索引深入浅出(5/10):非聚集索引的B树结构在堆表
在“索引深入浅出:非聚集索引的B树结构在聚集表”里,我们讨论了在聚集表上的非聚集索引,这篇文章我们讨论下在堆表上的非聚集索引。
非聚集索引可以在聚集表或堆表上创建。当我们在聚集表上创建非聚集索引时,聚集索引键担当为行指针。在堆表里,文件号,页号和槽号(file id , page number and slot number)的组合在非聚集索引里担当为行指针。
我们来看下手头的一个例子。我们创建salesorderdetail表的副本,并在上面的productid和salesorderid 列创建创建非聚集索引。
DROP TABLE SalesOrderDetailHeap SELECT * INTO dbo.SalesOrderDetailHeap FROM AdventureWorks2008r2.Sales.SalesOrderDetail
GO
CREATE UNIQUE INDEX Ix_ProductId ON SalesOrderDetailHeap(ProductId,Salesorderid)
收集非聚集索引相关信息:
TRUNCATE TABLE dbo.sp_table_pages
INSERT INTO sp_table_pages EXEC('DBCC IND(IndexDB,SalesOrderDetailHeap,2)')
GO SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC --根节点/索引页
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3720,3) DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3608,3)--叶子节点/索引页 DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3908,3)--叶子节点/索引页
SELECT * FROM dbo.sp_table_pages WHERE IndexLevel=0 --叶子节点/索引页
根据上述信息进行非聚集索引逻辑示意图的绘制:
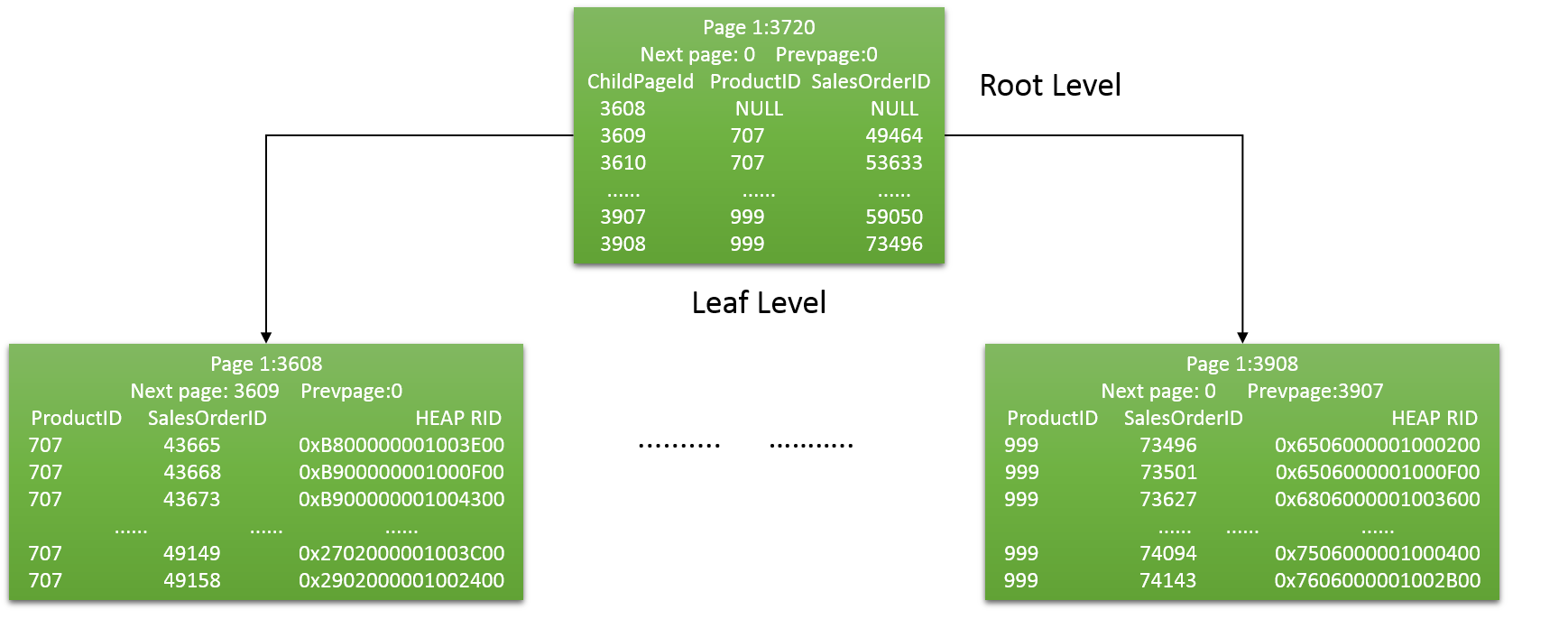
现在我们来分析下SQL Server如何存储堆表的非聚集索引,首先我们通过DBCC IND命令查看非聚集索引的页分配情况,最后一个参数,2是Ix_ProductId的索引号。
DBCC ind('IndexDB','SalesOrderDetailHeap',2)
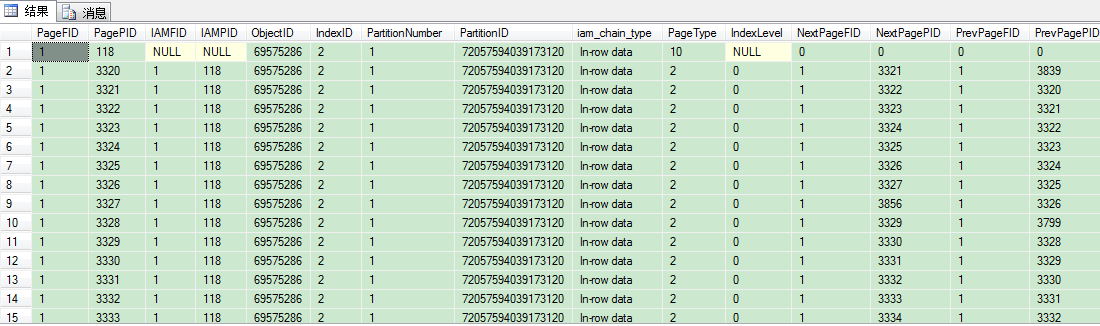

