工作流引擎在vivo营销自动化中的应用实践 | 引擎篇03
作者:vivo 互联网服务器团队- Cheng Wangrong
本文是《vivo营销自动化技术解密》的第4篇文章,分析了在营销自动化业务引入工作流技术的背景和工作流引擎的介绍,同时介绍了几种业界流行的开源工作流引擎特点,以及在项目自研开发过程中的设计思路和总结思考。
《vivo营销自动化技术解密》系列文章:
一、业务背景
营销自动化平台可以支持不同用户生命周期的活动旅程策略配置 ,根据用户触发的不同活动行为,进行差异化的营销触达方案。同时各种类型活动的具体执行过程中也有不同的业务处理流程(比如审批流程和业务流转)。
业务流程复杂多样,需求变更频繁,项目开发过程中会有以下痛点:
- 项目交付周期长:一个完整的业务流程需要从头开始按版本迭代,开发时间长,成本高。
- 功能重复开发测试:业务之间会掺杂着很多共性的流程,导致大量重复性开发测试工作,效率低。
- 维护成本高:随着项目业务的逐步发展,业务流程逐步积累,可维护性下降,系统改动牵一发而动全身。
如何将业务逻辑从控制流中剥离出来,让产研人员更聚焦于业务的实现是需要重点解决的问题。而传统OA领域使用的是久经考验的业务流程管理解决方案 —— 工作流(Workflow)。工作流是一套工业级的解决方案,由工作流管理联盟(WfMC)制定了一系列的标准。
二、工作流介绍
2.1 工作流定义
工作流(Workflow)—— 对工作流程及其各操作步骤之间业务规则的抽象,将流程中的工作组织逻辑和规则进行建模,交由计算机进行自动处理。
工作流的本质思想是:通过预定义的工作流程模板,对现实活动进行实例化的过程。简单说就是通过预设的格式或者可视化配置好流程的模板(比如一种分享活动的运行流程模板),使用时通过该模板构造出一个流程实例对象,通过实例对象完成活动运行跟踪和回溯。
2.2 工作流参考模型
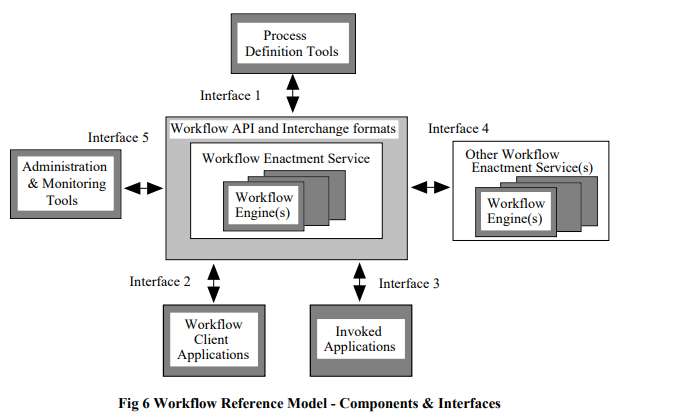
WfMC工作流管理联盟为工作流制定了参考模型,其核心就是中间的工作流引擎,工作流引擎提供流程定义工具(接口1)、给使用者提供信息查询(接口2)、调用外部应用(接口3)、整合其他工作流(接口4)和监控管理(接口5)的能力。 对于大多数工作流产品而言,重点关注的是接口1和接口2的实现。
2.3 工作流引擎关键特性
- 流程可视化
提供可视化的流程搭建,流程视图查看能力,以及实时观测任务运行能力。
- 业务可编排复用
将公共业务进行组件化,可以支持任务的自由编排,自由搭建出适合的业务的不同流程。
- 业务和控制分离
将流程的控制(如流转、判断、循环、重试等)的任务交由工作流负责,让使用者聚焦于核心业务逻辑。
2.4 工作流引擎的类型
对于工作流的类型没有专门的标准,按照流程任务节点特性可以分为:
