HDFS存储流程及HA
HDFS架构
- 主从(Master/Slaves)架构
- 由一个NameNode和一些DataNode组成
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block的读写
- DataNode与NameNode维持心跳,并汇报自己持有的block信息
- Client和NameNode交互文件元数据和DataNode交互文件block数据
角色功能
NameNode
- 完全基于内存存储文件元数据、目录结构、文件block的映射
- 需要持久化方案保证数据可靠性
- 提供副本放置策略
DataNode
- 基于本地磁盘存储block(文件形式)
- 并保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
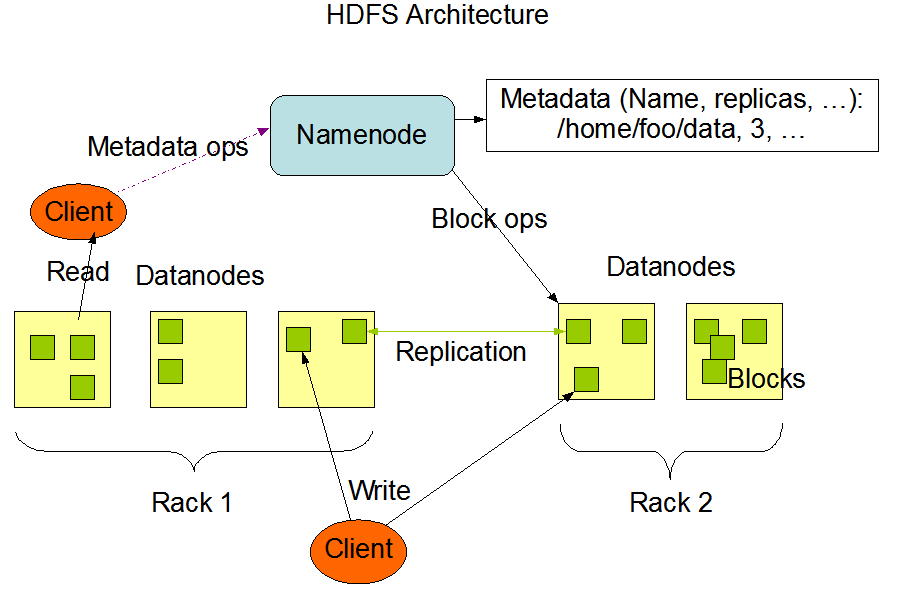
文件存储
- 文件按线性byte切割成block,具有offset,id
- 一个文件除最后一个block,其余block大小一致
- block的大小依据硬件的I/O特性调整
- block被分散存放在集群的节点中,具有location
- Block具有副本(replication),没有主从概念,副本不能出现在同一个节点(注:副本是满足可靠性和性能的关键)
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入多次读取,不支持修改,支持追加数据
元数据持久化(异常恢复处理)
- 任何对文件系统元数据产生修改的操作,Namenode都会使用EditLog的事务日志记录下来
- 使用FsImage存储内存所有的元数据状态
- 使用本地磁盘保存EditLog和FsImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并有体积膨胀风险
- FsImage具有恢复速度快,体积与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FsImage+EditLog整合的方案
- 滚动将增量的EditLog更新到FsImage,以保证更近时点的FsImage和更小的EditLog体积
安全模式
1,HDFS搭建时会格式化,格式化操作会产生一个空的FsImage,Namenode启动后会进入一个称为安全模式的特殊状态,当Namenode启动时,它从硬盘中读取Editlog和FsImage将所有Editlog中的事务作用在内存中的FsImage上并将这个新版本的FsImage从内存中保存到本地磁盘上,然后删除旧的Editlog
2,安全模式下的Namenode是不会进行数据块的复制,Namenode从所有的 Datanode接收心跳信号和块状态报告每当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全(safely replicated)的,在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的30秒等待时间),Namenode将退出安全模式状态接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他Datanode上
Block的副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在于第一个副本不同 机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。
- 更多副本:随机节点

HDFS写流程
- Client和NN连接创建文件元数据
- NN判定元数据是否有效,NN处发副本放置策略,返回一个有序的DN列表
- Client和DN建立Pipeline连接
- Client将块切分成packet(64KB),并使用chunk(512B)+chucksum(4B)填充
- Client将packet放入发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存并发送给第二个DN,第二个DN收到packet后本地保存并发送给第三个DN,这一个过程中,上游节点同时发送下一个packet
- 当block传输完成,DN们各自向NN汇报,同时client继续传输下一个block
注:client的传输和block的汇报是并行的
HDFS读流程
- 如果在读取程序的同一个机架上有一个副本,那么就读取该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
- 注:为降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本
例:下载文件
Client和NN交互文件元数据获取fileBlockLocation,NN会按距离策略排序返回,Client尝试下载block并校验数据完整性
Datanode可靠性:
DN失效
DN会定时发送心跳到NN,一段时间内NN没有收到DN的心跳消息,则认为其失效。此时NN就会将该节点的数据(从该节点的复制节点中获取)复制到另外的DN中
DN数据毁坏
无论是写入时还是硬盘本身的问题,只要数据有问题(读取时通过校验码来检测),都可以通过其他的复制节点读取,同时还会再复制一份到健康的节点中
非HA问题:
单点故障,集群整体不可用
压力过大,内存受限
HDFS解决方案:
1,单点故障:
高可用方案:HA(High Available)
多个NameNode,一主多备,主备切换(注:Hadoop3.x 支持NN>2台,官方建议2台备机,减少多台NN之间网络交互,保证其高效)
2,压力过大,内存受限:
联帮机制: Federation(元数据分片,分布式存储)
多个NN,管理不同的元数据
HA解决方案:
多台NN主备模式,Active和Standby状态,Active对外提供服务
分布式数据存储:增加journalnode角色(>3台),负责同步NameNode的editlog数据(保证最终一致性,注:DN同时向多台NN汇报block清单)
主备切换:增加zkfc角色(与NN同台),通过zookeeper集群协调NN的主从选举和切换(事件回调机制)
HDFS存储流程及HA的更多相关文章
- Linux -- 之HDFS实现自动切换HA(全新HDFS)
Linux -- 之HDFS实现自动切换HA(全新HDFS) JDK规划 1.7及以上 https://blog.csdn.net/meiLin_Ya/article/details/8065094 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- HDFS读写流程(转载)
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现.特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性 ...
