Prometheus介绍及docker安装方式
一、介绍
Prometheus是主要基于Go编写,最初在SoundCloud上构建的开源系统监视和警报工具包,它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于2015年正式发布,Prometheus 于2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目,成为受欢迎度仅次于 Kubernetes 的项目。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
Prometheus的特点如下:
- 一个多维数据模型,包含度量标准名称和键值对标识的时间序列数据
- PromQL,一种灵活的查询语言
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据
- 可以通过中间网关进行时序列数据推送
- 通过服务发现或者静态配置来发现目标服务对象
- 支持多种多样的图表和界面展示,比如Grafana等
- 由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
- 大多数Prometheus组件都是用Go编写的,因此易于构建和部署为静态二进制文件
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这类 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
Prometheus采集数据的方式:
Prometheus的数据采集方式,Prometheus采集数据有pull和push两种方式。pull方式是在客户端(被监控机器)系统上先安装各类已有的exproters(由社区组织或企业开发的监控客户端插件),然后exproters会以守护进程的模式运行并且开始采集数据。exproter本身是一个http_server,可以对http请求作出响应返回数据(K/V metrics),prometheus服务端用pull的方式(http get)去访问每个节点上exporter并采样需要的数据,Pull是一种主动拉取的形式。
push方式可以在任意地方安装官方提供的pushgateway插件,不需要必须在服务器,它自己本身就是个服务器,相当于作为一个中介,首先由运维自行开发的各种脚本部署在客户端,然后把监控采集到的数据组织成k/v的形式(metrics形式)发送给pushgateway,之后pushgateway再推送给prometheus,一般以http的post方式推送,push是一种被动接收的形式。pushgateway有两个缺点:一是pushgateway会形成一个单点瓶颈,假如好多个脚本同时发送给一个pushgateway的进程,如果这个进程没了,那么监控数据也没了。二是pushgateway并不能对发送来的数据做智能的判断,如果脚本采集的数据有问题,那么有问题的数据也会同样发给pushgateway,pushgateway一样会收取,然后发送给prometheus。
Prometheus采集数据metrics的主要两种类型,首先metrics不是一种具体的数据格式,它是一种对于度量计算单位的抽象。metrics的主要两种类型是Gauge(仪表盘)和Counter(计数器),gauge表示瞬时变化,没有规律的变化,侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内存大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。counter类型的指标其工作方式和计数器一样,只增不减(除非系统重置),常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。除了这两种常用的还有Histogram(直方图)和Summary(摘要)两种。采集到的数据metrics以空格分开key/value的形式进行展示
二、安装
Prometheus安装方式可以通过二进制文件安装,也可以通过docker方式安装,这里我依然采用docker方式进行安装
1.docker-hub搜索并下载镜像prom/pometheus