- 顺序工作流
顺序工作流的运行方式类似一种特定的流程图,上一个流程任务完成后依次进入下一个流程任务,过程不可逆。

- 状态机工作流
状态机工作流侧重关注的是流程任务的状态,驱使任务状态发生变化的因素一般为外部事件,即事件驱动的方式,驱使任务节点从一个状态运行到另外一个状态,节点间可逆。
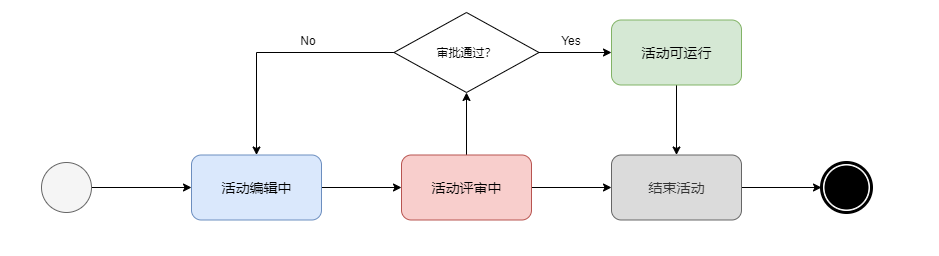
- 规则驱动工作流
侧重于节点的运转规则,基于业务规则进行工作流程的执行,在处理具有明确目标但“规则”或规范级别不同的各种项目时,规则驱动的工作流非常有用。
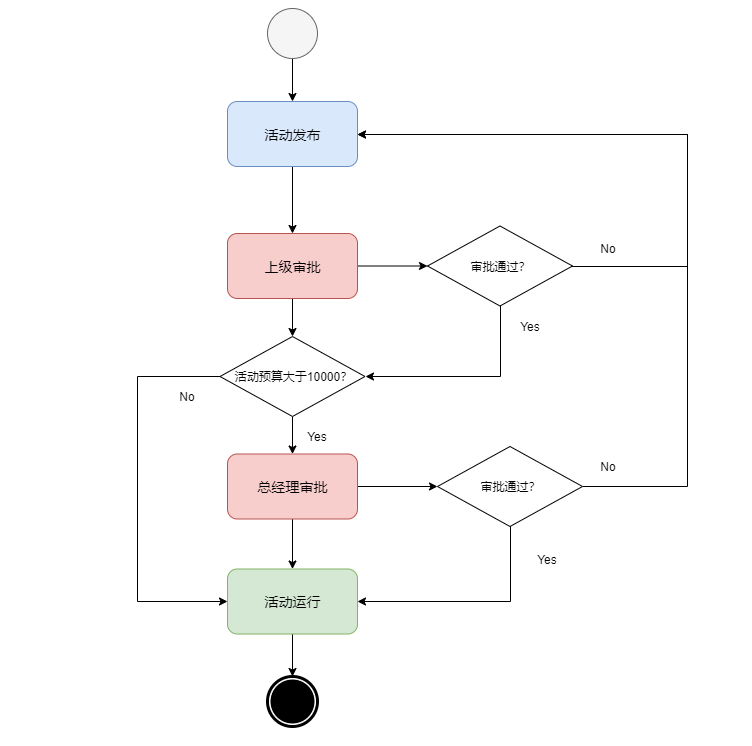
可以看到不同类型的工作流不是完全割裂的,状态机工作流中也可以结合着条件和规则进行操作节点转换的过程。在软件开发中,一般会考虑结合状态机和规则驱动的工作流。
2.5 工作流引擎和状态机的差异
在之前的文章里面,我们有对状态机和工作流引擎做过一次简单的对比,事实上,两者之间并不是一个完全对等的概念:
- 状态机是系统状态以及这些状态之间转移和动作等行为的数学计算模型,而工作流是对整体工作流程及其各操作步骤之间业务逻辑和规则的抽象建模。
- 状态机模式是事件驱动型,大多通过外部事件触发状态的自动流转;工作流引擎更侧重于描述预定义流程任务完成之后的自动流转,可预测性会更强。
- 从适用场景的复杂性上看,直接使用状态机的方式可以清晰地描绘出所有可能的状态以及导致转换的事件,适用于解决单维度、复杂度不高的业务问题,发挥灵活轻便的特点;工作流引擎则更适合复杂的业务流程管理,解决如大型CRM复杂度更高的流程自动化问题,聚焦于改善整体业务流程的效率。
- 工作流引擎是可以在状态机的结构模型基础上进行构建,事实上很多开源的工作流引擎也都是基于状态机的实现方式。
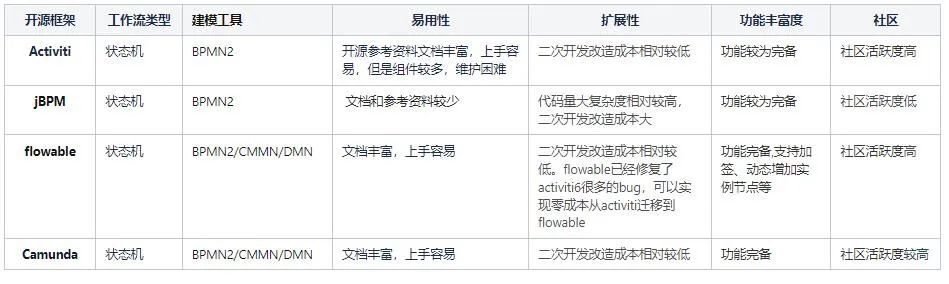
了解了工作流的基本特点和使用场景之后,我们来看一下比较流行的开源工作流引擎。
三、开源工作流引擎
四、工作流引擎自研设计
4.1 使用开源工作流引擎的问题
- 开源工作流最大的优势是可以借助开源的资源,开箱即用,功能全面,但是与之带来的是附带的配置和表数量比较多的维护问题。以Activiti为例,使用Activiti7.0版本至少要引入二十多张表,虽然说看似是无侵入的方式,但是系统演进和维护过程中有一定的成本。特别是业务流程实例很多的时候,开发人员需要对表逻辑有更深的把控。
- 由于业务的客观独特性,作为业务流程组件,一般都需要根据自身业务进行二次开发适配。 比如需要根据自身组织架构,进行流程节点用户角色权限的管控;将自身的业务能力插件化,加入工作流程配置中,进行拦截回调等。
4.2 自研引擎核心设计思路