- 【漫画解读】HDFS存储原理(转载)
以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用HDFS API操作文件;与NN交互获取文件元数 ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- 【转】【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用 ...
- 【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理,非常适合Hadoop/HDFS初学者理解. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下 ...
- HDFS 和 YARN 的 HA 故障切换【转】
来源:https://blog.csdn.net/u011414200/article/details/50336735 一 非 HDFS HA 集群转换成 HA 集群二 HDFS 的 HA 自动切换 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- Hadoop之HDFS读写流程
hadoophdfs 1. HDFS写流程 2. HDFS写流程 1. HDFS写流程 HDFS写流程 副本存放策略: 上传的数据块后,触发一个新的线程,进行存放. 第一个副本:与client最近的机 ...
随机推荐
- Spring IOC官方文档学习笔记(二)之Bean概述
1.Bean概述 (1) Spring IoC容器管理一个或多个bean,这些bean是根据我们所提供的配置元数据来创建的,在容器内部,BeanDefinition对象就代表了bean的配置元数据,它 ...
- go语言的grpc环境安装
本文直接用安装包的方式安装. 源码编译安装参考:https://www.cnblogs.com/abc36725612/p/14288333.html 环境 golang的docker image d ...
- NSSCTF_HUBUCTF的web部分题解
checkin 题目: 主要是php弱比较和序列化知识点考察 <?php $username = "this_is_secret"; $password = "th ...
- DevExpress 的LayoutControl控件导致资源无法释放的问题处理
现象记录 前段时间同事发现我们的软件在加载指定的插件界面后,关闭后插件的界面资源不能释放, 资源管理器中不管内存,还是GDI对象等相关资源都不会下降. 问题代码 问题的代码大概如下. public v ...
- flutter flutter_screenutil Looking up a deactivated widget's ancestor is unsafe.
先强调一下,很多问题可以使用reStart更新试一下下!!!!! 使用flutter_screenutil 报错 Looking up a deactivated widget's ancestor ...
- vue打包---放到服务器下(一个服务器多个项目需要配置路径),以及哈希模式和历史模式的不同配置方法
哈希模式,好用,不需要服务器配合分配路径指向,自己单机就可以打开了 接下来上代码截图 接下来开始截图 历史模式 历史模式需要后端支持 打包后自己直接点击是打不开的 截图如下
- FLASH-CH32F203替换CH32F103 FLASH快速编程移植说明
因CH32F203 相对于CH32F103 flash操作的快速编程模式由单次128字节编程变成了单次256字节编程,该文档说明主要目的是为了方便客户在原先CH32F103工程的基础上实现flash ...
- MyBatis的使用七(处理表与表之间的关系)
本文主要讲述mybatis的处理表与表之间的关系 一. 介绍t_emp和t_dept表 1. t_emp表结构 2. t_dept表结构 二. 数据表的关系 1. 阐明关系 一个部门可以有多个员工,但 ...
- 10月27日内容总结——hashlib加密模块和logging、subprocess模块
目录 一.hashlib加密模块 1.何为加密 2.为什么加密 3.如何判断数据是否以加密 4.密文的长短有什么意义 5.加密算法的基本操作 二.加密补充说明 三.subprocess模块 1.sub ...
- QuartzNet在winform中使用(目前版本3.6)
界面图"没有什么技术含量~ 不过还是有部分人不太了解的 接下来一一解析下,勿q 使用步骤: 1.初始化帮助类 QuarztHelper x = new QuarztHelper(); 2 ...