docker search Prometheus
docker pull docker.io/prom/Prometheus
2.下载镜像grafana,grafana是一个开源的功能丰富的数据可视化平台,通常用于时序数据的可视化
docker pull grafana/Grafana
3.下载镜像node-exporter,node-exporter用于机器系统数据收集
docker pull prom/node-exporter
4.分别创建并运行容器prometheus、grafana、node-exporter
docker run --name myprometheus -p 9090:9090 -d prom/prometheus
docker run --name mygrafana -p 3000:3000 -d grafana/grafana
docker run --name mynode-exporter -p 9100:9100 -d prom/node-exporter
5.这样安装好的prometheus只是监控了prometheus server自己,prometheus本身也会收集自己的监控数据,并没有配置exporter监控插件,所以target目录下没有exporter,然后需要进行下配置,配置的方式是修改prometheus.yml配置文件,配置文件进入容器后在etc目录下,配置好后需要重启容器。
docker exec -it myprometheus sh
cd /etc/prometheus
vi prometheus.yml
配置node-exporter所在服务器的ip加端口号
docker restart myprometheus
启动容器如下:
三、使用
1.浏览器访问:http://192.168.0.125:9100/,会展示收集的数据,出现页面如下:
2.浏览器访问:http://192.168.0.125:9090/,展示prometheus页,出现页面如下:
3.浏览器访问:http://192.168.0.125:3000/,进入可视化登录页面,出现页面如下:
默认用户名和密码都是admin,进入首页如下:
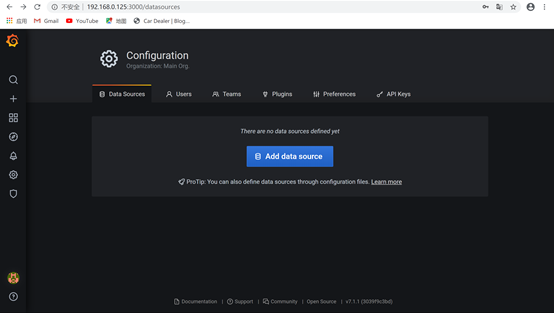
4.首先需要设置数据源,使grafana连接上prometehus server,点击Add data Source
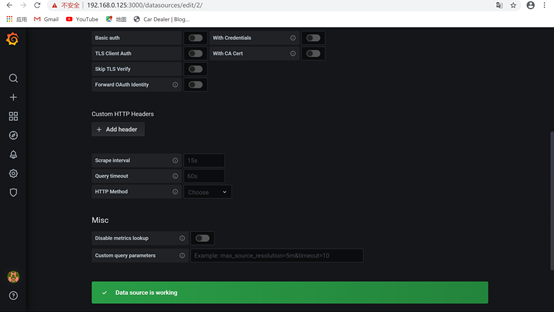
5.输入url然后save
6.首页点击new dashboard然后edit
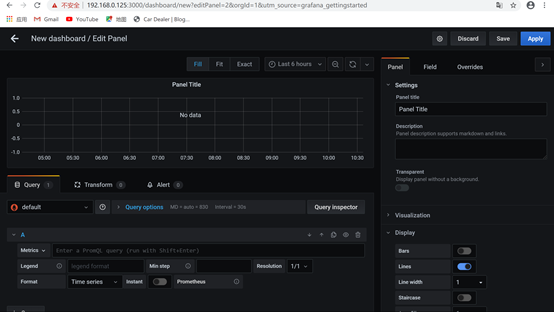
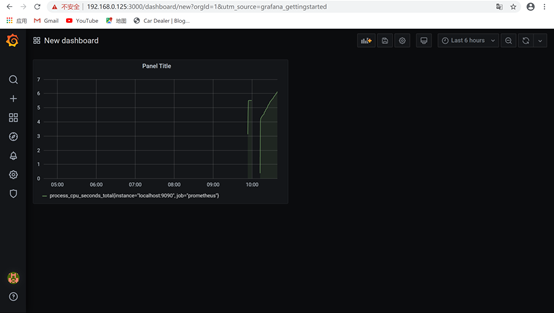
7.可在metrics处输入cpu,来检测cpu的情况,然后query,效果如下:
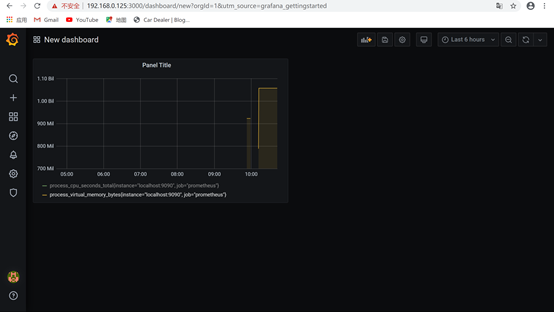
8.可以输入memory检测虚拟机情况,添加查询,效果如下:
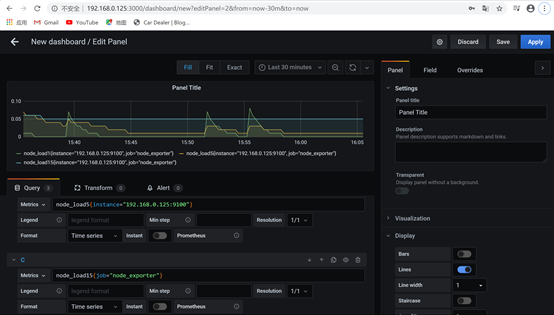
9.在metrics输入{instance,job}可以指定某台实例或者根据job指定,如下图:
10.使用docker命令docker exec -it myprometheus /bin/bash进入docker中prometheus时报错:starting container process caused "exec: \"bash\": executable file not found in $PATH",这个错误说明镜像不包含适合bash的风格操作,没有这样的文件或目录,可能你的镜像基于busybox,它没有bash shell。但他在/bin/sh有一个shell,直接执行 docker exec -it myprometheus /bin/sh 就可以进入容器里面。
Prometheus介绍及docker安装方式的更多相关文章
- Pinpoint介绍及docker安装方式
一.介绍 Pinpoint是用Java编写的大型分布式系统的APM(Application Performance Management应用程序性能管理)工具,受Dapper论文的启发,Pinpoin ...