一共返回298条记录,包括1个IAM页,288个索引页,我们用下列语句找下根层的页号:
SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC

可以看到,indexlevel列最大值1的页号是3270,这个页就是根页,因为indexlevel列最大值是1,所以这个堆表的非聚集索引的B树结构只有2层,即根层和叶子层,也就是说288个索引页中,1个页是根层的根页(也是索引页),287个页是叶子层的索引页。我们来看看3270页的信息。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3720,3)
输出结果,和聚集表里的非聚集索引的根页结构是一样的。
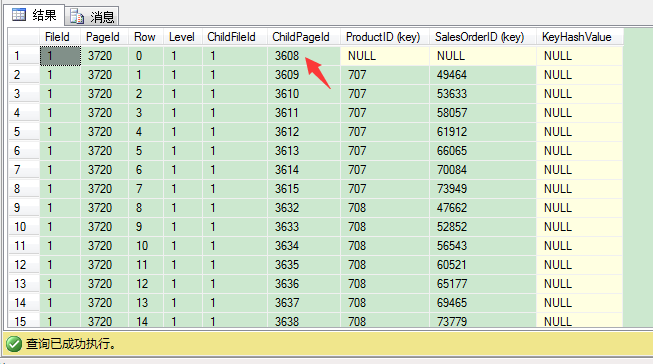
我们来看看叶子层的3608页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3608,3)--叶子节点/索引页
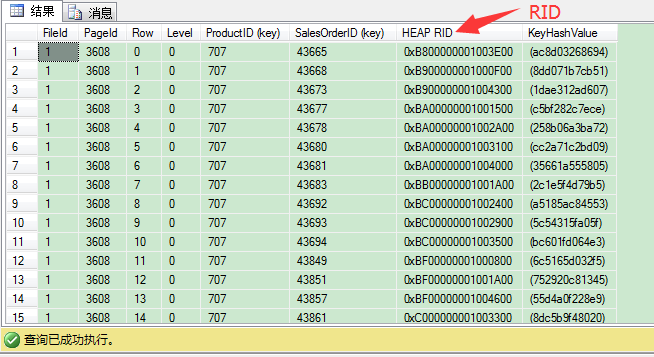
在聚集表的非聚集索引的叶子层,聚集键与非聚集键一齐加入了叶子层的页。这里我们没有聚集索引,索引SQL Server加了个行标识号(8 bytes大小),由文件号(2 bytes),页号(4 bytes)和槽号(2 bytes)组合而成。
从上图我们可以清楚看出,productid值为707,salesorderid值为43665的记录完整信息,可以在HeapRID 0xB800000001003E00位置找到。下面的查询可以帮我们把RID转为文件号:页号:槽号(FileId:PageId:SlotNo)格式。
DECLARE @HeapRid BINARY(8)
SET @HeapRid = 0xB800000001003E00
SELECT
CONVERT (VARCHAR(5),
CONVERT(INT, SUBSTRING(@HeapRid, 6, 1)
+ SUBSTRING(@HeapRid, 5, 1)))
+ ':'
+ CONVERT(VARCHAR(10),
CONVERT(INT, SUBSTRING(@HeapRid, 4, 1)
+ SUBSTRING(@HeapRid, 3, 1)
+ SUBSTRING(@HeapRid, 2, 1)
+ SUBSTRING(@HeapRid, 1, 1)))
+ ':'
+ CONVERT(VARCHAR(5),
CONVERT(INT, SUBSTRING(@HeapRid, 8, 1)
+ SUBSTRING(@HeapRid, 7, 1)))
AS 'Fileid:Pageid:Slot'

