12. Fluentd部署:多Workers进程模式
介绍如何使用Fluentd的多worker模式处理高访问量的日志事件。此模式会运行多个worker进程以最大利用多核CPU。
- 原理
默认情况下,一个Fluentd实例会运行一个监控进程和一个工作进程。工作进程包含了Input/Filter/Output各类插件。
多worker模式就是一个实例中启动了多个工作进程,这些工作进程负责处理日志事件,接受监控进程的管理和调度。如下图所示:
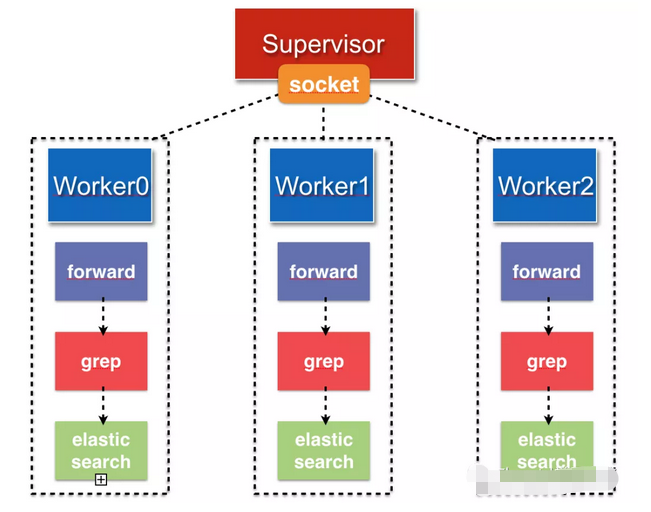
Fluentd提供了一些特性以支持多worker模式,我们通过配置就能方便地使用这些特性。
- 配置
2.1 workers参数
可在中设置工作进程的数目。
<system>
workers 4
</system>
2.2 指令
有些插件不支持在多worker上运行,比如tail。
对这类插件,我们可通过<worker N>指定其在哪个worker上运行。
N代表worker的索引,起始为0.
<system>
workers 4
</system>
# work on multi process workers. worker0 - worker3 run in_forward
<source>
@type forward
</source>
# work on only worker 0. worker1 - worker3 don't run in_tail
<worker 0>
<source>
@type tail
</source>
</worker>
# <worker 1>, <worker 2> or <worker 3> is also ok
这个例子中,启动了4个工作进程。tail插件被放置在<worker 0>中,表明tail只运行在索引为0的工作进程上。
这种配置可以混合使用多进程插件和单进程插件。
2.3 指令
Fluentd v1.4.0开始支持<worker N-M>指令。这个很容易理解。
N-M代表工作进程索引范围,指定了插件可以运行在哪些工作进程中。
<system>
workers 6
</system>
<worker 0-1>
<source>
@type forward
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 0 and worker 1.
<worker 2-3>
<source>
@type tcp
<parse>
@type none
</parse>
tag test
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 2 and worker 3.
<worker 4-5>
<source>
@type udp
<parse>
@type none
</parse>
tag test
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 4 and worker 5.
2.4 root_dir/@id参数
使用文件作为buffer时,需要配置这几个参数。
在多worker模式中,不能指定固定的path作为文件buffer,因为这会不同进程中引起冲突。
<system>
workers 2
</system>
<match pattern>
@type forward
<buffer>
@type file
path /var/log/fluentd/forward # This is not allowed
</buffer>
</match>
Fluentd提供了基于root_dir和@id的动态path配置,实际的buffer路径为:${root_dir}/worker${worker index}/${plugin @id}/buffer
<system>
workers 2
root_dir /var/log/fluentd
</system>
<match pattern>
@type forward
@id out_fwd
<buffer>
@type file
</buffer>
</match>
- 操作
每个worker使用单独的内存和磁盘空间,因此需要仔细配置缓存空间,并对内存和磁盘使用情况做好监控。
12. Fluentd部署:多Workers进程模式的更多相关文章
- Linux Rsync备份服务介绍及部署守护进程模式
rsync介绍 rsync是一款开源的.快速的.多功能的.可实现全量及增量的本地或远程数据同步备份工具 在常驻模式(daemon mode)下,rsync默认监听TCP端口873,以原生rsync传输 ...
- 10. Fluentd部署:高可用配置
对于高访问量的web站点或者服务,可以采用Fluentd的高可用配置模式. 消息分发语义 Fluentd设计初衷主要是用作事件日志分发系统的.这类系统支持几种不同的分发模式: 至多一次.消息被立即发送 ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- 在nginx上部署vue项目(history模式)--demo实列;
在很早之前,我写了一篇 关于 在nginx上部署vue项目(history模式) 但是讲的都是理论,所以今天做个demo来实战下.有必要让大家更好的理解,我发现搜索这类似的问题还是挺多的,因此在写一篇 ...
