开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCrawler,欢迎大家关注和反馈。
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们知道目前爬虫框架很多,有简单的,也有复杂的,有轻量型的,也有重量型的。您也许会问:你这个爬虫框架的优势在哪里呢?额,这个是一个很重要的问题!在这个开篇中,我先简单的介绍一下我这个爬虫框架的特点,后面的章幅会详细介绍并讲解它的实现,一图胜千言:
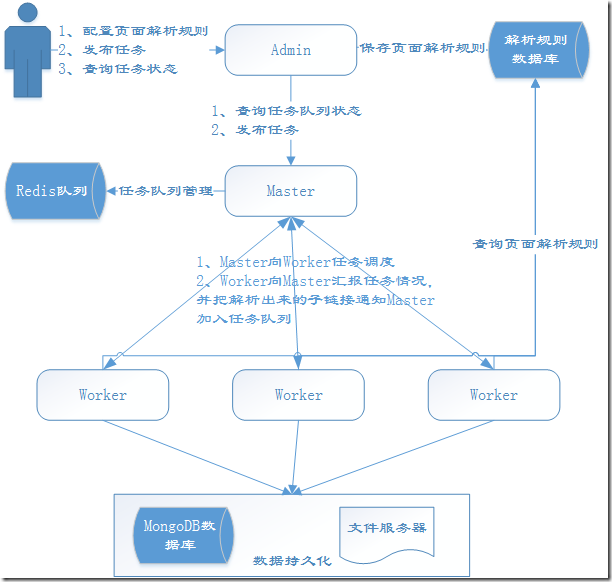
1、分布式:YayCrawler就是一个大哥(Master)多个小弟(Worker)的架构(这种结构才是宇宙的真理),当然大哥还有一个小秘(Admin)和外界交往。
2、通用性:我们很多时候需要爬取不同网站的数据,各个网站的结构和内容都有很大的差别,基本上大部分人都是遇到一个网站写一份代码,没法做到工具的复用。YayCrawler就是想改变这种情况,把不同的部分抽象出来,用规则来指导爬虫做事。也就是说用户可以在界面上配置如何抓取某个页面的数据的规则,等爬虫在爬取这个页面的时候就会用这个事先配置好的规则来解析数据,然后把数据持久化。
3、可扩展的任务队列:任务队列由Redis实现,根据任务的状态有四种不同的任务队列:初始、执行中、成功、失败。您也可以扩展不同的任务调度算法,默认是公平调度。
4、可定义持久化方式:爬取结果中,属性数据默认持久化到MongoDB,图片会被下载到文件服务器,当然您可以扩展更多的存储方式。
5、稳定和容错:任何一个失败的爬虫任务都会重试和记录,只有任务真正成功了才会被移到成功队列,失败会有失败的原因描述。
6、反监控组件:网站为了防止爬虫也是煞费苦心,想了一系列的监控手段来反爬虫。作为对立面,我们自然也要有反监控的手段来保障我们的爬虫任务,目前主要考虑的因素有:cookie失效(需要登陆)、刷验证码、封IP(自动换代理)。
7、可以对任务设置定时刷新,比如隔一天更新某个网站的数据。
……
上面说了一大堆优点的目的只有一个:希望您能有兴趣继续看下去,哈哈。
言归正传,本文作为开篇,只是一个总览,现在我们来整理一下后续文章的结构安排:
- 开源通用爬虫框架YayCrawler-运行与调试
- 开源通用爬虫框架YayCrawler-框架的运行机制
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
- 开源通用爬虫框架YayCrawler-任务队列详解
- 开源通用爬虫框架YayCrawler-页面下载器详解
- 开源通用爬虫框架YayCrawler-规则解析器详解
- 开源通用爬虫框架YayCrawler-数据持久化详解
- 开源通用爬虫框架YayCrawler-反监控组件详解
- 开源通用爬虫框架YayCrawler-案例演示
- 开源通用爬虫框架YayCrawler-待完善的功能
开源通用爬虫框架YayCrawler-开篇的更多相关文章
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一.如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同.页面的结构不 ...
- 开源通用爬虫框架YayCrawler-运行与调试
本节我将向大家介绍如何运行与调试YayCrawler.该框架是采用SpringBoot开发的,所以可以通过java –jar xxxx.jar的方式运行,也可以部署在tomcat等容器中运行. 首先 ...
- 开源通用爬虫框架YayCrawler-框架的运行机制
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图: 首先各个组件的启动顺序建议是Master.Worker.Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启 ...
- 爬虫框架YayCrawler
爬虫框架YayCrawler 各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liush ...
- 一个简单的开源PHP爬虫框架『Phpfetcher』
这篇文章首发在吹水小镇:http://blog.reetsee.com/archives/366 要在手机或者电脑看到更好的图片或代码欢迎到博文原地址.也欢迎到博文原地址批评指正. 转载请注明: 吹水 ...
- 基于 Java 的开源网络爬虫框架 WebCollector
原文:https://www.oschina.net/p/webcollector
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架
gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架 gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架 Google Guava官方教程(中文版 ...
随机推荐
- linux命令总结之tr命令
什么是tr命令?tr,translate的简写,translate的翻译: [trænsˈleit] vi. 翻译, 能被译出 vt. 翻译, 解释, 转化, 转变为, 调动 在这里用到的意思是转化, ...
- Memcached服务加固方案
配置访问控制.建议用户不要将服务发布到互联网上而被黑客利用,可以通过ECS安全组规则或IPtables配置访问控制规则.例如,在Linux环境中运行命令,在IPtables中添加此规则只允许192.1 ...
- PHP开发小技巧①①—php实现手机号码显示部分
从个人信息保护性的角度来讲,我们在开发过程中总会想办法去保护用户的一些个人信息.就如本篇博文所讲,我们有时会将用户的手机号码只显示出部分,这是很多网站都有做的功能.这个功能实现起来也是特别的简单,只需 ...
- k8s部署rocketmq 双主
由于apache 官网的 docker image 是单点,要实现集群方式部署. rocketmq 分为 nameserver 和 broker , 对于之间调用频繁的服务,会增加网络压力, 所以 考 ...
- Linux上安装Oracle的辛酸史
下个礼拜就要开始学习Oracle了,得嘞先在我的CentOS7上装一个(貌似听说Oracle装在Oracle Linux能得到更好的性能,不过懒得下Oracle Linux镜像,在CentOS7上装个 ...
- Google的Flutter工具允许开发者开发跨平台应用
与大多数应用程序开发人员交谈,他们会告诉你,与iOS相比,制作Android应用程序要困难得多,也更复杂,也不那么有趣.实际上,如果你要求报价,这两种软件都将单独定价,因为它们都需要单独的开发时间和团 ...
- mysql编码问题:
在my.ini文件改为: [client]default-character-set = utf8port=3306 [mysql] default-character-set=utf8 [mysql ...
- 【Atcoder ARC060F】最良表現 / Best Representation
Atcoder ARC060 F 题意:给一个串,求将其分成最少的没有循环节的串的种数. 思路:先求KMP的\(fail\)数组.然后发现最少的串数只有三种可能:\(1\).\(2\).\(n\). ...
- 在模拟器上运行Android项目时报错:DELETE_FAILED_INTERNAL_ERROR Error while Installing APKs
今天在Android Studio自带的模拟器上运行项目的时候,出现如下所示Error:当点击ok后,发现模拟器不能运行程序. 解决办法: 更改Android Studio中的设置: File---& ...
- (转)tomcat 修改默认访问项目名称和项目发布路径
1.项目发布路径 <Host name="localhost" appBase="webapps" unpackWARs="true" ...