1:184:62表示文件号:1 ,页号:184 ,槽号:62。我们来看看184页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,184,3)
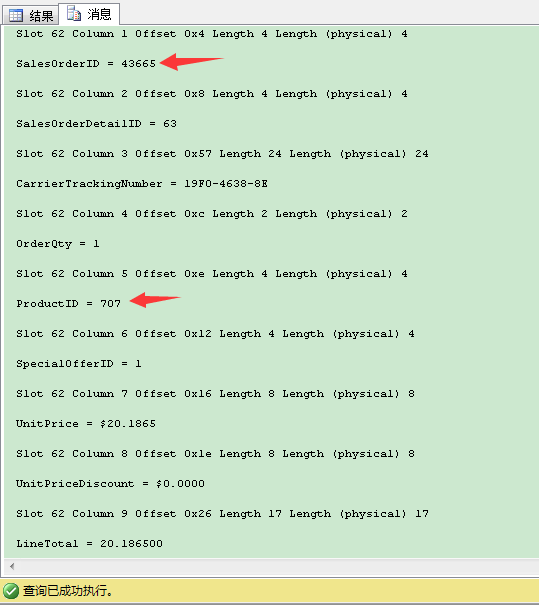
从输出我们可以看到,productid值为707,salesorderid值为43665的记录所有列可以在槽号62找到,与1:184:62表示文件号:1 ,页号:184 ,槽号:62完全一致。
我们通过下面的查询看看SQL Server如何使用非聚集索引查找堆表上的数据,点击工具栏的 显示包含实际的执行计划。
显示包含实际的执行计划。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

SQL Server需要进行2次I/O操作到达非聚集索引的叶子层,1次I/O操作通过使用RID查找(堆)拿到剩下的数据。执行计划如下所示:
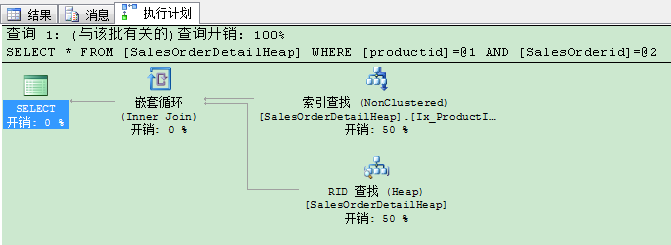
即使我们将查询语句修改为,只要 ProductId,SalesOrderid,SalesorderDetailId 这3列,SQL Server还是要进行键查找(Key lookup)操作。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665 SET STATISTICS IO ON
GO
SELECT ProductId,SalesOrderid,SalesOrderDetailID FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

这是因为,SalesorderDetailId列没有定义为聚集键,在非聚集索引的叶子层没有这列。为了避免键查找(key lookup)操作,我们需要将列限制到只有非聚集索引键(ProductKey ,salesorderid)。
SET STATISTICS IO ON
GO
SELECT ProductId,SalesOrderid FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

如上图所示,只有非聚集索引查找操作,没有键查找(Key lookup)操作了。
参考文章:
索引深入浅出(5/10):非聚集索引的B树结构在堆表的更多相关文章
- 索引深入浅出(3/10):聚集索引的B树结构
在SQL Server里,有2种表是以存储为基础的.有聚集索引的表叫聚集表,没有聚集索引的表叫堆表.在上一篇文章,我们讨论了堆表的特性和存储结构.在这篇文章里,我们来看下聚集表. 有聚集索引的表叫聚集 ...
