【KAWAKO】模型的压缩、扩张,计算模型的各种成本
给自己挖个坑,这些都是工程上需要掌握的知识。
模型压缩
将高精度数据转为低精度格式,可以加快运算速度,同时也会降低网络推理的精度。
一般来说会将数据从浮点型转为int8型,有时会转为int16型。
量化后可以重新训练,恢复部分精度。
基于MNN的训练量化实现过程可以参考这篇博客
量化
稀疏化训练
剪枝
知识蒸馏
自蒸馏
集成
使用精细化模型结构
模型扩张
深度
宽度
输入图像的分辨率
深度、宽度、分辨率联合扩张
使用精细化模型结构
计算模型的各种成本
torchsummary是个不错的库,可以使用它查看网络结构、参数量和模型大小等信息。目前我发现的不足是无法支持LSTM(但是可以支持GRU)。这里使用之前写的AlexNet举个例子。
首先导入库,然后加载模型,最后使用summary函数并指定输入大小。
import models
from torchsummary import summary
model = models.AlexNet(outputdim=1000)
summary(model,(3,224,224))
输出如下

参数量
在打印出来的网络结构下面的三行,这些参数是通过其上方打印出来的网络结构右侧各层的参数量相加得到的。
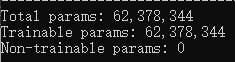
Total params: 共计参数量
Trainable params: 可训练参数量
Non-trainable params: 不可训练参数量
各种操作的参数量计算方法
卷积参数量:(kernel_width * kernel_height * input_channels + bias_num) * output_channels PS:如果没有bias则bias_num为0,有bias则bias_num为1
全连接层参数量:(input_params + bias_num) * output_params PS:同上
占用空间
在打印出的信息的最后四行。
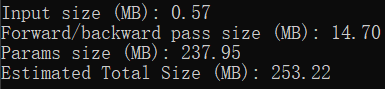
Input size (MB): 使用torchsummary时喂进去的输入大小。一般来说输入的batch_size默认为1,所以这里呈现的就是一份输入的大小。 Input size = input_datas * 4 / 1024 / 1024 PS:乘4是因为默认数据格式是float32,占4字节,除以两次1024是将Byte转为MB
Forward/backward pass size (MB): 网络中所有输出的大小(打印出来的网络结构中的output shape中的输出大小)的和的两倍(一次前向,一次反向)。这个数值的具体含义我目前还没有理解透彻。 PS:同样需要乘4、除以两次1024
Params size (MB): 上文中计算出来的总参数量的大小。 Params size = Total_params * 4 / 1024 / 1024 PS:同样需要乘4、除以两次1024
Estimated Total Size (MB): 总大小。
如果使用 ↓ 来保存模型(只保存参数),保存出来的模型大小与 Params size 几乎相同。
torch.save(model.state_dict(), 'trainedModels/test.pth')
计算量(FLOPS、FLOPs)
FLOPS
每秒浮点运算次数。一般来说硬件的FLOPS以T或P来评估。
不同硬件的FLOPS可以直接查到或根据其核心频率计算得到。
FLOPs
浮点运算数、模型计算量。
卷积:FLOPs = kernel_width * kernel_height * input_channels * output_width * output_height * output_channels
池化:FLOPs = kernel_width * kernel_height * output_width * output_height * output_channels
全局池化:FLOPs = input_width * intput_height * intput_channels
深度可分离卷积:FLOPs = input_channels * output_width * output_height * (kernel_width * kernel_height + output_channels)
ReLU:FLOPs = input_width * intput_height * intput_channels
Sigmoid:FLOPs = input_width * intput_height * intput_channels * 4
全连接:FLOPs = (input_channels * 2 + 1) * output_channels
BatchNormalization:FLOPs可以忽略,因为推理时没有用到
以上计算公式参考了这篇知乎。
从卷积的FLOPs计算公式中可以应证在Efficientnet那篇论文中提到的
将深度扩大两倍,FLOPs会扩大两倍。但是将宽度或输入图像的分辨率扩大两倍,FLOPs会扩大四倍。
同样的,如果我们减小一半深度,FLOPs会减小一半;减小一半宽度或输入图像的分辨率,FLOPs会减小四分之一。
使用thop库可以查看FLOPs和总参数量。 用下面的代码把summary和thop的输出做一个对比。
import models
from torchsummary import summary
import torch
from thop import profile
model = models.AlexNet(outputdim=1000)
summary(model,(3,224,224))
input = torch.randn(1,3,224,224)
flops, params = profile(model, (input,))
print("flops = ", flops)
print("params = ", params)

从输出可以看到,两个库计算得到的参数量是一致的,thop计算得到的FLOPs大概为1.1million左右,换算过来也就是1.058G左右。
但是网上公布的AlexNet的FLOPs约为0.7G左右,这是因为他们计算的是论文原文中的那种并行的AlexNet结构,其使用了两块显卡进行计算,因此大家计算FLOPs时计算的是一张卡上的计算量。
运行时占用内存
这个不太好计算,我目前还没有找到实用的计算方法。
最好的方法还是运行一下然后实时监控内存占用情况。
推理速度
网络的推理速度受以下因素影响:
- 推理之外的文件读写操作,如数据的读取和预处理。(这个其实不算在推理速度里。。。但是对程序运行速度有关,所以我列了出来)
- 模型的后处理操作,这些操作可能没有用到GPU而是在CPU上进行运算的。
- 推理时的计算量,也就是FLOPs。
- GPU的显存带宽,FLOPs少但是显存带宽低也会限制推理速度,因为每次计算都会涉及到向显存中进行数据读写。
解决方案:
- 使用各种办法优化数据预处理速度。比如优化代码、c++的O3编译优化、将一些预处理步骤放到GPU上进行而不是CPU上进行等。
- 优化后处理算法、将一些后处理步骤放到GPU上进行而不是CPU上进行等。
- 优化模型结构,对模型进行压缩。
- 使用更nb的显卡~(冲一个3090)~,使用对显存带宽要求低的算子。
对推理时间的计算就很简单了,python、c++都有自己的time库,推理之前计一个时刻,推理之后计一个时刻,然后将两个时刻相减即可。
【KAWAKO】模型的压缩、扩张,计算模型的各种成本的更多相关文章
- MapReduce 计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- 第四篇:MapReduce计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- 性能测试学习之二 ——性能测试模型(PV计算模型)
PV计算模型 现有的PV计算公式是: 每台服务器每秒平均PV量 =( (总PV*80%)/(24*60*60*40%))/服务器数量 =2*(总PV)/* (24*60*60) /服务器数量 通过定积 ...
