第四篇:MapReduce计算模型
前言
本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路。
模型架构
在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角色:一个是JobTracker,一个是TaskTracker,前者用于管理和调度工作,后者用于执行工作。
一般来说,一个Hadoop集群由一个JobTracker和N个TaskTracker构成。
执行流程
每次计算任务都可以分为两个阶段,Map阶段和Reduce阶段。
其中,Map阶段接收一组键值对模式<key, Value>的输入并产生同样是键值对模式<key, Value>的中间输出;
Reduce阶段负责接收Map产生的中间输出<key, Value>,然后对这个结果进行处理并输出结果。
这里举个很简单的例子,有一个程序用来统计文本中各个单词出现的个数,那么每个Map任务可以负责提取出文本中的所有单词并产生n个<word, 1>这样的输出;
而Reduce任务可以负责对这些中间输出做出处理,转换成<word, n> 这样的输出。
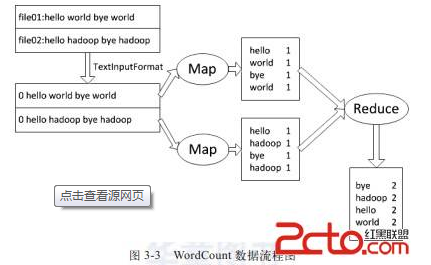
多说一句,Map产生的中间输出是直接放在本地磁盘,job完成后就会删除了。而Reduce产生的最终结果才会存放在Hdfs上。
编码框架说明
编码涉及到一些细节,建议结合具体代码进行分析,这里只给出一个框架性的说明。推荐阅读经典的wordcount程序。
1. 导入Hadoop开发需要用到的一些包
2. 定义一个需要用到分布式计算的类
3. 在此类中添加Map类,并使该类继承Mapper抽象类,然后实现该抽象类中的map方法。
4. 在此类中添加Reduce类,并使该类继承Reducer抽象类,然后实现该抽象类中的reduce方法。
5. 在类中定义一个成员函数并做如下操作:
a. 定义一个Job对象负责job调度
b. 往a中定义的job对象中注入2中定义的分布式类 (setJarByClass)
c. 定义分布式任务的名字 (setJobName)
d. 往a中定义的job对象中注入输出的key和value的类型 (setOutPutKeyClass,setOutPutKeyClass)
e. 往a中定义的job对象中注入3和4中定义的Map,Reduce类
f. 往a中定义的job对象中注入数据切分格式类 (setInputFormat,setOutputFormat)
g. 往a中定义的job对象中注入输出的路径地址 (setInputPaths,setOutputPath)
h. 启动计算任务 (waitForCompletion)
i. 返回布尔类型的执行结果
6. 在主函数中调用上述方法 (命令行方式)
运行方法
1. 执行以下格式的命令以编译分布式计算类
javac -classpath "hadoop目录下的core.jar" -d "结果输出目录" "分布式类文件名"
2. 执行以下格式的命令将该类打包成jar
jar -cvf "结果文件名(后缀.jar)" -C "目标目录" "结果输出目录"
3. 执行以下格式的命令将输入文件存入HDFS文件系统 (该命令将在HDFS上创建一个名为input的目录并将用户目录下input目录内前缀为file的文件导入进去):
dfs -mkdir input
dfs -put ~/input/file0* input
4. 执行以下格式的命令启动hadoop程序 (下面的参数一和二一般分别指输入和输出目录)
jar "分布式类jar包" "分布式类名" 参数一,参数二......