- 调度系统Airflow1.10.4调研与介绍和docker安装
Airflow1.10.4介绍与安装 现在是9102年,8月中旬.airflow当前版本是1.10.4. 随着公司调度任务增大,原有的,基于crontab和mysql的任务调度方案已经不太合适了,需要 ...
- windows docker安装方式的比较小结
稍微小结一下使用InstallDocker 和dockertoolbox的两种方式安装的docker(名称说明可能不妥,仅代表安装方式) InstallDocker 使用的是Microsoft Hy ...
- ElasticSearch 介绍、Docker安装以及基本检索第三篇
一.简介 1.1 什么是Elasticsearch? Elasticsearch是一个分布式的开源搜索和分析引擎, 适用于所有类型的数据,包括文本.数字.地理空间.结构化和啡结构化数据.Elastic ...
- 手动安装 saltshaker-plus 版本选择特别说明(后期重点讲解Docker安装方式)
前后端都建议使用1.12版本
- 关于MYSQL数据库安装方式及相关设置简要说明
网上关于MYSQL的教程非常多,但都不是最新的,我这里只是针对最新版本的MY SQL 的安装与设置进行一个简要的说明,大部份操作都相同. 以下是按照WINDOWS 64位操作系统+MY SQL 5.6 ...
- docker安装脚本
此docker安装脚本为官方提供的,可以从网上下载,此处直接把脚本内容贴上. #!/bin/sh set -e # This script is meant for quick & easy ...
- 使用 Docker 安装 showdoc
一.简介 ShowDoc 是一个非常适合IT团队在线共享文档的工具,在线访问地址为:https://www.showDoc.cc 本来也可以直接 pull showdoc 镜像到本地,使用 docke ...
- Linux平台达梦数据库V7单实例安装方式之图形方式
一 前言 我们在学习任何一个应用时,了解它的最初步骤通常是学会如何进行安装配置,后序才去关心如何使用,学习达梦数据库也是如此,而达梦数据库的安装提供了多种方式,接下来会一一介绍每种安装方式,达梦数据库 ...
随机推荐
- MySQL8.0降级安装5.7
本文旨在自我学习使用,如有任何疑问请及时联系博主 前言 基于OpenHarmony的FA数字管家服务端 默认情况下,Ubuntu20.04安装MySQL的版本为8.0.但8.0更加严格的加密规则,使得 ...
- 不带头结点的单链表(基于c语言)
本篇文章的代码大多使用无头结点的单链表: 相关定义: #include <stdio.h> #include <stdlib.h> #include <assert.h& ...
- [AT2306]Rearranging(拓扑序)
[AT2306]Rearranging(拓扑序) 只有luogu 题面(luogu): 有一个$n$个数组成的序列$a_{i}$. 高桥君会把整个序列任意排列,然后青木君可以选择两个相邻的互质的数交换 ...
- VSCode编写vue项目文件出现红色波浪线
VSCode编写vue项目文件出现红色波浪线 在我们在写Vue或其他项目时,可能会遇到这样一个问题:明明自己的代码程序都没有错,代码规范也符合标准,为什么它就是给我报错显红呢??? 解决方案 第一种方 ...
- 【VNCTF2022】Reverse wp
babymaze 反编译源码 pyc文件,uncompy6撸不出来,看字节码 import marshal, dis fp = open(r"BabyMaze.pyc", 'rb' ...
- 整理分布式锁:业务场景&分布式锁家族&实现原理
1.引入业务场景 业务场景一出现: 因为小T刚接手项目,正在吭哧吭哧对熟悉着代码.部署架构.在看代码过程中发现,下单这块代码可能会出现问题,这可是分布式部署的,如果多个用户同时购买同一个商品,就可能导 ...
- java动态代理--代理接口无实现类
转载:https://blog.csdn.net/weixin_45674354/article/details/103246715 1.接口定义: package cn.proxy; public ...
- SpringBoot starter 作用在什么地方?
依赖管理是所有项目中至关重要的一部分.当一个项目变得相当复杂,管理依赖会成为一个噩梦,因为当中涉及太多 artifacts 了. 这时候 SpringBoot starter 就派上用处了.每一个 s ...
- 通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应, 请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法, 参数不同时,方法能重载吗?
Dao 接口即 Mapper 接口.接口的全限名,就是映射文件中的 namespace 的值: 接口的方法名,就是映射文件中 Mapper 的 Statement 的 id 值:接口方法内的 参数,就 ...
- Configuration problem: 'bean' or 'parent' is required for <ref> element
我出现此错误的原因是web.xml中没有指定spring的启动配置文件applicationContext.xml的加载位置.applicationContext.xml原来再webRoot/webI ...