栈的存储结构和常见操作(c 语言实现)
俗话说得好,线性表(尤其是链表)是一切数据结构和算法的基础,很多复杂甚至是高级的数据结构和算法,细节处,除去数学和计算机程序基础的知识,大量的都在应用线性表。
一、栈
其实本质还是线性表:限定仅在表尾进行插入或删除操作。 俗称:后进先出 (LIFO=last in first out结构),也可说是先进后出(FILO)。
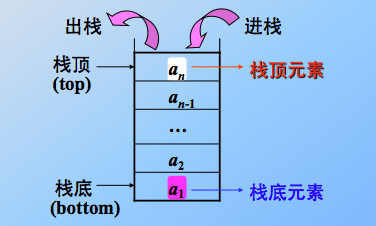
同样的,栈也分为顺序和链式两大类。其实和线性表大同小异,只不过限制在表尾进行操作的线性表的特殊表现形式。
1、顺序栈:利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针 top 指示栈顶元素在顺序栈中的位置,附设指针 base 指示栈底的位置。 同样,应该采用可以动态增长存储容量的结构。且注意,如果栈已经空了,再继续出栈操作,则发生元素下溢,如果栈满了,再继续入栈操作,则发生元素上溢。栈底指针 base 初始为空,说明栈不存在,栈顶指针 top 初始指向 base,则说明栈空,元素入栈,则 top++,元素出栈,则 top--,故,栈顶指针指示的位置其实是栈顶元素的下一位(不是栈顶元素的位置)。
#ifndef _____ADT__
#define _____ADT__
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#define STACK_SIZE 50
#define STACK_INCREMENT 10 typedef struct{
int stackSize;//栈容量
char *base;//栈底指针
char *top;//栈顶指针
} SqStack; //初始化
//本质还是使用动态数组
void initStack(SqStack *s)
{
s->base = (char *)malloc(STACK_SIZE * sizeof(char));
//分配成功
if (s->base != NULL) {
//空栈
s->top = s->base;
s->stackSize = STACK_SIZE;
}
else
{
puts("分配失败!");
}
} //判空
bool isEmpty(SqStack s)
{
return s.top == s.base ? true : false;
} //判满
bool isFull(SqStack s)
{
return (s.top - s.base) >= STACK_SIZE ? true : false;
} //求当前长度
int getLength(SqStack s)
{
int i = ;
char *q = s.top; while (q != s.base) {
q--;
i++;
} return i;
} //求栈顶元素
char getTop(SqStack s, char topElement)
{
if (isEmpty(s)) {
puts("栈空!");
} topElement = *(s.top - );
return topElement;
} //入栈
void push(SqStack *s, char topElement)
{
char *q = NULL; if (isFull(*s)) {
q = (char *)realloc(s->base, STACK_INCREMENT * sizeof(char)); if (NULL == q) {
exit();
} s->base = q;
s->stackSize = s->stackSize + STACK_INCREMENT;
}
//进栈
*s->top++ = topElement;
} //出栈
void pop(SqStack *s, char *topElement)
{
if (isEmpty(*s)) {
exit();
} s->top--;
*topElement = *s->top;
} //遍历
void traversal(SqStack s)
{
for (int i = ; i < getLength(s); i++) {
printf("栈中元素遍历:%c \n", s.base[i]);
}
} //清空
void cleanStack(SqStack *s)
{
if (!isEmpty(*s)) {
s->top = s->base;
puts("栈已经清空!");
}
} //销毁
void destroyStack(SqStack *s)
{
if (s->base != NULL) {
free(s->base);
s->base = NULL;
s->top = NULL;
s->stackSize = ;
puts("栈成功销毁!");
}
} #endif /* defined(_____ADT__) */
函数: void exit(int status); 所在头文件:stdlib.h
功 能: 关闭所有文件,终止正在执行的进程。
exit(1)表示异常退出.这个1是返回给操作系统的。
exit(x)(x不为0)都表示异常退出
exit(0)表示正常退出
exit()的参数会被传递给一些操作系统,包括UNIX,Linux,和MS DOS,以供其他程序使用。
exit()和return的区别:
按照ANSI C,在最初调用的main()中使用return和exit()的效果相同。 但要注意这里所说的是“最初调用”。如果main()在一个递归程序中,exit()仍然会终止程序;但return将控制权移交给递归的前一级,直到最初的那一级,此时return才会终止程序。
return和exit()的另一个区别在于,即使在除main()之外的函数中调用exit(),它也将终止程序。
_exit()与exit的区别:
头文件不同:
exit:#include<stdlib.h>
_exit:#include<unistd.h>
_exit()函数:直接使进程停止运行,清除其使用的内存空间,并销毁其在内核中的各种数据结构;
exit()函数则在这些基础上作了一些包装,在执行退出之前加了若干道工序。比如系统调用之前exit()要检查文件的打开情况,把文件缓冲区中的内容写回文件。
#include "ADT.h"
int main(void) {
char temp = '';
SqStack stack;
initStack(&stack);
printf("%d\n", getLength(stack));
push(&stack, 'b');
push(&stack, 'k');
push(&stack, 'y');
printf("%d\n", getLength(stack));
// 函数使用temp之前必须初始化
temp = getTop(stack, temp);
printf("%c\n", temp);
traversal(stack);
pop(&stack, &temp);
printf("%d\n", getLength(stack));
traversal(stack);
cleanStack(&stack);
destroyStack(&stack);
return ;
}
测试结果:
0
3
y
栈中元素遍历:b
栈中元素遍历:k
栈中元素遍历:y
2
栈中元素遍历:b
栈中元素遍历:k
栈已经清空!