MapReduce的数据流和控制流
下面来讨论一下Hadoop程序的数据流和控制流的关系,首先请看下图:
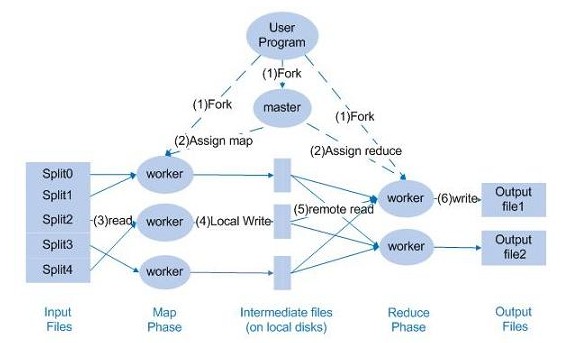
首先,由Master,也即JobTracker负责分派任务到下面的各个worker,也即TaskTracker。
某个worker在执行的时候,会返回进度报告,master负责记录进度的进行状况。
若某个worker失败,那么master会分派这个执行失败的任务给新的worker。
程序优化技巧
MapReduce程序的优化主要集中在两个方面:一个是运算性能方面的优化;另一个是IO操作方面的优化。
具体体现在以下的几个环节之上:
1. 任务调度
a. 尽量选择空闲节点进行计算
b. 尽量把任务分配给InputSplit所在机器
2. 数据预处理与InputSplit的大小
尽量处理少量的大数据;而不是大量的小数据。因此可以在处理前对数据进行一次预处理,将数据进行合并。
如果自己懒得合并,可以参考使用CombineFileInputFormat函数。具体用法请查阅相关函数手册。
3. Map和Reduce任务的数量
Map任务槽中任务的数量需要参考Map的运行时间,而Reduce任务的数量则只需要参考Map槽中的任务数,一般是0.95或1.75倍。
4. 使用Combine函数
该函数用于合并本地的数据,可以大大减少网络消耗。具体请参考函数手册。
5. 压缩
可以对一些中间数据进行压缩处理,达到减少网络消耗的目的。
6. 自定义comparator
可以自定义数据类型实现更复杂的目的。
小结
本文大致讲解了Hadoop的编程模型MapReduce,并大致介绍了如何在这个框架下进行简单的程序开发。
更复杂的框架剖析以及Hadoop高级程序开发,将在以后的文章中进行细致的探讨。
第四篇:MapReduce计算模型的更多相关文章
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍map ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- MapReduce 计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- 转载:Spark中文指南(入门篇)-Spark编程模型(一)
原文:https://www.cnblogs.com/miqi1992/p/5621268.html 前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apac ...
- MapReduce 编程模型
一.简单介绍 1.MapReduce 应用广泛的原因之中的一个在于它的易用性.它提供了一个因高度抽象化而变得异常简单的编程模型. 2.从MapReduce 自身的命名特点能够看出,MapReduce ...
- Hadoop入门第二篇-MapReduce学习
mapreduce是一种计算模型,是google的一篇论文向全世界介绍了MapReduce.MapReduce其实可以可以用多种语言编写Map或Reduce程序,因为hadoop是java写的,所以通 ...
随机推荐
- SQLITE WITH ENTITY FRAMEWORK CODE FIRST AND MIGRATION
Last month I’ve a chance to develop an app using Sqlite and Entity Framework Code First. Before I st ...
- Sublime Text 3 For Mac
安装 Sublime Text 3 下载地址:http://www.sublimetext.com/3 我此时使用的是Build 3083版本. 安装 Package Control 这个是精华所在, ...
- js if判断 遍历 替换图片地质
<script> $(document).ready(function() { var s = "The rain in Spain falls mainly in the pl ...
- checkbox批量删除功能
参考:http://www.jb51.net/article/35338.htm 感谢作者 代码片段:jsp <c:forEach items="${infolist }" ...
- C#的publisher与subscriber,事件发布者与订阅者
说明:示例借鉴自这里,但原版很不友好,于是修改了下,一目了然. 直接上代码: using System; using System.Collections.Generic; using System. ...
- 计算机网络——网络层
一.虚拟线路与数据报线路 1. 在网络层提供有连接的计算机网络为虚电路网络: 如因特网:它需要VC(虚拟电路)号,用于建立虚拟电路的报文称为信令报文,相关的协议称为信令协议: 无连接的网络为数据报网络 ...
- SpringMVC系列(四)使用 POJO 对象绑定请求参数值
在实际开发中如果参数太多就不能使用@RequestParam去一个一个的映射了,需要定义一个实体参数对象(POJO)来映射请求参数.Spring MVC 会按请求参数名和 POJO 属性名进行自动匹配 ...
- (转) UDP包的大小与MTU
在进行UDP编程的时候,我们最容易想到的问题就是,一次发送多少bytes好?当然,这个没有唯一答案,相对于不同的系统,不同的要求,其得到的答案是不一样的,我这里仅对像ICQ一类的发送聊天消息的情况作分 ...
- JAVA并发:深入分析volatile
Java volatile 汇编代码研究 JVM执行篇:使用HSDIS插件分析JVM代码执行细节 聊聊并发(一)——深入分析Volatile的实现原理 深入Java底层:内存屏障与JVM并发详解 深入 ...
- linux stat命令参数及用法详解
功能说明:显示inode内容.语 法:stat [文件或目录]补充说明:stat以文字的格式来显示inode的内容. ls 命令及其许多参数提供了一些非常有用的文件信息.另一个不太为人所熟知的命令 s ...