爬虫框架YayCrawler
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCrawler,欢迎大家关注和反馈。
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们知道目前爬虫框架很多,有简单的,也有复杂的,有轻量型的,也有重量型的。您也许会问:你这个爬虫框架的优势在哪里呢?额,这个是一个很重要的问题!在这个开篇中,我先简单的介绍一下我这个爬虫框架的特点,后面的章幅会详细介绍并讲解它的实现,一图胜千言:
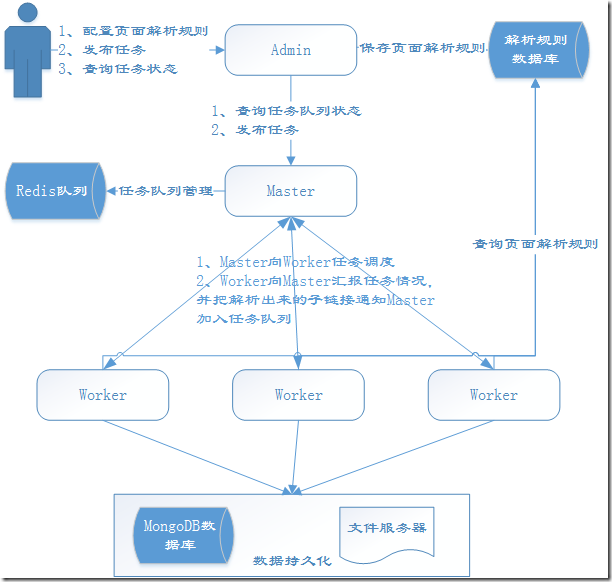
1、分布式:YayCrawler就是一个大哥(Master)多个小弟(Worker)的架构(这种结构才是宇宙的真理),当然大哥还有一个小秘(Admin)和外界交往。
2、通用性:我们很多时候需要爬取不同网站的数据,各个网站的结构和内容都有很大的差别,基本上大部分人都是遇到一个网站写一份代码,没法做到工具的复用。YayCrawler就是想改变这种情况,把不同的部分抽象出来,用规则来指导爬虫做事。也就是说用户可以在界面上配置如何抓取某个页面的数据的规则,等爬虫在爬取这个页面的时候就会用这个事先配置好的规则来解析数据,然后把数据持久化。
3、可扩展的任务队列:任务队列由Redis实现,根据任务的状态有四种不同的任务队列:初始、执行中、成功、失败。您也可以扩展不同的任务调度算法,默认是公平调度。
4、可定义持久化方式:爬取结果中,属性数据默认持久化到MongoDB,图片会被下载到文件服务器,当然您可以扩展更多的存储方式。
5、稳定和容错:任何一个失败的爬虫任务都会重试和记录,只有任务真正成功了才会被移到成功队列,失败会有失败的原因描述。
6、反监控组件:网站为了防止爬虫也是煞费苦心,想了一系列的监控手段来反爬虫。作为对立面,我们自然也要有反监控的手段来保障我们的爬虫任务,目前主要考虑的因素有:cookie失效(需要登陆)、刷验证码、封IP(自动换代理)。
7、可以对任务设置定时刷新,比如隔一天更新某个网站的数据。
……
上面说了一大堆优点的目的只有一个:希望您能有兴趣继续看下去,哈哈。
言归正传,本文作为开篇,只是一个总览,现在我们来整理一下后续文章的结构安排:
- 开源通用爬虫框架YayCrawler-框架的运行机制
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
- 开源通用爬虫框架YayCrawler-任务队列详解
- 开源通用爬虫框架YayCrawler-页面下载器详解
- 开源通用爬虫框架YayCrawler-规则解析器详解
- 开源通用爬虫框架YayCrawler-数据持久化详解
- 开源通用爬虫框架YayCrawler-反监控组件详解
- 开源通用爬虫框架YayCrawler-案例演示
- 开源通用爬虫框架YayCrawler-待完善的功能
爬虫框架YayCrawler的更多相关文章
- 开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品--YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCraw ...
- 爬虫框架--webmagic
官方有详细的使用文档:http://webmagic.io/docs/zh/ 简介:这只是个java爬虫框架,具体使用需要个人去定制,没有图片验证,不能获取js渲染的网页,但简单易用,可以通过xpat ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- 使用Scrapy爬虫框架简单爬取图片并保存本地(妹子图)
初学Scrapy,实现爬取网络图片并保存本地功能 一.先看最终效果 保存在F:\pics文件夹下 二.安装scrapy 1.python的安装就不说了,我用的python2.7,执行命令pip ins ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 再次分享 pyspider 爬虫框架 - V2EX
再次分享 pyspider 爬虫框架 - V2EX block
- Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs)
Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs) Cola:一个分布式爬虫框架 发布时间:2013-06-17 14:58:27, 关注:+2034, 赞美: ...
随机推荐
- Python 变量有效范围
- 解决gradle:download特别慢的问题
使用AndroidStudio 2.2.2 新增加了一个dependencies,需要下载jar包,此时就会卡在 gradle:download https://….. 这个状态中. 原因就是因为我们 ...
- AIX和Linux中wtmp的不同处理方式
wtmp 记录用户登录和退出事件.它和utmp日志文件相似,但它随着登陆次数的增加,它会变的越来越大,有些系统的ftp访问也在这个文件里记录,同时它也记录正常的系统退出时间,可以用ac和last命令访 ...
- joomla安装插件报错:上传文件到服务器发生了一个错误。 过小的PHP文件上传尺寸
在安装joomla的AKeeba插件的时候报错如下:上传文件到服务器发生了一个错误. 过小的PHP文件上传尺寸.解决方法是修改php.ini文件,打开文件后搜索upload_max_filesize! ...
- Android实现摇晃手机的监听
摘自:http://blog.csdn.net/xwren362922604/article/details/8515343 监听摇晃手机的类: /** * @author renxinwei ...
- sicily 1099 Packing Passengers
/**** 题意: 求x,y 满足 x*pa+y*pb=n 同时使得 p = x*ca+y*cb的值最小,若有多种可能,则选择最大x值的组合** 分析: x*pa+y*pb=n 可以用 线性同 ...
- inline-block及解决空白间距
參考:http://www.jb51.net/css/76707.html http://www.webhek.com/remove-whitespace-inline-block/ inline-b ...
- Django之Cookie与Session
一.cookie 1.cookie使用 def cookie(request): print(request.COOKIES) # 获取所有的COOKIES obj = render(request, ...
- phoneGap开发环境搭建(android)
1. 首先安装nodejs (http://nodejs.org/) 2. 然后在命令行输入 npm 回车 假设出现下图: 则表示成功安装 3. 安装 npm install -g cordov ...
- 使用代码自定义UIView注意一二三
文/CoderAO(简书作者)原文链接:http://www.jianshu.com/p/68b383b129f9著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”. 当一撮样式一样的视图在 ...