栈成功销毁!
Program ended with exit code: 0
顺序栈的小结:
1)、尽量使用指向结构的指针做函数参数,这样的操作比结构体变量作函数参数效率高,因为无需传递各个成员的值,只需传递一个结构的地址,且函数中的结构体成员并不占据新的内存单元,而与主调函数中的成员共享存储单元。这种方式还可通过修改形参所指成员影响实参所对应的成员值。
2)、栈清空,一定是栈顶指向栈底,不可颠倒,否则析构出错!
3)、再次注意二级指针和一级指针做函数参数的不同
4)、使用一个指针变量之前,必须初始化,不为指针分配内存,即指针没有指向一块合法的内存,那么指针无法使用,强行运行出错,这就是野指针的危害。类似其他类型变量都是如此,(这也是为什么建议声明变量的同时就立即初始化,哪怕是一个不相干的数值),就怕程序写的复杂的话,一时忘记变量是否初始化,导致出错。
5)、为什么顺序栈(包括顺序表)在初始化函数的传入参数里不用二级指针传参?
个人理解:
首先清楚函数传参的类型,值传递,引用(c++)传递,和指针传递,且函数修改的是实参的一份拷贝,并不是直接去修改实参。
问题是,在之前的链表里,定义结点结构( Node)和指向结点的指针 p,有 struct Node *p;为了给结点分配内存,把这个指针(p本身占据一份内存空间,在栈区操作系统分配,但是 p 的指向是没有初始化的)p 传入初始化函数内,等于是传入的指向结点Node的一个指针 p 的拷贝 _p,而这个拷贝 _p 本身(假设指针变量p自己在内存的地址是0x1111)和拷贝 _p 存储的(指针 p指向的 内存区域)内容是不一样的,此时给 拷贝 _p 使用malloc函数分配内存,看似是修改了 _p ,实际上是把 _p 指向的内存区域改变了, p 本身在内存的地址(0x1111)没有被改变,故函数执行完毕,栈分配的内存被操作系统回收,然后参数返回给主调函数,那份拷贝 _p 还是以前传入的那份拷贝 _p, 高矮胖瘦那是纹丝未动,故不会对实参起到修改的作用,完全类似值传递,在值传递,就是把实参的本身的值传入函数,如果函数内部对其拷贝进行修改,其实传入的参数本身并没有被改变,虽然函数体内,他的值被修改了,但是一旦函数执行完,栈的内存被系统回收,修改就变得徒劳。
顺序栈里,一般是定义的整个表List结构,struct List p;变量p 就是一个实例化的栈结构,注意 p 已经分配了内存(主调函数 main ,操作系统在栈区给p分配),这和主调函数里链表的指针 p 不一样,链表的指针 p 在 main 函数,只是给指针本身分配了内存空间,但是对 其指向的表结点没有分配,需要在初始化函数初始化!故到了顺序栈里,当给函数传入&p(因为开始main 已经给栈结构分配了内存空间,而&p 是栈结构 p 在内存的地址0x1111,也就是栈本身的首地址,也是 base指向的栈的基址),同样是传入一份拷贝 _&p ,且不是给 _&p malloc 内存,而是给 _&p 指向的内容分配空间—— (&p)->base(表的基地址)分配内存,也就是说,这里堆 p 修改也是没用的,但是对 p 的指向修改,也就是 base,是有用的。而 base 本身就是一个指针,p 其实和 base 值相等,只不过变量的类型不一样,故不需要再传入二级指针。
6)、初始化那里,其实写的不好,主调函数里 s 分配了内存,如果没有对这个结构体初始化,就不代表 s 的成员 base 或者 top 等就是有指向的,更别说 NULL 了。很大程度是指向是垃圾值,不确定的内存区域,故这里的判断
if (s->base != NULL)
在这个前提下,是没有用处的语句。故还是声明变量的同时,最好是初始化,哪怕是0或者 NULL。
2、链栈
其实就是链表的特殊情形,一个链表,带头结点,栈顶在表头,插入和删除(出栈和入栈)都在表头进行,也就是头插法建表和头删除元素的算法。显然,链栈还是插入删除的效率较高,且能共享存储空间。
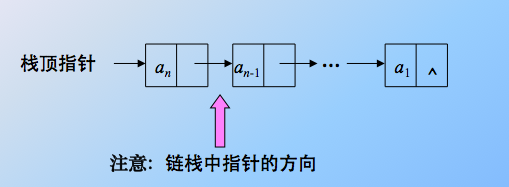
是栈顶在表头!栈顶指针指向表头结点。栈底是链表的尾部,base 就是尾指针。还有,理论上,链式结构没有满这一说,但是理论上是这样的,也要结合具体的内存,操作系统等环境因素。
#ifndef _____ADT__
#define _____ADT__
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h> typedef struct Node{
char data;
struct Node *next; //next 指针
} Node, *ListStack; //初始化头结点,top 指针指向头结点
void initStack(ListStack *top)
{
//top就是头指针!也就是栈顶指针
*top = (ListStack)malloc(sizeof(Node));
//就一个结点,也就是空栈,其实和链表一样,没啥意思