4.2.1 引擎核心模块
回归工作流的本质, 工作流是通过预定义的流程模板,对现实活动进行实例化的过程。一个基本的工作流引擎主要包括三大核心部分:
- 流程模板创建
根据业务规则和逻辑,创建流程模板,设置每一个节点的操作和变更路径。基于模板创建,可以延伸出流程设计器、插件式节点,多样化的模板文件格式、模板持久化等。
- 流程实例发布
根据流程模板,创建一个流程实例,流程模板和流程实例的关系类似类和对象的关系。比如说工单系统管理员定义好一个审批流模板(流程模板),用户点击创建一个工单(流程实例)。基于流程实例发布,又可以延伸出实例实时观测,节点变迁记录回溯,实例状态持久化,失败重试,事务控制等。
- 任务流程执行
创建好流程实例之后,流程实例只需要按照流程模板的定义独立执行各自实例的任务,不同的实例之间互不影响,完成各自实例的生命周期。
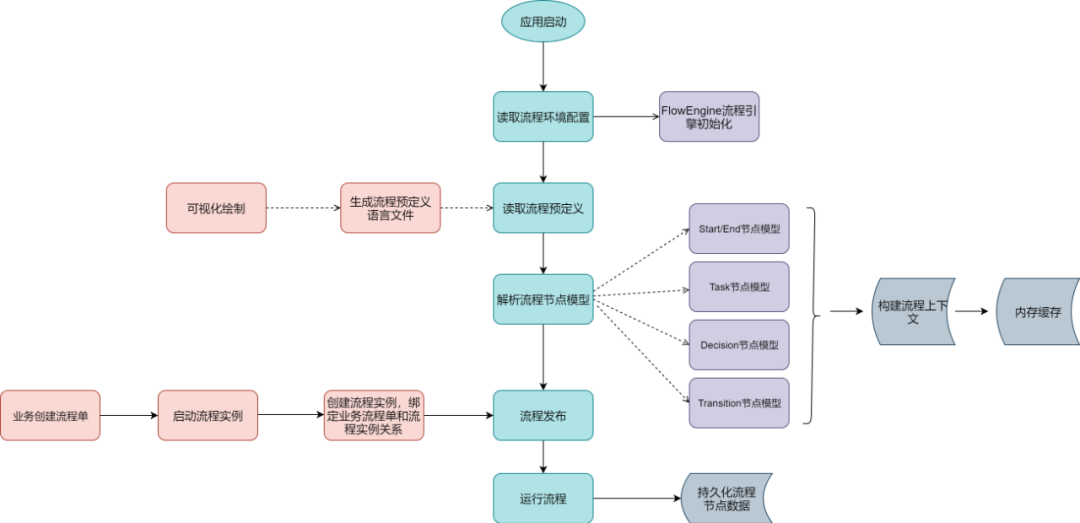
4.2.2 引擎核心设计
① 应用容器启动时,加载流程引擎环境配置,包括解析器构造,流程引擎上下文,流程定义文件路径等。
② 读取定好的流程定义文件,进行流程节点解析,构建好执行上下文,将流程节点放到内存缓存中。
③ 业务侧进行流程创建,启动一个新的流程实例,同时将业务流程和流程实例进行绑定。
④ 运行流程实例各个节点,将每个流程节点进行持久化保存。
4.3 具体实践
① 引擎核心服务。
引擎操作的主要对外接口,包括启动流程实例,和获取相关流程定义模板,流程实例,流程节点的服务。
public interface FlowEngine {
/**
* 根据流程定义key,参数列表启动流程实例
*
*/
FlowInstance startInstance(String processDefKey, Map<String, Object> args);
/**
* 根据流程定义主键ID,参数列表执行流程任务(推动流程自动流转)
* 统一事务控制
*/
void execInstance(Long instanceId, Map<String, Object> args) throws FlowAuthorityException;
/**
* 获取流程定义process服务
*
*/
ProcessService process();
/**
* 获取流程实例服务
*
*/
InstanceService instance();
/**
* 获取任务节点服务
*
*/
TaskService task();
}
② 流程定义服务。
主要是针对流程定义模板的创建和发布,可以根据具体的实现类来支持不同的创建方式。
public interface ProcessService {
/**
* 创建流程定义模板
*
*/