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- Spark计算模型
[TOC] Spark计算模型 Spark程序模型 一个经典的示例模型 SparkContext中的textFile函数从HDFS读取日志文件,输出变量file var file = sc.textF ...
- LSF-SCNN:一种基于 CNN 的短文本表达模型及相似度计算的全新优化模型
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 本篇文章是我在读期间,对自然语言处理中的文本相似度问题研究取得的一点小成果.如果你对自然语言处理 (natural language proc ...
- MXNET:深度学习计算-模型参数
我们将深入讲解模型参数的访问和初始化,以及如何在多个层之间共享同一份参数. 之前我们一直在使用默认的初始函数,net.initialize(). from mxnet import init, nd ...
- MXNET:深度学习计算-模型构建
进入更深的层次:模型构造.参数访问.自定义层和使用 GPU. 模型构建 在多层感知机的实现中,我们首先构造 Sequential 实例,然后依次添加两个全连接层.其中第一层的输出大小为 256,即隐藏 ...
- [Pytorch]深度模型的显存计算以及优化
原文链接:https://oldpan.me/archives/how-to-calculate-gpu-memory 前言 亲,显存炸了,你的显卡快冒烟了! torch.FatalError: cu ...
随机推荐
- “XZ”格式文件解压
1.下载xz 官网:https://tukaani.org/xz/ 例:wget https://nchc.dl.sourceforge.net/project/lzmautils/xz-5.2.6. ...
- Windows10下python3和python2同时安装(一)安装python3和python2
Windows10下python3和python2同时安装(一) 安装python3和python2 特别说明,本文是在Windows64位系统下进行的,32位系统请下载相应版本的安装包,安装方法类似 ...
- 10-排序6 Sort with Swap(0, i) (25point(s))
10-排序6 Sort with Swap(0, i) (25point(s)) Given any permutation of the numbers {0, 1, 2,..., N−1}, it ...
- Agileboot 1.6.0 发布啦 - 一款致力于规范/精简/可维护 的Springboot + Vue3的快速开发脚手架
平台简介 AgileBoot是一套开源的全栈精简快速开发平台,毫无保留给个人及企业免费使用.本项目的目标是做一款精简可靠,代码风格优良,项目规范的小型开发脚手架. 适合个人开发者的小型项目或者公司内部 ...
- React DevUI 18.0 正式发布🎉
Jay 是一位经验丰富并且对质量要求很高的开发者,对 Angular.React 等多种框架都很熟悉,我们在开源社区认识,在我做开源社区运营的过程中,Jay 给了我很多帮助,他也是 React Dev ...
- 大数据-业务数据采集-FlinkCDC
CDC CDC 是 Change Data Capture(变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入.更新以及删除等),将这些变更按发生的顺序完整记录下来,写入 ...
- 使用 Visual Studio 2022 调试Dapr 应用程序
使用Dapr 编写的是一个多进程的程序,使用Visual Studio 调试起来可能会比较困难,因为 Visual Studio 默认只会把你当前设置的启动项目的启动调试. 好在有Visual Stu ...
- Golang Gorm 封装 分页查询 Where Order 查询
说说为什么写Gorm,因为公司新项目需要,研究了下Go下的gorm.对于一个项目首先考虑的问题,就是封装一些常用的工具方法,例如多参数查询 where or Like 还有order by Limit ...
- 【JVM故障问题排查心得】「内存诊断系列」Docker容器经常被kill掉,k8s中该节点的pod也被驱赶,怎么分析?
背景介绍 最近的docker容器经常被kill掉,k8s中该节点的pod也被驱赶. 我有一个在主机中运行的Docker容器(也有在同一主机中运行的其他容器).该Docker容器中的应用程序将会计算数据 ...
- CVE-2020-1938与CVE-2020-13935漏洞复现
前言 最近在腾讯云上买了个服务器,准备用来学习.在安装了7.0.76的tomcat后,腾讯云提醒我存在两个漏洞,分别是CVE-2020-1938和CVE-2020-13935,在修复完漏洞后,准备复现 ...