(*top)->next = NULL;
//内容初始化
(*top)->data = '';
} //判空
bool isEmpty(ListStack top)
{
//栈顶指针的next==NULL 就是空栈,没有满的判断,但是也要悠着点。小心内存受不了。
return top->next == NULL ? true : false;
} //入栈
void push(ListStack top, char topElement)
{
ListStack q = NULL;
q = (ListStack)malloc(sizeof(Node)); if (NULL == q) {
exit();
}
//类似头插法建表,进栈
q->next = top->next;
top->next = q;
//赋值
top->data = topElement;
//栈底永远是表尾指针
} //出栈
void pop(ListStack top, char *topElement)
{
ListStack p = NULL; if (isEmpty(top)) {
exit();
}
//栈顶元素出栈,记住,栈顶指针永远是指向栈顶元素的下一位,p 指向栈顶元素
p = top->next;
*topElement = p->data;
//删除这个元素
top->next = p->next;
free(p);
} //求当前长度
int getLength(ListStack top)
{
int i = ;
ListStack q = top->next; while (q != NULL) {
i++;
q = q->next;
} return i;
} //求栈顶元素
char getTop(ListStack top, char topElement)
{
if (isEmpty(top)) {
puts("栈空!");
} topElement = top->next->data;
return topElement;
} //遍历
void traversal(ListStack top)
{
ListStack p = top->next; for (int i = ; i < getLength(top); i++) {
printf("栈中元素遍历:%c \n", p->data);
p = p->next;
}
} //销毁
void destroyLinkStack(ListStack *top)
{
ListStack p = *top;
ListStack pn = (*top)->next; while (pn != NULL)
{
free(p);
p = pn;
pn = pn->next;
}
//销毁最后一个
free(p);
p = NULL;
puts("栈成功销毁!");
} #endif /* defined(_____ADT__) */
main 函数
#include "ADT.h"
int main(void) {
ListStack stack = NULL;
initStack(&stack);
printf("栈长度 = %d\n", getLength(stack));
push(stack, 'a');
push(stack, 'b');
push(stack, 'c');
push(stack, 'd');
printf("栈长度 = %d\n", getLength(stack));
traversal(stack);
char temp = '';
printf("栈顶元素 = %c\n", getTop(stack, temp));
pop(stack, &temp);
printf("栈长度 = %d\n",getLength(stack));
traversal(stack);
destroyLinkStack(&stack);
return ;
}
其实链栈和链表是一样的,没什么新鲜的东西。可见,线性表,尤其是链表,是数据结构和算法里的重中之重,后续很多复杂高级的数据结构和算法,都会无数次的用到链表的相关知识和概念。
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!

栈的存储结构和常见操作(c 语言实现)的更多相关文章
- 队列的存储结构和常见操作(c 语言实现)
一.队列(queue) 队列和栈一样,在实际程序的算法设计和计算机一些其他分支里,都有很多重要的应用,比如计算机操作系统对进程 or 作业的优先级调度算法,对离散事件的模拟算法,还有计算机主机和外部设 ...
- 动态单链表的传统存储方式和10种常见操作-C语言实现
顺序线性表的优点:方便存取(随机的),特点是物理位置和逻辑为主都是连续的(相邻).但是也有不足,比如:前面的插入和删除算法,需要移动大量元素,浪费时间,那么链式线性表 (简称链表) 就能解决这个问题. ...