void create(String definition);
/**
* 发布流程定义模板
*
*/
void deploy(String fileName);
/**
* 获取流程key对应的流程定义
*/
FlowProcess getProcessByDefKey(String processDefKey);
}
③ 流程实例服务。
提供流程实例创建持久化和流程实例执行的入口。
public interface InstanceService {
/**
* 创建流程实例
*
*/
FlowInstance createInstance(FlowProcess process, Map<String, Object> args);
/**
* 执行流程实例
*
* @param instanceId 流程实例id
*/
void exec(Long instanceId);
/**
* 根据id获取流程实例
*
* @param instanceId
* @return
*/
FlowInstance getById(Long instanceId);
}
④ 流程任务节点服务。
提供流程节点具体每个任务的创建和查询。
public interface TaskService {
/**
* 根据任务模型、执行对象创建新的任务
*
*/
FlowTask createTask(TaskModel taskModel, Execution execution);
/**
* 完成任务
*
*/
FlowTask complete(Long taskId, Map<String, Object> args);
/**
* 获取流程实例中正在进行的任务
*
*/
FlowTask getActiveTask(Long instanceId);
/**
* 获取流程实例上一个已完成的任务
*
*/
FlowHistTask getLastDoneTask(Long instanceId);
}
其中核心的方法就是
FlowEngine#startInstanceByKey,启动流程实例。基于流程定义,创建一个流程实例对象。
FlowEngine#execInstance,执行流程实例任务,通过传入的上下文参数(操作人,操作变量等),按照流程定义的节点任务,推进流程实例的自动流转。
4.4 思考和扩展
- 流程定义解析性能。
由于目前设计是在应用启动时对所有的流程定义文件进行加载和解析,流程定义文件过多时会影响应用启动速度,可以通过多线程解析和懒加载(使用时解析)两种方式进行优化。
- 流程定义版本兼容性。
由于业务流程不是一成不变的,在项目发展过程中会不断进行迭代,需要对前面不同的流程进行兼容。
- 流程节点插件化和编排能力。
