MR案例:倒排索引
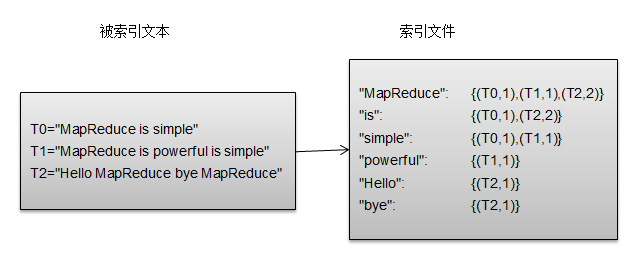
1.map阶段:将单词和URI组成Key值(如“MapReduce :1.txt”),将词频作为value。
利用MR框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
Class Map<Longwritable, Text, Text, Longwritable>{
method map(){
//获取输入分片对应的文件名
String fileName=((FileSplit)context.getInputSplit()).getPath().getName();
for(String word : value.split()){
//输出:<key,value>---<"MapReduce:1.txt",1>
context.write(new Text(word+":"+fileName), new Longwritable(1))
}
}
}
2.Combiner阶段:将key值相同的value值累加,得到一个单词在文档中的词频。
如果直接将Map的输出作为Reduce的输入,当前key值(由单词、URI组成)无法保证相同的word会分发到同一个Reduce处理,所以必须修改key值和value值。将单词作为key值,URI和词频作为value值,可以利用MR框架默认的HashPartitioner类完成分区过程,将相同单词的所有记录发送给同一个Reducer处理。
Class Combine<Text, Longwritable, Text, Text>{
method reduce(){
for(Long long : v2s){
//词频求和
sum += Long.parseLong(long.toString());
}
//输出:<key,value>----<"Mapreduce","0.txt:2">
context.write(new Text(word), new Text(fileName+":"+sum));
}
}
3.reduce阶段:将相同key值的value值组合成倒排索引文件所需的格式即可。
Class Reduce<Text, Longwritable, Text, Text>{
method reduce(){
String valueList = new String();
//输入:<"MapReduce",list("0.txt:1","1.txt:1","2.txt:1")>
for(Text text : v2s){
valueList += text.toString()+";";
}
//输出:<"MapReduce","0.txt:1,1.txt:1,2.txt:1">
context.write(key, new Text(valueList));
}
}
注意事项:本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大,要保证每个文件对应一个 split。否则,由于 Reduce 过程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。详见MR案例:倒排索引 && MultipleInputs
解决方案:
- 覆写 InputFormat 类将每个输入文件分为一个 split,避免上述情况。
- 执行两次 MR 任务,第一次 MR 用于统计词频,第二次 MR 用于生成倒排索引。
- 可以利用复合键值对等实现包含更多信息的倒排索引。
MR案例:倒排索引的更多相关文章
- MR案例:Reduce-Join
问题描述:两种类型输入文件:address(地址)和company(公司)进行一对多的关联查询,得到地址名(例如:Beijing)与公司名(例如:Beijing JD.Beijing Red Star ...
- MR案例:小文件处理方案
HDFS被设计来存储大文件,而有时候会有大量的小文件生成,造成NameNode资源的浪费,同时也影响MapReduce的处理效率.有哪些方案可以合并这些小文件,或者提高处理小文件的效率呢? 1). 所 ...
- MR案例:倒排索引 && MultipleInputs
本案例采用 MultipleInputs类 实现多路径输入的倒排索引.解读:MR多路径输入 package test0820; import java.io.IOException; import j ...
- MR案例:CombineFileInputFormat
CombineFileInputFormat是一个抽象类.Hadoop提供了两个实现类CombineTextInputFormat和CombineSequenceFileInputFormat. 此案 ...
- MR案例:输出/输入SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File).在SequenceFile文件中,每一个key-value对被看做是一条记 ...
- MR案例:分区和排序
现有一学生成绩数据,格式如下:<学号,姓名,学院,成绩> //<id, name, institute, grade>. 需求描述:查询成绩大于等于60分的学生数据,按学院分 ...
- MR案例:链式ChainMapper
类似于Linux管道重定向机制,前一个Map的输出直接作为下一个Map的输入,形成一个流水线.设想这样一个场景:在Map阶段,数据经过mapper01和mapper02处理:在Reduce阶段,数据经 ...
- MR案例:定制InputFormat
数据输入格式 InputFormat类用于描述MR作业的输入规范,主要功能:输入规范检查(比如输入文件目录的检查).对数据文件进行输入切分和从输入分块中将数据记录逐一读取出来.并转化为Map的输入键值 ...
- MR案例:基站相关01
字段解释: product_no:用户手机号: lac_id:用户所在基站: start_time:用户在此基站的开始时间: staytime:用户在此基站的逗留时间. product_no lac_ ...
随机推荐
- Vue.js_getter and setter
computed 计算属性: 1.get 读取 <div id="test2"> <input type="text" v-model=&qu ...
- _init_() got an unexpected keyword argument ‘shape’
按照<TensorFlow:实战Google深度学习框架>一书学习的tensorflow,书中使用的是0.9.0版本,而我安装的是1.11.0 如果按照书上的例子来,因为这本书使用tens ...
- About LabView
Recently I am running an experiment. Because the lab has only NI devices, I have to learn to use the ...
- <2014 10 01> 数学基础 Wikipedia
数学基础 数学上,数学基础一词有时候用于数学的特定领域,例如数理逻辑,公理化集合论,证明论,模型论,和递归论.但是寻求数学的基础也是数学哲学的中心问题:在什么终极基础上命题可以称为真? 目前占统治地位 ...
- python 中几个层次的中文编码.md
转自:[http://swj.me/] 介绍 一直不太喜欢使用命令行,所以去年年底的技术创新中,使用TkInter来开发小工具.结果花费了大量的时间来学习TkInter ui的使用. 最近想整理该工具 ...
- PHP webservice 的初接触
webservice 现在是开始流行了,很多业务开启了这个功能.去年接触的一个金融类的项目有类似功能调用.当时没放心思研究,最两天试着接触了下,还真不错的.起步其实挺简单. 服务端的代码 server ...
- MobileNet
MobileNet (Efficient Convolutional Neural Networks for Mobile Vision Applications)--Google CVPR-2017 ...
- 禁止Centos系统You have new mail in /var/spool/mail/root提示
禁止Centos系统You have new mail in /var/spool/mail/root提示 https://blog.csdn.net/oyym_mv/article/details/ ...
- Java集合—List(转载)
本篇文章将集中介绍了List集合相比Collection接口增加的一些重要功能以及List集合的两个重要子类ArrayList及LinkedList. 一.List集合 List作为Collectio ...
- 使用uiautomatorviewer获取元素
1.进入以下目录,Androidsdk-tools,双击uiautomatorviewer.bat,然后弹出UI Automator Viewer窗口,按截图操作, 获取当前页面,然后点击相应的元素, ...