. 第二 ...
- MongoDB之分片集群(Sharding)
MongoDB之分片集群(Sharding) 一.基本概念 分片(sharding)是一个通过多台机器分配数据的方法.MongoDB使用分片支持大数据集和高吞吐量的操作.大数据集和高吞吐量的数据库系统 ...
- MongoDB 分片集群搭建
一.概述 分片是一种在多台机器上分配数据的方法.MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作.有两种解决系统增长的方法:垂直扩展和水平扩展. 垂直扩展涉及增加单个服务器的容量,例如使用 ...
随机推荐
- iOS-本地沙盒路径
沙盒几个路径: 沙盒里的文件夹包括Documents.Library.tmp.这三个文件夹的作用请点击这里.接下来我们来讲解如何获取Documents.Library.tmp的路径. 获取沙盒根目录 ...
- [转]廖雪峰Git教程总结
- Linux ping不通百度的解决方法
今天在学习DNS的时候遇到了一个问题,我的虚拟机能够ping通ip地址,却ping不通www.baidu.com www.qq.com等域名,先是出现了以下报错: 折腾了几个小时终于找到解决办法 1. ...
- 剩余参数(rest arguments) Mixin
Mixin – Pug 中文文档 https://pug.bootcss.com/language/mixins.html 混入 Mixin 混入是一种允许您在 Pug 中重复使用一整个代码块的方法. ...
- gerrit添加appkey以及简单添加分支
最近团队开放用上gerrit版本项目管理工具,简单说一下appkey配置过程 首先是拿到gerrit分配的账户密码.然后进入到首页,假如是新搭建的应该是没有信息,我这里有一些提交的信息,然后找到右上角 ...
- 第08章—整合Spring Data JPA
spring boot 系列学习记录:http://www.cnblogs.com/jinxiaohang/p/8111057.html 码云源码地址:https://gitee.com/jinxia ...
- js中window.open的参数及注意
IE9下使用window.open时需要注意name参数值不能有"-"出现,否则会出现脚本错误,IE9以及版本测试没有问题 window.open(URL,name,specs ...
- 从SNE到t-SNE再到LargeVis
http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/
- Q35+uefi or bios+legacy // PCI | PCIE
1:首先统一可扩展固件接口(UEFI)是一种规范定义操作系统和平台固件之间的软件接口. UEFI旨在替代基本输入/输出系统(BIOS)固件接口.(legacy) 硬件平台厂商越来越多地采用UEFI管理 ...
- 简明python教程五----数据结构
python中有三种内建的数据结构:列表.元组和字典 list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个序列的项目.在python中,每个项目之间用逗号分隔. 列表中的项目应该包括在方 ...