将基础服务进行提取公用,以支持绘制不同流程的插件化和编排能力。
- 流程执行监控能力。
对流程任务节点执行情况进行埋点上报,系统自动进行监测告警。
五、总结
本文分析了引入工作流引擎的背景,驱使业务逻辑从控制流中剥离出来,让产研团队更聚焦于业务,解决研发效率低的问题。
工作流的本质思想是通过预定义的工作流程模板,对现实活动进行实例化的过程。一般需要具备流程可视化、业务可编排复用、 业务和控制分离的基本能力。一般常见的工作流分为顺序工作流、状态机工作流和规则驱动工作流,开源工作流框架中最常见的是状态机工作流,利用事件驱动的方式,驱使流程运转。
同时简单介绍了业界比较流行的几种开源工作流引擎的特点,结合开源工作流引擎的特点的问题,并且针对多样化和迭代频繁的业务流程, 以工作流的本质思想为出发点,我们自研了一套轻量级的工作流引擎,分享了在实践过程中的设计思路和总结思考。
工作流引擎在vivo营销自动化中的应用实践 | 引擎篇03的更多相关文章
- 状态机引擎在vivo营销自动化中的深度实践 | 引擎篇02
本文是<vivo营销自动化技术解密>的第3篇文章,分析了营销自动化业务背景和状态机引入原因.状态机的三种基本实现方式,同时介绍了几种业界流行的开源状态机框架实现和特点,以及在项目开发过程中 ...
- 实时营销引擎在vivo营销自动化中的实践 | 引擎篇04
作者:vivo 互联网服务器团队 本文是<vivo营销自动化技术解密>的第5篇文章,重点分析介绍在营销自动化业务中实时营销场景的背景价值.实时营销引擎架构以及项目开发过程中如何利用动态队列 ...
- 设计模式如何提升 vivo 营销自动化业务扩展性 | 引擎篇01
在<vivo 营销自动化技术解密 |开篇>中,我们从整体上介绍了vivo营销自动化平台的业务架构.核心业务模块功能.系统架构和几大核心技术设计. 本次带来的是系列文章的第2篇,本文详细解析 ...
- vivo营销自动化技术解密|开篇
一.营销自动化概览 1.1. 什么是营销自动化 营销自动化是指专门为营销部门或组织设计的软件平台和技术,可以更有效地在线进行多渠道营销并使重复性任务自动化.营销部门和销售人员通过制定任务和流程的操作标 ...
- vivo浏览器的快速开发平台实践-总览篇
一.什么是快速开发平台 快速开发平台,顾名思义就是可以使得开发更为快速的开发平台,是提高团队开发效率的生产力工具.近一两年,国内很多公司越来越注重研发效能的度量和提升,基于软件开发的特点,覆盖管理和优 ...
- Sitecore营销自动化
增加与战略性自动化营销系统的互动 Sitecore营销自动化基于DMS中的Sitecore个性化功能.营销自动化系统使用诸如位置,设备和先前访问或购买之类的客户数据来影响用户沿着购买路径的旅程.这些系 ...