- suse 12 编译部署Keepalived + nginx 为 kube-apiserver 提供高可用
文章目录 编译部署nginx 下载nginx源码包 编译nginx 配置nginx.conf 配置nginx为systemctl管理 分发nginx二进制文件和配置文件 启动kube-nginx服务 ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第05章 - 部署kube-nginx
文章目录 1.5.部署kube-nginx 1.5.0.下载nginx二进制文件 1.5.1.编译部署nginx 1.5.2.配置nginx.conf 1.5.3.配置nginx为systemctl管 ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第07章 - 部署kube-controller-manager组件
文章目录 1.7.部署kube-controller-manager 1.7.0.创建kube-controller-manager请求证书 1.7.1.生成kube-controller-manag ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第10章 - 部署kube-proxy组件
文章目录 1.10.部署kube-proxy 1.10.0.创建kube-proxy证书 1.10.1.生成kube-proxy证书和秘钥 1.10.2.创建kube-proxy的kubeconfig ...
- Fluentd部署详解
Fluentd系统配置项 https://www.cnblogs.com/sanduzxcvbnm/p/13920972.html Fluentd自身日志 https://www.cnblogs.co ...
随机推荐
- 总结下对我对于CSS中BFC的认知
首先第一个,什么是BFC? BFC的全称叫Block Formatting Context (块级格式化上下文)BFC是css中隐含属性,开启BFC后元素会变成一个独立的布局环. 简单来说,它 ...
- 【万字长文】使用 LSM-Tree 思想基于.Net 6.0 C# 实现 KV 数据库(案例版)
文章有点长,耐心看完应该可以懂实际原理到底是啥子. 这是一个KV数据库的C#实现,目前用.NET 6.0实现的,目前算是属于雏形,骨架都已经完备,毕竟刚完工不到一星期. 当然,这个其实也算是NoSQL ...
- 可变参数和Collections集合工具类
可变参数 /** * 可变参数:jdk1.5后出现的新特性 * 使用前期: * 当方法的参数列表数据类型已经确定的时候但是参数的个数不确定的时候就可以使用可变参数 * 使用格式:定义方法的时候使用 * ...
- 1000-ms-maven相关问题
一.Maven有哪些优点和缺点 优点如下: 简化了项目依赖管理: 易于上手,对于新手可能一个"mvn clean package"命令就可能满足他的工作 便于与持续集成工具(jen ...
- 可以级联的以太网远程IO模块的优点与适用场景
可以级联的以太网远程IO模块的优点与具体的适用场景 对于数据采集控制点是按照线性分布的场景,比如智慧园区的路灯.桥梁.路灯.数字化工厂.停车场车位监测.智慧停车场.智能停车架.楼宇自动控制系统等场景, ...
- python--函数参数传递
1. 调用函数时,实参会传递给形参,叫做参数传递. 2. 根据实际参数的类型不同,函数参数的传递方式可分为 2 种,分别为值传递和引用(地址)传递: 值传递:传递的实参类型为不可变类型(字符串.数字. ...
- Blazor和Vue对比学习(进阶2.2.3):状态管理之状态共享,Blazor的依赖注入和第三方库Fluxor
Blazor没有提供状态共享的方案,虽然依赖注入可以实现一个全局对象,这个对象可以拥有状态.计算属性.方法等特征,但并不具备响应式.比如,组件A和组件B,都注入了这个全局对象,并引用了全局对象上的数据 ...
- v-model原理问题
v-model的原理 很多同学在理解Vue的时候都把Vue的数据响应原理理解为双向绑定,但实际上这是不准确的,我们之前提到的数据响应,都是通过数据的改变去驱动DOM重新的变化,而双向绑定已有数据驱动D ...
- 面试突击73:IoC 和 DI 有什么区别?
IoC 和 DI 都是 Spring 框架中的重要概念,就像玫瑰花与爱情一样,IoC 和 DI 通常情况下也是成对出现的.那 IoC 和 DI 什么关系和区别呢?接下来,我们一起来看. 1.IoC 介 ...
- python包合集-cffi
一.cffi cffi是连接Python与c的桥梁,可实现在Python中调用c文件.cffi为c语言的外部接口,在Python中使用该接口可以实现在Python中使用外部c文件的数据结构及函数. 二 ...