- C#创建安全的栈(Stack)存储结构
在C#中,用于存储的结构较多,如:DataTable,DataSet,List,Dictionary,Stack等结构,各种结构采用的存储的方式存在差异,效率也必然各有优缺点.现在介绍一种后进先出的数 ...
- 栈的存储结构的实现(C/C++实现)
存档 #include "iostream.h" #include <stdlib.h> #define max 20 typedef char elemtype; # ...
- C语言解释器的实现--存储结构(一)
目录: 1. 内存池 2. 栈 3. Hash表 1.内存池 在一些小的程序里,没什么必要添加内存管理模块在里面.但是对于比较复杂的代码,如果需要很多的内存操作,那么加入自己的内存管理是有必要的.至 ...
- 数据结构11: 栈(Stack)的概念和应用及C语言实现
栈,线性表的一种特殊的存储结构.与学习过的线性表的不同之处在于栈只能从表的固定一端对数据进行插入和删除操作,另一端是封死的. 图1 栈结构示意图 由于栈只有一边开口存取数据,称开口的那一端为“栈顶”, ...
- C++编程练习(4)----“实现简单的栈的链式存储结构“
如果栈的使用过程中元素数目变化不可预测,有时很小,有时很大,则最好使用链栈:反之,如果它的变化在可控范围内,使用顺序栈会好一些. 简单的栈的链式存储结构代码如下: /*LinkStack.h*/ #i ...
- C++中栈结构建立和操作
什么是栈结构 栈结构是从数据的运算来分类的,也就是说栈结构具有特殊的运算规则,即:后进先出. 我们可以把栈理解成一个大仓库,放在仓库门口(栈顶)的货物会优先被取出,然后再取出里面的货物. 而从数据的逻 ...
- Java栈之链式栈存储结构实现
一.链栈 采用单链表来保存栈中所有元素,这种链式结构的栈称为链栈. 二.栈的链式存储结构实现 package com.ietree.basic.datastructure.stack; /** * 链 ...
随机推荐
- PhoneGap(二维码扫描 )
关于 phoneGap 如何做 二维码扫描 1. 先配置好, 环境 http://coenraets.org/blog/cordova-phonegap-3-tutorial/http: ...
- oracle 11g RAC public/virtual/SACN/private IP we need to know
1.3.2.2 IP Address Requirements Before starting the installation, you must have at least two interfa ...
- 移动app框架inoic功能研究
原生移动app框架inoic功能研究 本篇只侧重框架提供的功能和能力的研究,请关注后续实际部署使用体验. 一.inoic是什么? inoic是一个可以使用Web技术以hybird方式开发移动app的前 ...
- android知识杂记(三)
记录项目中的android零碎知识点,用以备忘. 1.android 自定义权限 app可以自定义属于自己的权限: <permission android:description="s ...
- 图解集合5:不正确地使用HashMap引发死循环及元素丢失
问题引出 前一篇文章讲解了HashMap的实现原理,讲到了HashMap不是线程安全的.那么HashMap在多线程环境下又会有什么问题呢? 几个月前,公司项目的一个模块在线上运行的时候出现了死循环,死 ...
- 【C语言学习】《C Primer Plus》第13章 文件输入/输出
学习总结 1.文件函数原型1: FILE* fopen(char *filename, char *openmode); //打开文件,返回文件指针 filename:文件名,更确切地说,是包含文件 ...
- 【C语言学习】《C Primer Plus》第8章 字符输入/输出和输入确认
学习总结 1.缓冲区分为完全缓冲区(fully buffered)I/O和行缓冲区(line-buffered)I/O.对完全缓冲输入来说,当缓冲区满的时候会被清空(缓冲区内容发送至其目的地).这类型 ...
- 一天一小段js代码(no.4)
最近在看网上的前端笔试题,借鉴别人的自己来试一下: 题目: 写一段脚本,实现:当页面上任意一个链接被点击的时候,alert出这个链接在页面上的顺序号,如第一个链接则alert(1), 依次类推. 有一 ...
- 剑英陪你玩转图形学(五)focus
很久没来和大家交流业务(zhuangbi)水平了,最近实在是很忙,报名了小游戏大赛,一点时间都抽不出,已经坑了. 今天抓紧时间和大家介绍一个小效果: 新手引导的时候,我们会需要一种全屏幕黑掉,只有一个 ...
- 自定义 Azure Table storage 查询过滤条件
本文是在Azure Table storage 基本用法一文的基础上,介绍如何自定义 Azure Table storage 的查询过滤条件.如果您还不太清楚 Azure Table storage ...