- U-Mail邮件群发触发器功能助力营销自动化
小编在朋友圈看到的人工智能讨论越来越多,越来越多的上班族惶恐不安,担心自己的饭碗不保将被人工智能所取代,这说明智能化.自动化正成为各行业的趋势,营销也概莫能外.营销的自动化意味着将大大节省从业人员的精 ...
- PCB 围绕CAM自动化,打造PCB规则引擎
AutoCAM自动化平台,前端管理订单,而后端执行任务,前端UIl界面有板厚,铜厚,板材,表面处理,层数等信息,而这些信息并不是后端最终所需要的信息后.拿钻孔补偿来说,后端需要的是钻孔补偿值,但前端并 ...
- 转!!MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
MySQL中的存储引擎: 1.存储引擎的概念 2.查看MySQL所支持的存储引擎 3.MySQL中几种常用存储引擎的特点 4.存储引擎之间的相互转化 一.存储引擎: 1.存储引擎其实就是如何实现存储数 ...
随机推荐
- 【论文笔记】A review of applications in federated learning(综述)
A review of applications in federated learning Authors Li Li, Yuxi Fan, Mike Tse, Kuo-Yi Lin Keyword ...
- [笔记] prufer 序列
什么是 prufer 序列 是可以和 \(n\) 个有标号节点的无根树一一对应的长度为 \(n-2\) 的序列. 一般来说是用于和树相关的组合计数问题,但是可能会出现一些变形,所以除了要了解一些性质, ...
- HMS Core分析服务助您掌握用户分层密码,实现整体收益提升
随着市场愈发成熟,开发者从平衡收益和风险的角度开始逐步探索混合变现的优势,内购+广告就是目前市场上混合变现的主要方式之一. 对于混合变现模式,您是否有这样的困惑: 如何判断哪些用户更愿意看广告.哪些用 ...
- 流量录制回放工具jvm-sandbox-repeater入门篇——录制和回放
在上一篇文章中,把repeater服务部署介绍清楚了,详细可见:流量录制回放工具jvm-sandbox-repeater入门篇--服务部署 今天在基于上篇内容基础上,再来分享下流量录制和回放的相关内容 ...
- 轮播——swiper
swiper组件 1.轮播数据是使用ajax进行填充的话,可能数目是0~n,在数目是1时,轮播会出现一些问题(出现空白侧),这时需作出判断(一张图片不滑动,多张就就行滑动),方法如下(以下方法中,si ...
- kNN-准备数据
在上一小节,我们大概了解了kNN算法的基本原理,现在我们要进行数据的处理 本小节所用数据集来自[机器学习实战]:Machine Learning in Action (manning.com) 下载数 ...
- RocketMq 完整部署
目录 RocketMq 部署 环境 物理机部署 自定义日志目录 自定义参数和数据存放位置 服务启动 启动name server 启动broker 关停服务 尝试发送消息 常见报错 部署 rockerm ...
- H5如何实现唤起APP
前言 写过hybrid的同学,想必都会遇到这样的需求,如果用户安装了自己的APP,就打开APP或跳转到APP内某个页面,如果没安装则引导用户到对应页面或应用商店下载.这里就涉及到了H5与Native之 ...
- CesiumJS 2022^ 原理[5] - 着色器相关的封装设计
目录 1. 对 WebGL 接口的封装 1.1. 缓冲对象封装 1.2. 纹理与采样参数封装 1.3. 着色器封装 1.4. 上下文对象与渲染通道 1.5. 统一值(uniform)封装 1.6. 渲 ...
- 『忘了再学』Shell基础 — 14、环境变量(二)
目录 1.PS1变量的作用 2.PS1变量的查看 2.PS1可以支持的选项 3.PS1环境变量的配置 4.总结 提示: 在Linux系统中,环境变量分为两种.一种是用户自定义的环境变量,另一种是系统自 ...