- SQL Server中的聚集索引(clustered index) 和 非聚集索引 (non-clustered index)
本文转载自 http://blog.csdn.net/ak913/article/details/8026743 面试时经常问到的问题: 1. 什么是聚合索引(clustered index) / ...
- 索引深入浅出(4/10):非聚集索引的B树结构在聚集表
一个表只能有一个聚集索引,数据行以此聚集索引的顺序进行存储,一个表却能有多个非聚集索引.我们已经讨论了聚集索引的结构,这篇我们会看下非聚集索引结构. 非聚集索引的逻辑呈现 简单来说,非聚集索引是表的子 ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自 ...
- 浅谈sql server聚集索引与非聚集索引
今天同事的服务程序在执行批量插入数据操作时,会超时失败,代码debug了几遍一点问题都没有,SQL单条插入也可以正常录入数据,调试了一上午还是很迷茫,场面一度很尴尬,最后还是发现了问题的根本,原来是另 ...
随机推荐
- 设计模式之美:Memento(备忘录)
索引 意图 结构 参与者 适用性 效果 相关模式 实现 实现方式(一):Memento 模式结构样式代码. 别名 Token 意图 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这 ...
- dojo/dom-geometry元素大小
在进入源码分析前,我们先来点基础知识.下面这张图画的是元素的盒式模型,这个没有兼容性问题,有问题的是元素的宽高怎么算.以宽度为例,ff中 元素宽度=content宽度,而在ie中 元素宽度=conte ...
- Android多线程分析之四:MessageQueue的实现
Android多线程分析之四:MessageQueue的实现 罗朝辉 (http://www.cnblogs.com/kesalin/) CC 许可,转载请注明出处 在前面两篇文章<Androi ...
- Android多线程分析之一:使用Thread异步下载图像
Android多线程分析之一:使用Thread异步下载图像 罗朝辉 (http://www.cnblogs.com/kesalin) CC 许可,转载请注明出处 打算整理一下对 Android F ...
- 如何选择前端框架:ANGULAR VS EMBER VS REACT
最近一段时间是令前端工程师们非常兴奋的时期,因为三大Web框架陆续发布新版本,让我们见识到了更强大的Web框架.Ember2.0在2个月之前已经发布,从1.0升级到2.0非常简单.几周之前React发 ...
- 案例研究:CopyToAsync
返回该系列目录<基于Task的异步模式--全面介绍> 把一个流拷贝到另一个流是有用且常见的操作.Stream.CopyTo 方法在.Net 4中就已经加入来满足要求这个功能的场景,例如在一 ...
- EF架构~CodeFirst生产环境的Migrations
回到目录 Migrations即迁移,它是EF的code first模式出现的产物,它意思是说,将代码的变化反映到数据库上,这种反映有两种环境,一是本地开发环境,别一种是服务器的生产环境,本地开发环境 ...
- 3.实现一个名为Person的类和它的子类Employee,Employee有两个子类Faculty 和Staff。
23.实现一个名为Person的类和它的子类Employee,Employee有两个子类Faculty 和Staff. 具体要求如下: (1)Person类中的属性有:姓名name(String类型) ...
- IOS开发之控件篇UICollectionViewControllor第一章 - 普通介绍
1.介绍 UICollectionView和UICollectionViewControllor是IOS6.0后引入的新控件 使用UICollectionView必须实现三个接口: UICollect ...
- java容器详细解析
前言:在java开发中我们肯定会大量的使用集合,在这里我将总结常见的集合类,每个集合类的优点和缺点,以便我们能更好的使用集合.下面我用一幅图来表示 其中淡绿色的表示接口,红色的表示我们经常使用的类. ...